目前最全的 Java 服务问题排查套路
问题分类:
-
CPU问题
-
内存问题(GC问题、内存泄漏、 OOM,Coredump 等)
-
I/O问题
问题排查工具箱:
系统级别的工具:
-
top:查看系统/进程cpu、内存、swap等资源占用情况的必备工具。
-
pmap:可以用来分析进程内部内存分布情况。
-
strace:用来跟踪进程执行时的系统调用和所接收的信号,比如可以用来追踪进程向系统申请内存资源等。
-
gperftools:一个性能分析工具,可以用于内存泄漏、cpu性能检测等。
-
gdb:基于命令行的、功能强大的程序调试工具,是c/c++开发的必备工具(JVM底层就是用c实现的)。
-
iostat:用来动态监视系统的磁盘操作活动。
-
iotop:界面类似于top, 但是监视Linux的磁盘I / O的使用细节。
-
vmstat:可实时动态监视操作系统的虚拟内存、进程、CPU活动。
-
netstat: 各种网络相关信息,如网络连接,路由表,接口状态 。
-
dstat: 可以取代vmstat,iostat,netstat和ifstat这些命令的多功能产品。
Java层面的命令:
-
Jps:查看Java进程。
-
Jstat: JVM统计信息监控。
-
Jinfo:查看运行中的Java程序的运行环境参数。
-
Jstack:查看 JVM中当前所有线程的运行情况和线程当前状态。
-
Jcmd:它是一个多功能的工具,可以用它来导出堆、查看Java进程、导出线程信息、执行GC、还可以进行采样分析等。
-
Jmap:查看JVM进程的的堆内内存占用情况,是堆内内存定位神器,往往和MAT配合使用。
-
VJmap:唯品会开发的工具,分代版的jmap,但仅仅适用于CMS GC。
-
Btrace:可以在不重启服务时,动态追踪程序运营细节的工具。
-
Arthas:功能非常强大的Java诊断工具;可以做到动态跟踪代码、实时监控JVM状态等功能。
-
MAT(Memory Analyzer):JVM内存、线程分析工具,能够对给出内存分析报告。
-
GCLogViewer:GC log趋势分析工具,能够检测内存泄露及日志比较。
-
JProfiler:Java性能瓶颈分析工具,分析 CPU,Thread,Memory功能尤其强大,是做性能优化的必备工具。
常见问题分析步骤:
CPU问题:
排查思路:一般情况下可以直接使用top命令,查看cpu负载是否很高,并且找出cpu占用量最高的进程(假设是Java进程);然后使用“top -H -p pid”,去找到哪些线程占用量最高,最后使用jstack去查看占用量最高线程。另外我们还可以根据是内核态消耗cpu太高还是用户态消耗cpu太高;要是内核态需要关注cpu切换、锁、io等,如果是用户态则需要关注计算、循环、GC等问题。
例子: CPU上下文切换导致服务雪崩 。
内存问题:
coredump:
排查思路:一般情况下,进程coredump的时候都会留下coredump文件,coredump文件的存储位置配置在/proc/sys/kernel/core_pattern文件下。并且jvm本身也会生成一个crash报告文件,该文件的可以大概的反映出一个当时的情况,但是coredump文件能获取的信息更多。可以使用gdb工具来进行调试coredump文件,找到具体原因。
例子: 如何定位Java程序coredump的位置
OOM(out of memory):
oom就是内存不足,jvm中内存不足有以下三种:
-
Exception in thread "main" java.lang.OutOfMemoryError: unable to create new native thread---没有足够的内存空间为该线程分配java栈。
