由Spring应用的瑕疵谈谈DDD的概念与应用(二)
在上一篇文章中,通过Spring Web应用的瑕疵引出改善的措施,我们讲解了领域驱动开发的相关概念和设计策略。本文主要讲解领域模型的几种类型和DDD的简单实践案例。
架构风格
在《实现领域驱动设计》一书中提到了几种架构风格:六边形架构、REST架构、CQRS 和事件驱动等。在实际使用中,落地的架构并非是纯粹其中的一种,而很有可能户将上述几种架构风格结合起来实现。
分层架构
分层架构的一个重要原则是每层只能与位于其下方的层发生耦合。分层架构可以简单分为两种,即严格分层架构和松散分层架构。在严格分层架构中,某层只能与位于其直接下方的层发生耦合,而在松散分层架构中,则允许某层与它的任意下方层发生耦合。DDD分层架构中比较经典的三种模式:四层架构、五层架构和六边形架构。
四层架构
Eric Evans在《领域驱动设计-软件核心复杂性应对之道》这本书中提出了传统的四层架构模式:
- User Interface为用户界面层(或表示层),负责向用户显示信息和解释用户命令。这里指的用户可以是另一个计算机系统,不一定是使用用户界面的人。
- Application为应用层,定义软件要完成的任务,并且指挥表达领域概念的对象来解决问题。这一层所负责的工作对业务来说意义重大,也是与其它系统的应用层进行交互的必要渠道。应用层要尽量简单,不包含业务规则或者知识,而只为下一层中的领域对象协调任务,分配工作,使它们互相协作。它没有反映业务情况的状态,但是却可以具有另外一种状态,为用户或程序显示某个任务的进度。
- Domain为领域层(或模型层),负责表达业务概念,业务状态信息以及业务规则。尽管保存业务状态的技术细节是由基础设施层实现的,但是反映业务情况的状态是由本层控制并且使用的。领域层是业务软件的核心,领域模型位于这一层。
- Infrastructure层为基础实施层,向其他层提供通用的技术能力:为应用层传递消息,为领域层提供持久化机制,为用户界面层绘制屏幕组件,等等。基础设施层还能够通过架构框架来支持四个层次间的交互模式。
传统的四层架构都是限定型松散分层架构,即Infrastructure层的任意上层都可以访问该层(“L”型),而其它层遵守严格分层架构。
五层架构
五层架构是根据《DCI架构:面向对象编程的新构想》中提及的DCI架构模式总结而成。DCI架构(Data、Context和Interactive三层架构):
- Data层描述系统有哪些领域概念及其之间的关系,该层专注于领域对象的确立和这些对象的生命周期管理及关系,让程序员站在对象的角度思考系统,从而让“系统是什么”更容易被理解。
- Context层:是尽可能薄的一层。Context往往被实现得无状态,只是找到合适的role,让role交互起来完成业务逻辑即可。但是简单并不代表不重要,显示化context层正是为人去理解软件业务流程提供切入点和主线。
- Interactive层主要体现在对role的建模,role是每个context中复杂的业务逻辑的真正执行者,体现“系统做什么”。role所做的是对行为进行建模,它联接了context和领域对象。由于系统的行为是复杂且多变的,role使得系统将稳定的领域模型层和多变的系统行为层进行了分离,由role专注于对系统行为进行建模。该层往往关注于系统的可扩展性,更加贴近于软件工程实践,在面向对象中更多的是以类的视角进行思考设计。
DCI目前广泛被看作是对DDD的一种发展和补充,用在基于面向对象的领域建模上。五层架构的具体定义如下:
- User Interface是用户接口层,主要用于处理用户发送的Restful请求和解析用户输入的配置文件等,并将信息传递给Application层的接口。
- Application层是应用层,负责多进程管理及调度、多线程管理及调度、多协程调度和维护业务实例的状态模型。当调度层收到用户接口层的请求后,委托Context层与本次业务相关的上下文进行处理。
- Context是环境层,以上下文为单位,将Domain层的领域对象cast成合适的role,让role交互起来完成业务逻辑。
- Domain层是领域层,定义领域模型,不仅包括领域对象及其之间关系的建模,还包括对象的角色role的显式建模。
- Infrastructure层是基础实施层,为其他层提供通用的技术能力:业务平台,编程框架,持久化机制,消息机制,第三方库的封装,通用算法,等等。
六边形架构
