Java并发 -- 问题源头
- 核心矛盾:三者的 速度差异
- 为了合理利用CPU的高性能,平衡三者的速度差异,计算机体系结构、操作系统和编译程序都做出了贡献
- 计算机体系结构:CPU增加了 缓存 、以均衡 CPU与内存 的速度差异
- 操作系统:增加了 进程、线程 ,分时复用CPU,以平衡 CPU和IO设备 的速度差异
- 编译程序:优化 指令执行次序 ,使得缓存能够得到更加合理地利用
CPU缓存 -> 可见性问题
单核
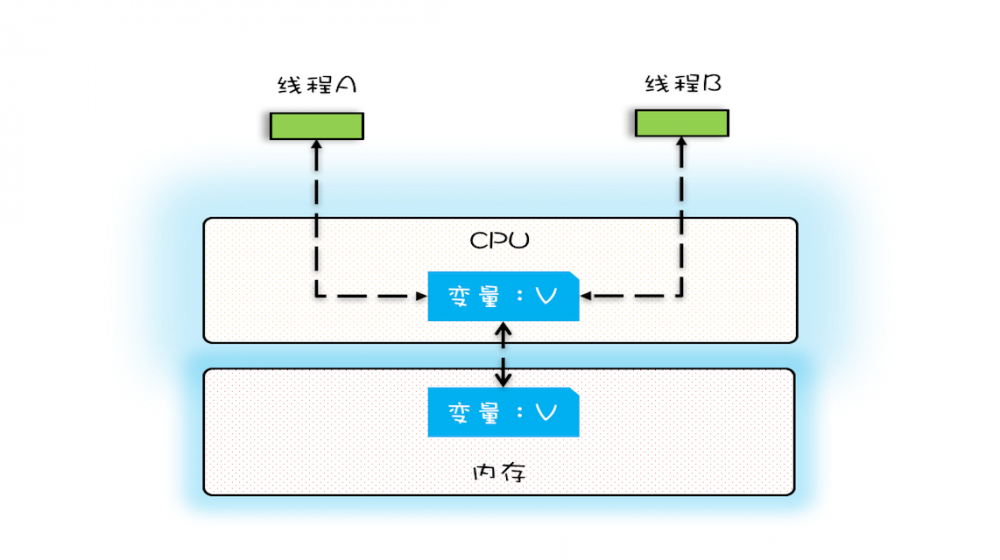
- 在单核时代,所有的线程都在一颗CPU上执行,CPU缓存与内存的 数据一致性 很容易解决
- 因为所有线程操作的都是同一个CPU的缓存,一个线程对CPU缓存的写,对另外一个线程来说一定是 可见 的
- 可见性 :一个线程对 共享变量 的修改,另一个线程能够 立即看到
多核
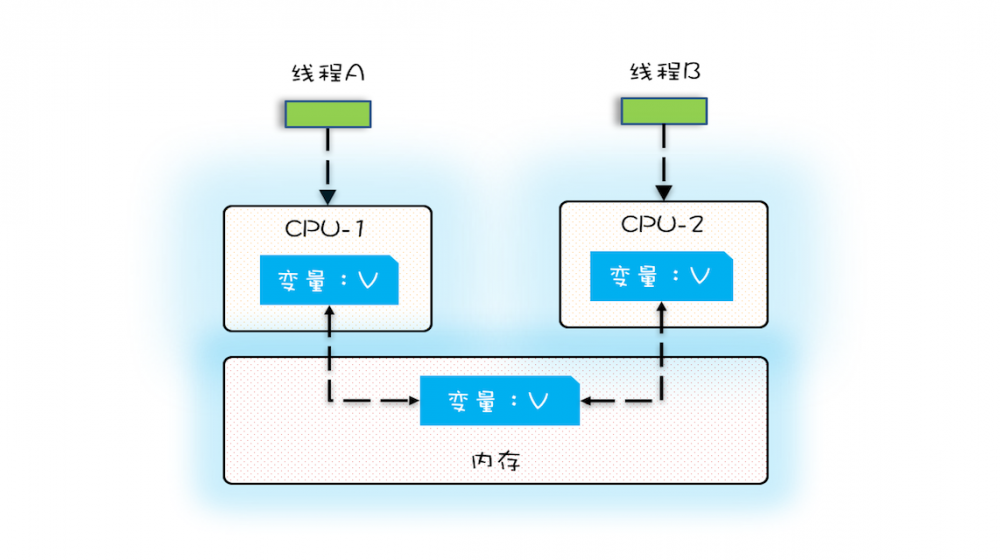
- 在多核时代,每颗CPU都有自己的缓存,此时CPU缓存与内存的 数据一致性 就没那么容易解决了
- 当多个线程在不同的CPU上执行时,操作的是不同的CPU缓存
- 线程A操作的是CPU-1上的缓存,线程B操作的是CPU-2上的缓存,此时线程A对变量V的操作对于线程B而言 不具备可见性
代码验证
public class VisibilityTest {
private static final long MAX = 100_000_000;
private long count = 0;
private void add() {
int idx = 0;
while (idx++ < MAX) {
count += 1;
}
}
@Test
public void calc() throws InterruptedException {
// 创建两个线程,执行 add() 操作
Thread t1 = new Thread(this::add);
