前百度面试官整理的——Java后端面试题(一)

List 和 Set 的区别
List , Set 都是继承自 Collection 接口 List 特点:元素有放入顺序,元素可重复 ,
Set 特点:元素无放入顺序,元素不可重复,重复元素会覆盖掉,(元素虽然无放入顺序,但是元素在set中的位 置是有该元素的 HashCode 决定的,其位置其实是固定的,加入Set 的 Object 必须定义 equals ()方法 ,另外list 支持for循环,也就是通过下标来遍历,也可以用迭代器,但是set只能用迭代,因为他无序,无法用下标来取得想 要的值。) Set和List对比 Set:检索元素效率低下,删除和插入效率高,插入和删除不会引起元素位置改变。
List:和数组类似,List可以动态增长,查找元素效率高,插入删除元素效率低,因为会引起其他元素位置改变
HashSet 是如何保证不重复的
向 HashSet 中 add ()元素时,判断元素是否存在的依据,不仅要比较hash值,同时还要结合 equles 方法比较。 HashSet 中的 add ()方法会使用 HashMap 的 add ()方法。以下是 HashSet 部分源码:

HashMap 的 key 是唯一的,由上面的代码可以看出 HashSet 添加进去的值就是作为 HashMap 的key。所以不会 重复( HashMap 比较key是否相等是先比较 hashcode 在比较 equals )。
HashMap 是线程安全的吗,为什么不是线程安全的(最好画图说明多线程 环境下不安全)?
不是线程安全的;
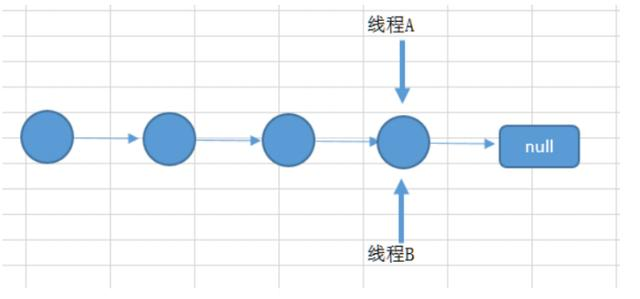
如果有两个线程A和B,都进行插入数据,刚好这两条不同的数据经过哈希计算后得到的哈希码是一样的,且该位 置还没有其他的数据。所以这两个线程都会进入我在上面标记为1的代码中。假设一种情况,线程A通过if判断,该 位置没有哈希冲突,进入了if语句,还没有进行数据插入,这时候 CPU 就把资源让给了线程B,线程A停在了if语句 里面,线程B判断该位置没有哈希冲突(线程A的数据还没插入),也进入了if语句,线程B执行完后,轮到线程A执 行,现在线程A直接在该位置插入而不用再判断。这时候,你会发现线程A把线程B插入的数据给覆盖了。发生了线 程不安全情况。本来在 HashMap 中,发生哈希冲突是可以用链表法或者红黑树来解决的,但是在多线程中,可能 就直接给覆盖了。
上面所说的是一个图来解释可能更加直观。如下面所示,两个线程在同一个位置添加数据,后面添加的数据就覆盖 住了前面添加的。

如果上述插入是插入到链表上,如两个线程都在遍历到最后一个节点,都要在最后添加一个数据,那么后面添加数 据的线程就会把前面添加的数据给覆盖住。则
在扩容的时候也可能会导致数据不一致,因为扩容是从一个数组拷贝到另外一个数组。
HashMap 的扩容过程
当向容器添加元素的时候,会判断当前容器的元素个数,如果大于等于阈值(知道这个阈字怎么念吗?不念 fa 值, 念 yu 值四声)---即当前数组的长度乘以加载因子的值的时候,就要自动扩容啦。
扩容( resize )就是重新计算容量,向 HashMap 对象里不停的添加元素,而 HashMap 对象内部的数组无法装载更 多的元素时,对象就需要扩大数组的长度,以便能装入更多的元素。当然 Java 里的数组是无法自动扩容的,方法 是使用一个新的数组代替已有的容量小的数组,就像我们用一个小桶装水,如果想装更多的水,就得换大水桶。
HashMap hashMap=new HashMap(cap);
cap =3, hashMap 的容量为4;
cap =4, hashMap 的容量为4;
cap =5, hashMap 的容量为8;
cap =9, hashMap 的容量为16;
如果 cap 是2的n次方,则容量为 cap ,否则为大于 cap 的第一个2的n次方的数。
HashMap 1.7 与 1.8 的 区别,说明 1.8 做了哪些优化,如何优化的?
HashMap结构图

