轻松构建微服务之服务注册和发现
为什么需要服务注册中心? 随着服务数量的扩张,我们需要服务调用方能够自动感知到服务提供方的地址,当我们对服务提供方进行横向扩展的时候,服务调用方能够自动感知到,这就需要服务提供方能够在启动或者关闭的时候自动向注册中心注册,而服务调用方直接询问注册中心就可以知道具体的服务提供方的地址列表,服务调用方可以自己根据特定的路由算法做负载均衡, 或者服务调用方根本不需要知道服务提供方的具体地址,统一发给一个代理系统,由这个代理系统转发给对应的服务调用方。所以为了支持服务的弹性扩展,我们需要一个独立系统做服务发现和负载均衡,目前做服务发现有三种代理模式
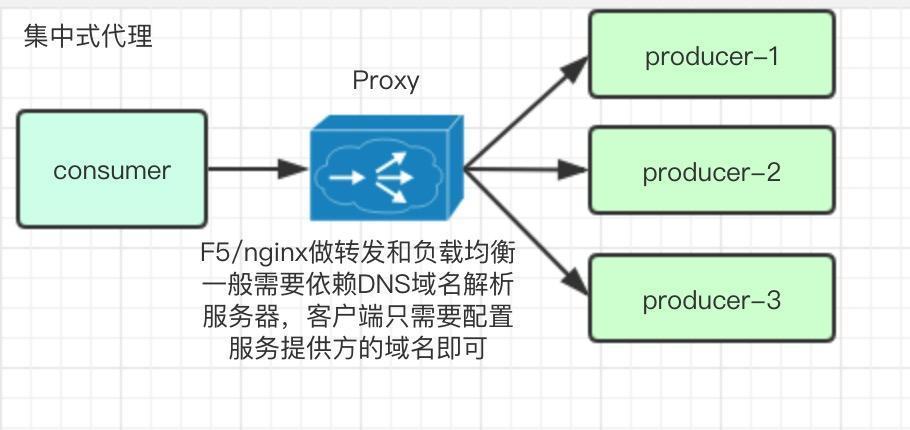
集中代理模式
集中代理模式一般是在服务调用方和服务提供方之间部署一套独立的代理系统来接收调用方的请求,然后配合域名系统和特定的负载均衡策略以及路由算法,转发到对应的服务提供方,这个代理系统一般由硬件F5设备加7层软件负载nginx配合域名系统来使用,这种模式,有集中治理,运维简单,而且和语言栈无关的优点,但是目前这个代理系统存在单点问题,而且配置比较麻烦,由于服务调用者没有之间调用服务提供方,所以网络上存在多一跳的开销,目前国内主要有携程等公司在使用
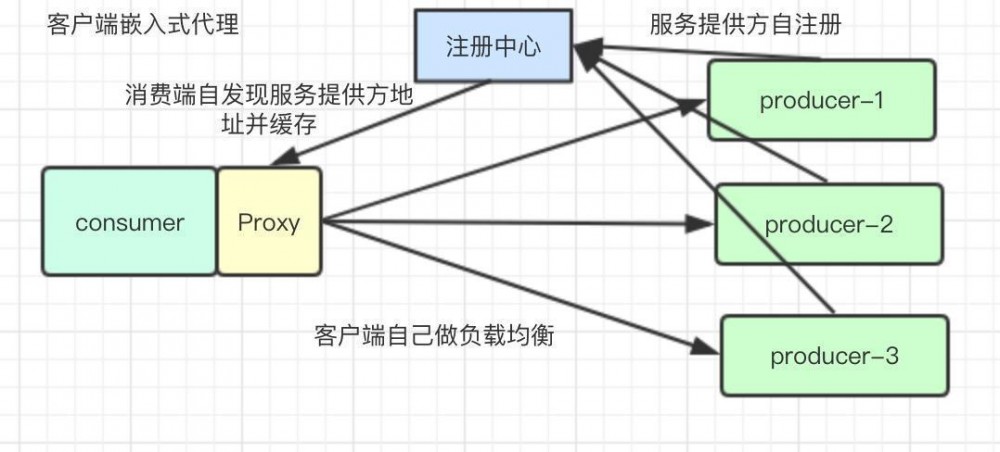
客户端嵌入式代理
目前很多公司用springcloud或者dubbo作为rpc框架的公司多选择这种模式,在客户端嵌入一个程序做服务发现和软件负载均衡,调用方会缓存服务提供方的地址列表,并且自己根据路由算法和负载均衡策略选择服务提供者进行调用,这种模式需要一个第三方的注册中心配合,服务提供者启动的时候将服务注册到注册中心,服务调用方去注册中心获取服务提供者信息,这种模式有无单点问题,性能好的优点,但是由于客户端需要关心负载均衡和维护提供者列表,导致客户端臃肿,目前国内主要有阿里的dubbo和新浪的Motan
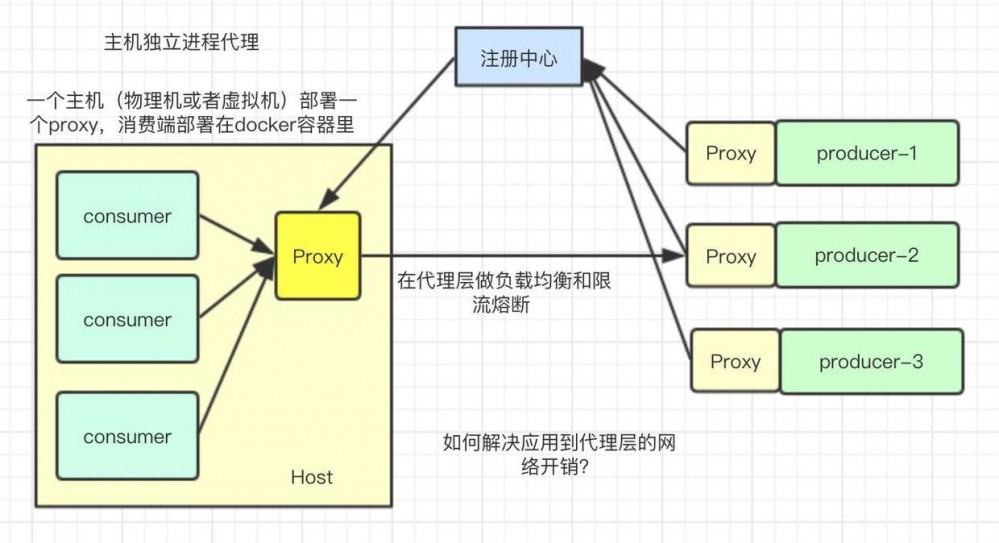
主机独立进程代理
这种模式是前面两种模式的一个折中,将这个代理放到主机的一个独立程序上,所有这个主机上的应用共享这个代理,应用一般部署在docker容器中,主机可以是一个物理机也可以是虚拟机。在这个代理上进行路由和负载均衡,这个模式也需要一个模式二中独立的注册中心来辅助代理程序做服务发现,这种模式兼具上面两种模式的优点,但是运维较复杂,目前国内只有唯品会有这种模式的探索