Thread t2 = new Thread(this::add);
// 启动两个线程
t1.start();
t2.start();
// 等待两个线程执行结束
t1.join();
t2.join();
// count=100_004_429 ≈ 100_000_000
System.out.println("count=" + count);
}
}
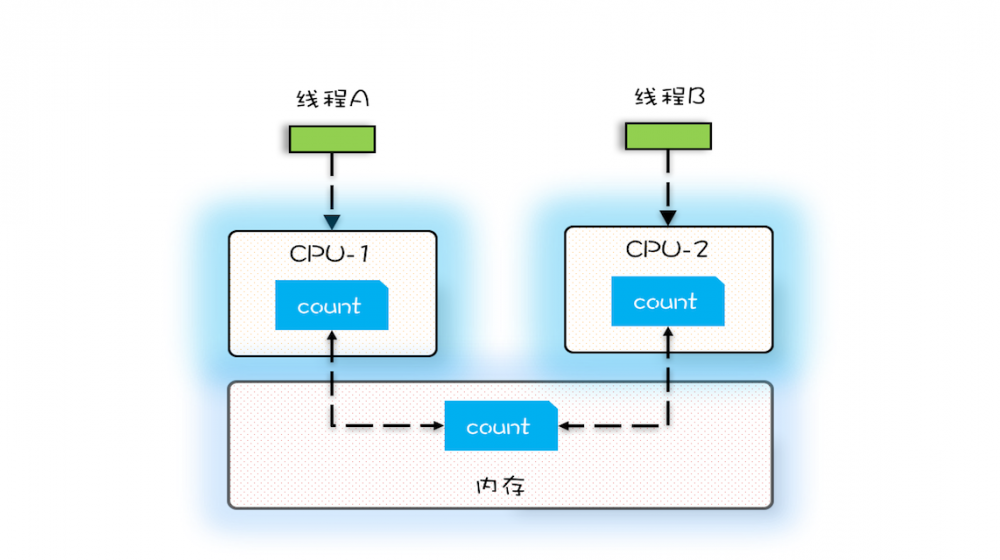
- 假设线程A和线程B同时开始执行,那么第一次都会将count=0读到各自的CPU缓存中
- 之后由于各自的CPU缓存里都有了count的值,两个线程都是 基于CPU缓存里的count值来进行计算 的
- 所以导致最终count的值小于2*MAX,这就是 CPU缓存导致的可见性问题
线程切换 -> 原子性问题
分时复用
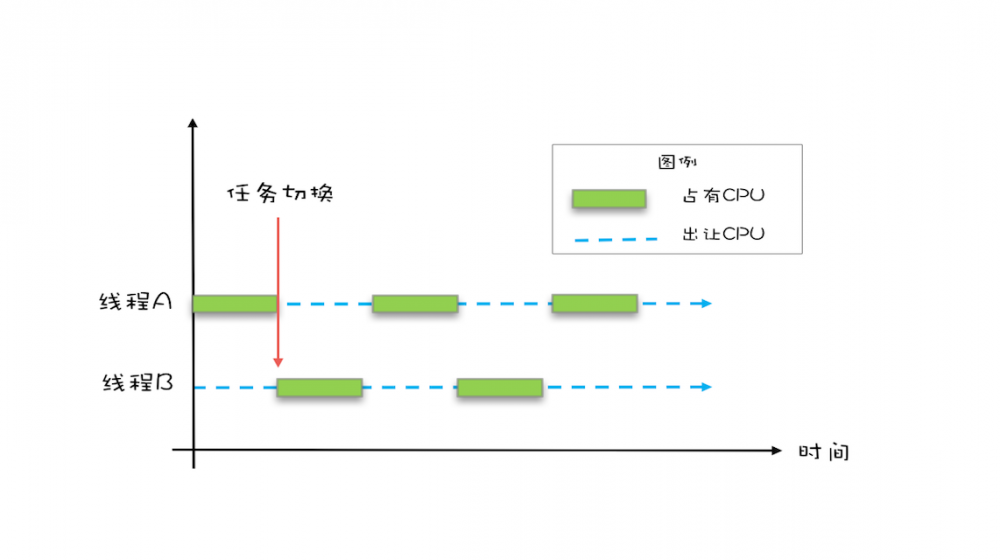
- 由于 IO太慢 ,早期的操作系统发明了 多进程 ,并支持 分时复用 (时间片)
- 在一个时间片内,如果进程进行一个IO操作,例如读文件,该进程可以把自己标记为 休眠状态 并让出CPU的使用权
- 待文件读进内存后,操作系统会把这个休眠的进程 唤醒 ,唤醒后的进程就有机会重新获得CPU的使用权了
- 进程在等待IO时释放CPU的使用权,可以让CPU在这段等待时间里执行其他任务, 提高CPU的使用率
- 另外,如果此时另外一个进程也在读文件,而读文件的操作会先 排队
- 磁盘驱动在完成一个进程的读操作后,发现有其他任务在排队,会立即启动下一个读操作, 提高磁盘IO的使用率
线程切换
- 早期的操作系统基于进程来调度CPU, 不同进程间是不共享内存空间的 ,进程切换需要 切换内存映射地址
- 一个进程创建的所有线程,都是 共享 同一个内存空间的,因此线程切换的成本很低
- 现代的操作系统都是基于更轻量的线程来调度的,而Java并发程序都是基于 多线程 的
count+=1
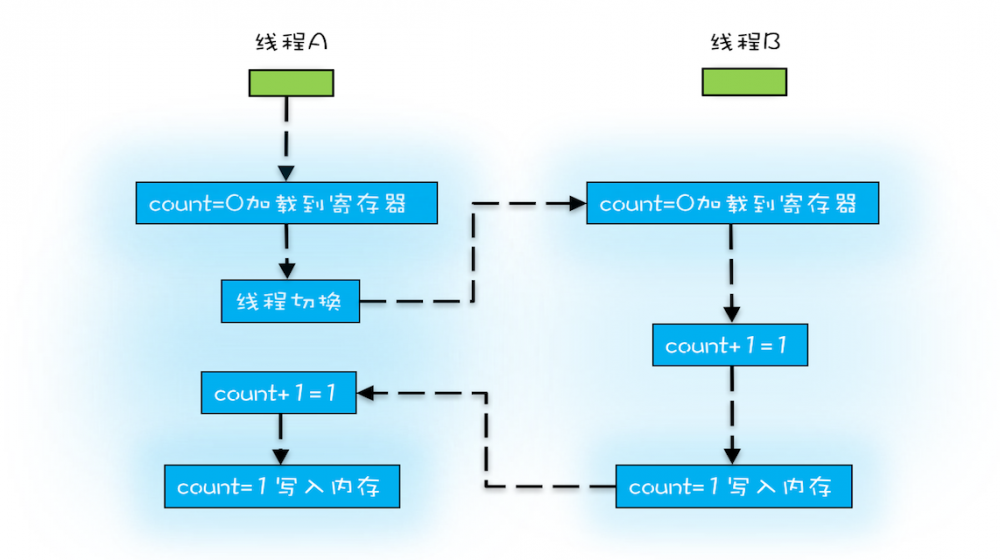