六边形架构(Hexagonal Architecture),又称为端口和适配器风格,最早由 Alistair Cockburn 提出。在 DDD 社区得到了发展和推广,之所以是六变形是为了突显这是个扁平的架构,每个边界的权重是相等的。
我们知道,经典分层架构分为三层(展现层、应用层、数据访问层),而对于六边形架构,可以分成另外的三层:
- 领域层(Domain Layer):最里面,纯粹的核心业务逻辑,一般不包含任何技术实现或引用。
- 端口层(Ports Layer):领域层之外,负责接收与用例相关的所有请求,这些请求负责在领域层中协调工作。端口层在端口内部作为领域层的边界,在端口外部则扮演了外部实体的角色。
- 适配器层(Adapters Layer):端口层之外,负责以某种格式接收输入、及产生输出。比如,对于 HTTP 用户请求,适配器会将转换为对领域层的调用,并将领域层传回的响应进行封送,通过 HTTP 传回调用客户端。在适配器层不存在领域逻辑,它的唯一职责就是在外部世界与领域层之间进行技术性的转换。适配器能够与端口的某个协议相关联并使用该端口,多个适配器可以使用同一个端口,在切换到某种新的用户界面时,可以让新界面与老界面同时使用相同的端口。
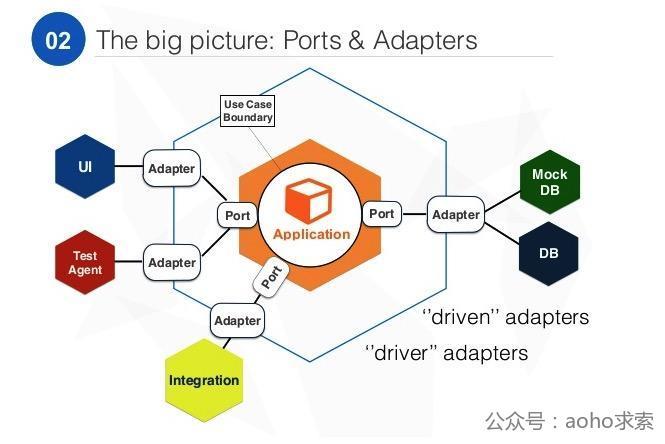
这样做的好处是将使业务边界更加清晰,从而获得更好的扩展性,除此之外,业务复杂度和技术复杂度分离,是 DDD 的重要基础,核心的领域层可以专注在业务逻辑而不用理会技术依赖,外部接口在被消费者调用的时候也不用去关心业务内部是如何实现。
REST架构
RESTful风格的架构将 资源 放在第一位,每个 资源 都有一个 URI 与之对应,可以将 资源 看着是 DDD 中的实体;RESTful 采用具有自描述功能的消息实现无状态通信,提高系统的可用性;至于 资源 的哪些属性可以公开出去,针对 资源 的操作,RESTful使用HTTP协议的已有方法来实现:GET、PUT、POST和DELETE。
在 DDD 的实现中,我们可以将对外的服务设计为 RESTful 风格的服务,将实体/值对象/领域服务作为 资源 对外提供增删改查服务。但是并不建议直接将实体暴露在外,一来实体的某些隐私属性并不能对外暴露,二来某些资源获取场景并不是一个实体就能满足。因此我们在实际实践过程中,在领域模型上增加了 DTO 这样一个角色,DTO 可以组合多个实体/值对象的资源对外暴露。
CQRS
CQRS 就是平常大家在讲的读写分离,通常读写分离的目的是为了提高查询性能,同时达到读/写的解耦。让 DDD 和 CQRS 结合,我们可以分别对读和写建模,查询模型通常是一种非规范化数据模型,它并不反映领域行为,只是用于数据显示;命令模型执行领域行为,且在领域行为执行完成后,想办法通知到查询模型。
那么命令模型如何通知到查询模型呢? 如果查询模型和领域模型共享数据源,则可以省却这一步;如果没有共用数据源,则可以借助于 消息模式 (Messaging Patterns)通知到查询模型,从而达到最终一致性(Eventual Consistency)。
Martin 在 blog 中指出:CQRS 适用于极少数复杂的业务领域,如果不是很适合反而会增加复杂度;另一个适用场景为获取高性能的服务。
领域模型
在上面小节讲解了领域驱动设计的几种架构风格,下面我们具体结合简单的实例来看其中的领域模型划分,初步分为4大类:
- 失血模型
- 贫血模型
- 充血模型
- 胀血模型
我们看看这些领域模型的具体内容,以及他们的优缺点。
失血模型
失血模型简单来说,就是domain object只有属性的getter/setter方法的纯数据类,所有的业务逻辑完全由business object来完成(又称TransactionScript),这种模型下的domain object被Martin Fowler称之为“贫血的domain object”。如下:
-
一个实体类叫做Item
public class Item implements Serializable { private Long id = null; private int version; private String name; private User seller; // ... // getter/setter方法省略不写,避免篇幅太长 复制代码
}
```
-
一个DAO接口类叫做ItemDao