在 JDK1.7 及之前的版本中, HashMap 又叫散列链表:基于一个数组以及多个链表的实现,hash值冲突的时候, 就将对应节点以链表的形式存储。
JDK1.8 中,当同一个hash值( Table 上元素)的链表节点数不小于8时,将不再以单链表的形式存储了,会被 调整成一颗红黑树。这就是 JDK7 与 JDK8 中 HashMap 实现的最大区别。
其下基于 JDK1.7.0_80 与 JDK1.8.0_66 做的分析
JDK1.7中
使用一个 Entry 数组来存储数据,用key的 hashcode 取模来决定key会被放到数组里的位置,如果 hashcode 相 同,或者 hashcode 取模后的结果相同( hash collision ),那么这些 key 会被定位到 Entry 数组的同一个 格子里,这些 key 会形成一个链表。
在 hashcode 特别差的情况下,比方说所有key的 hashcode 都相同,这个链表可能会很长,那么 put/get 操作 都可能需要遍历这个链表,也就是说时间复杂度在最差情况下会退化到 O(n)
JDK1.8中
使用一个 Node 数组来存储数据,但这个 Node 可能是链表结构,也可能是红黑树结构
- 如果插入的 key 的 hashcode 相同,那么这些key也会被定位到 Node 数组的同一个格子里。
- 如果同一个格子里的key不超过8个,使用链表结构存储。
- 如果超过了8个,那么会调用 treeifyBin 函数,将链表转换为红黑树。
那么即使 hashcode 完全相同,由于红黑树的特点,查找某个特定元素,也只需要O(log n)的开销
也就是说put/get的操作的时间复杂度最差只有 O(log n) 听起来挺不错,但是真正想要利用 JDK1.8 的好处,有一个限制: key的对象,必须正确的实现了 Compare 接口 如果没有实现 Compare 接口,或者实现得不正确(比方说所有 Compare 方法都返回0) 那 JDK1.8 的 HashMap 其实还是慢于 JDK1.7 的
简单的测试数据如下:
向 HashMap 中 put/get 1w 条 hashcode 相同的对象 JDK1.7: put 0.26s , get 0.55s JDK1.8 (未实现 Compare 接口): put 0.92s , get 2.1s 但是如果正确的实现了 Compare 接口,那么 JDK1.8 中的 HashMap 的性能有巨大提升,这次 put/get 100W条 hashcode 相同的对象 JDK1.8 (正确实现 Compare 接口,): put/get 大概开销都在320 ms 左右
final finally finalize final
- 可以修饰类、变量、方法,修饰类表示该类不能被继承、修饰方法表示该方法不能被重写、修饰变量表 示该变量是一个常量不能被重新赋值。
- finally一般作用在try-catch代码块中,在处理异常的时候,通常我们将一定要执行的代码方法finally代码块 中,表示不管是否出现异常,该代码块都会执行,一般用来存放一些关闭资源的代码。
- finalize是一个方法,属于Object类的一个方法,而Object类是所有类的父类,该方法一般由垃圾回收器来调 用,当我们调用 System.gc() 方法的时候,由垃圾回收器调用finalize(),回收垃圾,一个对象是否可回收的 最后判断。
感谢你耐心看完了文章…
关注作者,我会不定期在思否分享Java,Spring,MyBatis,Redis,Netty源码分析,高并发、高性能、分布式、微服务架构的原理,JVM性能优化、分布式架构,BATJ面试 等资料…
正文到此结束
热门推荐










相关文章

近期评论
-
你这基本没有更新呀,最近文章显示还是2019年的文章。不符合要求哈
-
关键词:慕云博客 链接:https://www.lilun.me 描述:分享原创文字的个人博客
-
-
-
可以提供一下源码吗
-
不是商业站,鸡娃学习笔记
-
-
-
-
听他们说很厉害的样子
Loading...
![[HBLOG]公众号](http://www.liuhaihua.cn/img/qrcode_gzh.jpg)