- 线程切换的时机大多在 时间片结束 的时候,而高级语言里的一条语句往往需要 多条CPU指令 完成,如
count+=1- 把变量count从内存加载到CPU的寄存器
- 在寄存器中执行+1操作
- 将结果写入 CPU缓存 (最终会回写到内存)
- 操作系统做线程切换,可以发生在任何一条 CPU指令 (而非高级语言的语句)执行完
- 按照上图执行,线程A和线程B都执行了
count+=1,但得到的结果却是1,而不是2,因为Java中的+1操作 不具有原子性 - 原子性 :一个或多个操作在CPU执行的过程中 不被中断 的特性
- CPU能保证的原子操作是 CPU指令级别 的,而不是高级语言的操作符
编译优化 -> 有序性问题
- 有序性 :程序按照代码的先后顺序执行
- 编译器为了优化性能,有时会改变程序中语句的先后顺序
双重检查
class Singleton {
private static Singleton instance;
// 双重检查
public static Singleton getInstance() {
if (instance == null) {
synchronized (Singleton.class) {
if (instance == null)
instance = new Singleton();
}
}
return instance;
}
}
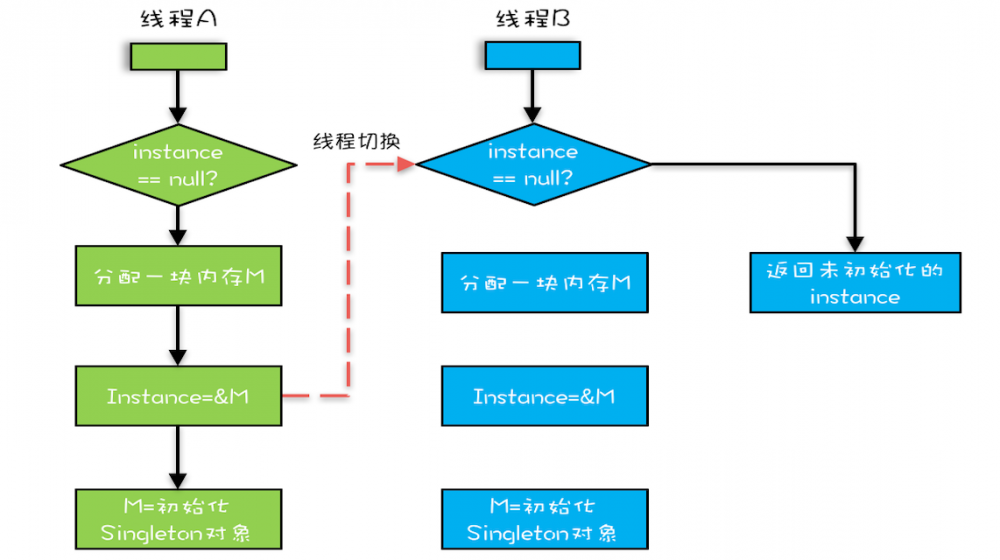
- 直觉
- 线程A和B同时调用getInstance()方法,同时发现instance==null,同时对Singleton.class加锁
- 此时JVM保证只有一个线程能够加锁成功(假设是线程A),另一个线程则会进入等待状态(假设线程B)
- 线程A会创建一个Singleton实例,然后释放锁,线程B被唤醒并再次尝试加锁,此时加锁成功
- 线程B检查instance==null,发现已经创建过Singleton实例了,不会再创建Singleton实例了