解决办法:很多资料说可以通过调整Xss参数可解决问题,事实上系统采用的延迟分配,所有系统并不会给每个线程都分配Xss的真实内存,是按需分配的。
出现这种情况至少95%情况是因为使用线程池(ExecutorService),忘记调用shutdown了,还有少部分情况可能是系统参数配置有问题,比如 max_threads、 max_user_processes过小。
-
Exception in thread "main" java.lang.OutOfMemoryError: Java heap space---堆的内存占用已经达到-Xmx设置的最大值。
解决办法:调整-Xmx的值,或者存在内存泄漏,按照内存泄漏的思路查找。
-
Caused by: java.lang.OutOfMemoryError: PermGen space---方法区的内存占用已经达到-XX:MaxPermSize设置的最大值。
解决办法:调整-XX:MaxPermSize的值。
StackOverflow:
-
Exception in thread "main" java.lang.StackOverflowError --- 线程栈需要的内存大于Xss值。
解决办法:调整 Xss 的值。
堆内内存泄漏:
-
查看gc情况是否正常,堆内内存泄漏总是和gc异常相伴随的。
-
jmap -dump:live,file=mem.map pid把内存dump下来。
-
通过mat(memory analyzer)分析内存对象及调用链,发现无法回收的对象。
堆外内存泄漏:
思路:堆外内存一般分为使用unsafe或者ByteBuffer申请的和使用native方式申请的。比如对于 unsafe典型应用场景就是Netty,而对于native方式典型应用场景是解压包(ZipFile),笔者遇到的堆外内存泄漏90%都跟这两者相关,当然还有其他情况,比如直接使用 JavaCPP申请堆外内存(底层就是native方式)。对于堆外内存泄漏一般gperftools+btrace这组组合工具基本上都能搞定,如果不行的话,可能就需要系统底层工具了,比如 strace等。
另外,虽然堆外内存不属于堆内,但是其引用在堆内;有时候在直接查看堆外不方便或者没有结论时,可以查看堆内是否有异常对象。
例子: spring boot 引起的 “堆外内存泄漏”
GC问题排查:
-
young gc单次时间太长
排查思路:根据gc log(G1),查看耗时是在Root Scanning、Object Copy、Ref Proc等哪 个阶段。如果Ref Proc耗时久,则需要关注引用相关的对象;如果Root Scanning耗时久,则需要关注线程数、跨代引用等。Object Copy则需要关注对象生存周期(可以使用VJmap工具)。
例子:线上把两个服务合并成一个服务之后,发现上游服务超时变多,服务整体可用性降低。通过查看监控发现young gc时间变高很多,young gc日志如下:
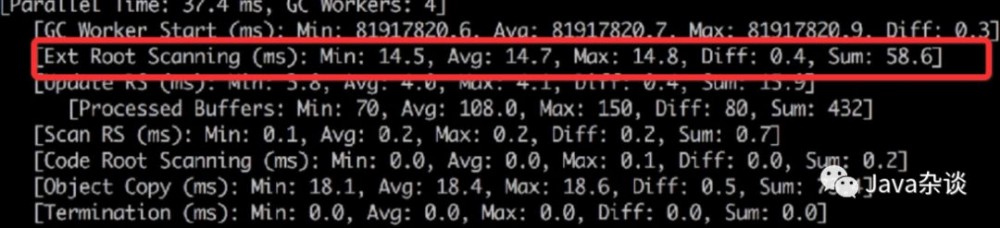
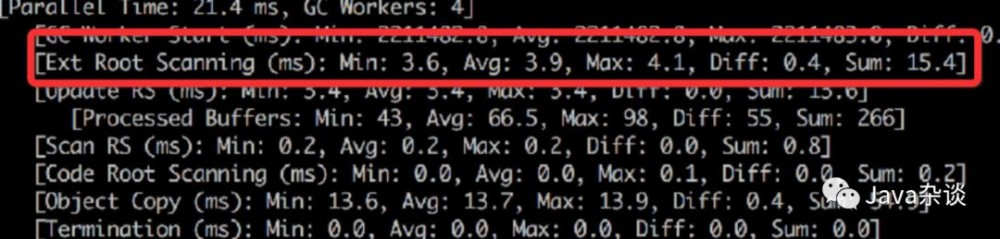
和其他项目对比,发现Root Scanning的时间较高,查看项目监控发现线程数太多,高达4000多个。于是通过Hystrix信号量+RPC异步化去改造项目,把线程数目降低到800左右。young gc的平均时间由37降低到了21毫秒,达到预期。
-
young gc频率太高
排查思路:查看-Xmn、-XX:SurvivorRatio等参数设置是否合理,能否通过调整jvm参数到达目的;如果参数正常,但是young gc频率还是太高,需要使用Jmap/MAT等工具参看业务代码是否生成的对象是否合理。