public interface ItemDao { public Item getItemById(Long id); public Collection findAll(); public void updateItem(Item item); 复制代码
} ```
-
一个DAO接口实现类叫做ItemDaoHibernateImpl
public class ItemDaoImpl implements ItemDao extends DaoSupport { public Item getItemById(Long id) { return (Item) getHibernateTemplate().load(Item.class, id); } public Collection findAll() { return (List) getHibernateTemplate().find("from Item"); } public void updateItem(Item item) { getHibernateTemplate().update(item); } 复制代码
} ```
-
一个业务逻辑类叫做ItemManager(或者叫做ItemService)
复制代码
public class ItemManager {
private ItemDao itemDao;
public void setItemDao(ItemDao itemDao) { this.itemDao = itemDao;}
public Bid loadItemById(Long id) {
itemDao.loadItemById(id);
}
public Collection listAllItems() {
return itemDao.findAll();
}
public Bid placeBid(Item item, User bidder, MonetaryAmount bidAmount,
Bid currentMaxBid, Bid currentMinBid) throws BusinessException {
if (currentMaxBid != null && currentMaxBid.getAmount().compareTo(bidAmount) > 0) {
throw new BusinessException("Bid too low.");
}
// ... 复制代码
} ```
以上是一个完整的失血模型的示例代码。在这个示例中,loadItemById、findAll 等等业务逻辑统统放在 ItemManager 中实现,而 Item 只有 getter/setter 方法。
贫血模型
简单来说,就是 domain ojbect 包含了不依赖于持久化的领域逻辑,而那些依赖持久化的领域逻辑被分离到 Service 层。
Service(业务逻辑,事务封装) --> DAO ---> domain object
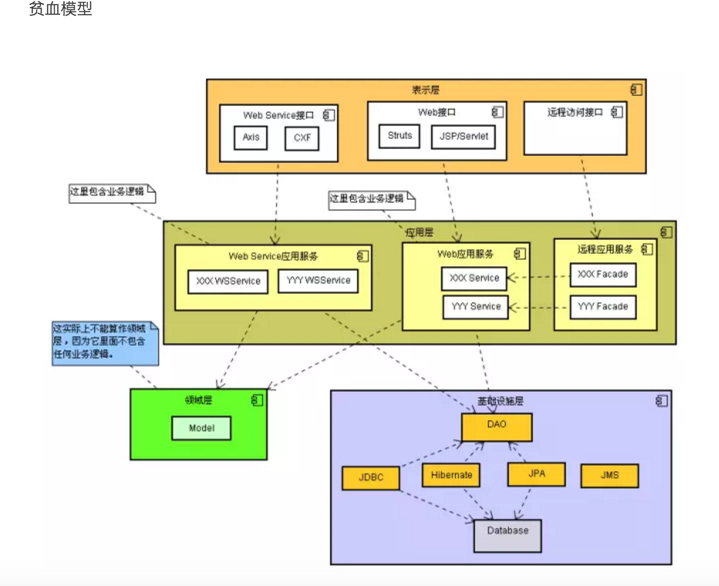
这也就是 Martin Fowler 指的 rich domain object:
- 一个带有业务逻辑的实体类,即domain object是Item
- 一个DAO接口ItemDao
- 一个DAO实现ItemDaoHibernateImpl
- 一个业务逻辑对象ItemManager
这种模型的优点:
- 各层单向依赖,结构清楚,易于实现和维护
- 设计简单易行,底层模型非常稳定
缺点为:
- domain object的部分比较紧密依赖的持久化 domain logic 被分离到Service层,显得不够 OO
- Service 层过于厚重
具体代码较为简单,不再展示。
充血模型
充血模型和第二种模型差不多,所不同的就是如何划分业务逻辑,即认为,绝大多业务逻辑都应该被放在domain object里面(包括持久化逻辑),而Service层应该是很薄的一层,仅仅封装事务和少量逻辑,不和DAO层打交道。
Service(事务封装) ---> domain object <---> DAO
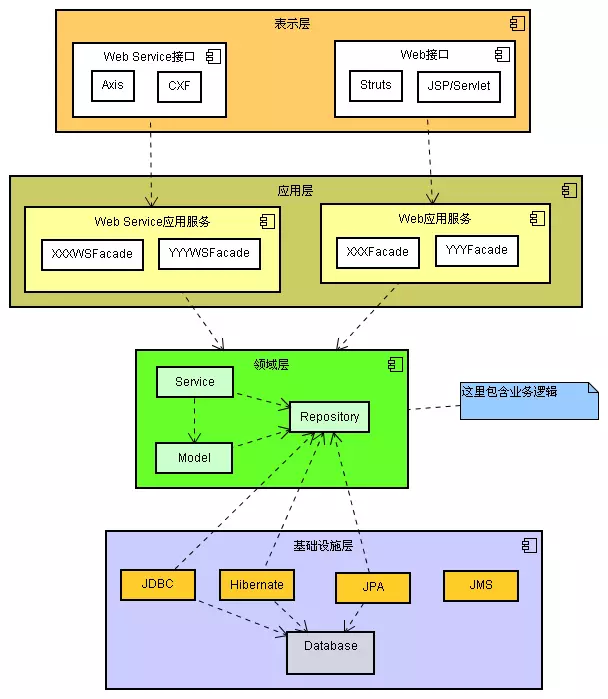
这种模型就是把第二种模型的 domain object 和 business object 合二为一了。所以 ItemManager 就不需要了,在这种模型下面,只有三个类,他们分别是:
- Item:包含了实体类信息,也包含了所有的业务逻辑
- ItemDao:持久化DAO接口类