- 直觉上的new操作
- 分配一块内存M
- 在内存M上初始化Singleton对象
- 将M的地址赋值给instance变量
- 编译器优化后的new操作可能是
- 分配一块内存M
- 将M的地址赋值给instance变量
- 在内存M上初始化Singleton对象
- 因此,实际情况可能是
- 假设线程A先执行getInstance()方法,当执行完指令2时恰好发生了 线程切换 ,切换到线程B
- 线程B也在执行getInstance()方法,线程B会执行第一个判断,发现instance!=null,直接返回instance
- 但此时返回的instance是 没有初始化过 的,如果此时访问instance的成员变量就有可能触发 空指针异常
小结
- CPU缓存 -> 可见性问题,线程切换 -> 原子性问题,编译优化 -> 有序性问题
- CPU缓存、线程和编译优化的目的与并发程序的目一致,都是为了 提高程序性能
- 但技术在解决一个问题的同时,必然会带来另一个问题,因此需要权衡
转载请注明出处:http://zhongmingmao.me/2019/04/15/java-concurrent-bug-source/
访问原文「Java并发 -- 问题源头」获取最佳阅读体验并参与讨论
正文到此结束
热门推荐










相关文章

近期评论
-
Your article is a perfect article without a hitch. Thank you. My site: horse racing betting game
-
-
你这基本没有更新呀,最近文章显示还是2019年的文章。不符合要求哈
-
关键词:慕云博客 链接:https://www.lilun.me 描述:分享原创文字的个人博客
-
-
-
可以提供一下源码吗
-
不是商业站,鸡娃学习笔记
-
-
Loading...
![[HBLOG]公众号](http://www.liuhaihua.cn/img/qrcode_gzh.jpg)