例子:有一次在项目接入部分用户全链路日志的时候,发现young gc频率飙升了很多。使用Jmap发现JSON对象,发现相关的代码如下:
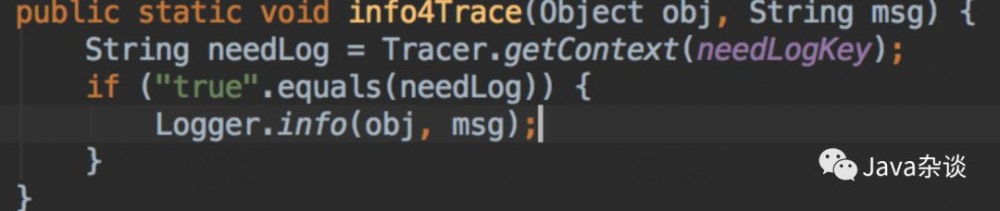
从代码中我们可以看出,不管是否需要输入全链路日志都会生成JSON对象,很明显不符合预期。
-
full gc单次时间太长
排查思路: 查看old的区域配置是否过大,过大可以适当调小一些。如果是cms,可以查看是在Inital mark阶段时间太久Re mark阶段,如果是 Re mark阶段 可以添加-XX:+CMSScavengeBeforeRemark参数。如果服务太在意full gc时间,可以采用主动full gc的方式,具体的实现原理可以参考: 谈谈项目中主动full gc的一些问题 。
-
full gc频率太高
排查思路:这种情况应该是java最常遇到,也是情况最为复杂的。其实主要思路还是首先要看出发full/major gc的原因,比如对于cms gc,一般情况下发生的条件,就是perm或者old到达阈值。如果是old区域主要还是要看为什么对象会那么快晋升到老年代。如果配置的是cms,发生的确实full gc,就需要查看满足哪种条件的full gc,找出具体的原因。
例子: Redis client链接池配置不当引起的频繁full gc 、 一个诡异的full gc查找问题 、 Full GC问题排查案例
IO问题:
排查思路:直接使用 iotop能够直接查看哪些线程在做IO,然后在用jstack去定位具体的代码。
问题排查的方法论
一般Java服务发生问题可能伴随着多种现象,比如:cpu飙升、gc飙升等问题,这时候我们必须要遵循 “ 现象-问题-原因-方案 ”这个步骤去解决问题。
-
列举所有异常现象。比如:服务响应时间飙升、cpu飙升、full gc飙升;
-
列举所有的问题。步骤一 中所有的异常现象不一定都有问题,比如现象A导致了现象B,那么我们应该现象A是问题,现象B是结果,不是我们问题查找的主力方向。
-
查找原因。步骤二中的问题,有难易程度,比如cpu飙升就比full gc飙升问题容易排查。所以这步中我们先按照从易到难的程度排查。
-
原因确定之后,就可以给出具体解决方案,然后验证它。
例子: 服务响应时间飙升问题排查记
正文到此结束
- 本文标签: db 进程 Netty 开发 jstack IO Full GC cmd 线程 NSA 操作系统 http executor JVM root swap redis 参数 运营 Service 生存周期 zip 调试 json 统计 线程池 性能优化 java js UI Android core IOS Hystrix spring https 配置 空间 src 神器 Spring Boot linux ip map 时间 client ACE id cpu负载 产品 代码 锁 strace 虚拟内存
- 版权声明: 本文为互联网转载文章,出处已在文章中说明(部分除外)。如果侵权,请联系本站长删除,谢谢。
- 本文海报: 生成海报一 生成海报二
热门推荐










相关文章

近期评论
-
你这基本没有更新呀,最近文章显示还是2019年的文章。不符合要求哈
-
关键词:慕云博客 链接:https://www.lilun.me 描述:分享原创文字的个人博客
-
-
-
可以提供一下源码吗
-
不是商业站,鸡娃学习笔记
-
-
-
-
听他们说很厉害的样子
Loading...
![[HBLOG]公众号](http://www.liuhaihua.cn/img/qrcode_gzh.jpg)