- ItemDaoHibernateImpl:DAO接口的实现类
在这种模型中,所有的业务逻辑全部都在Item中,事务管理也在Item中实现。 这种模型的优点:
- 更加符合OO的原则
- Service层很薄,只充当Facade的角色,不和DAO打交道。
这种模型的缺点:
- DAO和domain object形成了双向依赖,复杂的双向依赖会导致很多潜在的问题。
- 如何划分Service层逻辑和domain层逻辑是非常含混的,在实际项目中,由于设计和开发人员的水平差异,可能导致整个结构的混乱无序。
- 考虑到Service层的事务封装特性,Service层必须对所有的domain object的逻辑提供相应的事务封装方法,其结果就是Service完全重定义一遍所有的domain logic,非常烦琐,而且 Service 的事务化封装其意义就等于把 OO 的domain logic 转换为过程的 Service TransactionScript。
胀血模型
基于充血模型的第三个缺点,有同学提出,干脆取消Service层,只剩下domain object和DAO两层,在domain object的domain logic上面封装事务。
domain object(事务封装,业务逻辑) <---> DAO
似乎ruby on rails就是这种模型,他甚至把 domain object 和 DAO 都合并了。
该模型优点:
- 简化了分层
- 也算符合OO
该模型缺点:
- 很多不是domain logic的 service 逻辑也被强行放入 domain object,引起了domain ojbect模型的不稳定
- domain object 暴露给web层过多的信息,可能引起意想不到的副作用。
小结
在这四种模型当中,失血模型和胀血模型应该是不被提倡的。而贫血模型和充血模型从技术上来说,都已经是可行的了。贫血模型和充血模型哪个更加好一些?人们针对这个问题进行了旷日持久的争论,最后仍然没有什么结果。双方争论的焦点主要在我上面加粗的两句话上,就是领域模型是否要依赖持久层,因为依赖持久层就意味着单元测试的展开要更加困难(无法脱离框架进行测试,原文的讨论中这里专指Hibernate),领域层就更难独立,将来也更难从应用程序中剥离出来,当然好处是业务逻辑不必混放在不同的层中,使得单一职责性体现的更好。而支持者(充血模型)认为,只要将持久层抽象出来,即可减少测试的困难性,同时适用充血模型毕竟带来了不少开发上的便利性,除了依赖持久层这一点,拥有更多好处的充血模型仍然值得选择。最后,谁也没能说服谁,关于贫血模型和充血模型的选择,更多的要靠具体的业务场景来决定,并不能说哪一种更比哪一种好。设计模式这种东西不是向来都没有什么定论么。
我个人则倾向使用充血模型,因为充血模型更加像一个设计完善的系统架构,好在计算机世界里有很多的 IOC 和 DI 框架,唯一的缺陷依赖持久层可以通过各种变通的方法绕过,随着技术的进步,一些缺陷也会被慢慢解决。我的思路是这样的:先将持久层抽象为接口,然后通过服务层将持久层注入到领域模型中,这样领域模型仅仅会依赖于持久层的接口。而这个接口,可以利用现有框架的技术进行抽象。
正文到此结束
- 本文标签: 系统架构 设计模式 REST 数据模型 Collection zab spring https 配置 代码 软件 ACE IO 适配器 struct cat 多线程 list 生命 图片 bus ip 进程 RESTful 实例 http ioc 专注 端口 线程 管理 DOM 推广 Service 一致性 测试 NSA 解析 src Action 模型 协议 find 数据 程序员 总结 文章 id web tar UI App 开发 Architect HTTP协议 单元测试 update
- 版权声明: 本文为互联网转载文章,出处已在文章中说明(部分除外)。如果侵权,请联系本站长删除,谢谢。
- 本文海报: 生成海报一 生成海报二
热门推荐










相关文章

近期评论
-
你这基本没有更新呀,最近文章显示还是2019年的文章。不符合要求哈
-
关键词:慕云博客 链接:https://www.lilun.me 描述:分享原创文字的个人博客
-
-
-
可以提供一下源码吗
-
不是商业站,鸡娃学习笔记
-
-
-
-
听他们说很厉害的样子
Loading...
![[HBLOG]公众号](http://www.liuhaihua.cn/img/qrcode_gzh.jpg)