servicemesh介绍
边车模式,sidecar,将一个单独的进程用来处理,日志,健康,限流,服务发现等功能,和应用层完全分离,目前如果我们大多lib等软件包的形式和应用集成来实现限流和监控,这样增加了应用依赖,每次lIB包升级都需要将应用重新编译发布,而边车模式下我们可以将逻辑层和控制层分开部署.
边车模式进化后,将这个独立程序集群化,就成了servicemesh,也就是CNCF所推荐的新一代微服务架构,将这个代理程序下沉为一个基础服务,作为平台开放给应用程序
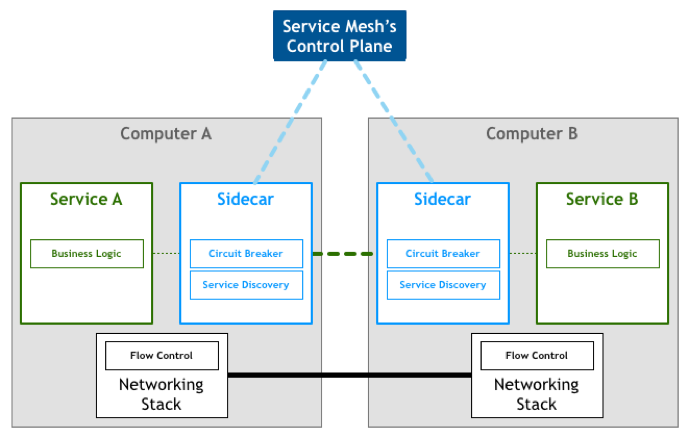
servicemesh的定义:一作为个轻量级的网络代理专职处理服务和服务间的通讯,对应用程序透明,用来分离或者解耦和分布式系统架构中控制层的上的东西.
类似于网络七层模型中的TCP协议,将底层那些难控制的网络通讯方面的东西(拥塞控制,丢包重传,流量控制)都处理了,而上层的http协议就只用关心应用层的html格式
演化路径
- 1.一开始最原始的两台主机之间进程直接通讯
- 2.然后分离出网络层来,服务间的远程通信通过底层的网络模型
- 3.由于两边服务由于接收速度不一致,需要在应用层做流控
- 4.然后流控模块交给网络层去处理,最后TCP演化成为世界上最成功的网络协议
- 5.类比分布式架构中,我们在应用层加入了限流,熔断,监控,服务发现等功能
- 6.然后我们发现这些控制层的功能都可以标准化,我们将这些功能分别做成LIB嵌入到应用中,这样谁需要这个功能只要加入这个LIB就好了
- 7.最后我们发现这些LIB不能跨编程语言,然后有什么改动就需要重新编译发布服务,不太方便,应该有一个专门的层来干这个,就是sidecar
- 8.然后sidecar集群就成了Service mesh ,成为了一个基础设施
目前开源的servicemesh实现有istio
为什么zookeeper不适合做服务发现
- 首先我们分析下服务发现是满足cap里面的ap还是cp
注册中心提供了两个服务,一个是让服务提供方注册,就是写数据,另一个是让服务调用方查询,就是读数据,当注册中心集群部署后,每个节点 都可以对外提供读写服务,每一次写请求都会同步到其他节点,这样才能让其他节点提供的读服务正确,如果节点之间的数据复制出现不一致,那么将导致服务调用方获取到的服务提供者列表中要么出现已经下线的节点,要么少提供了一个正常的节点, 提供了下线的节点,服务调用者可以通过重试机制调用其他节点,出现少提供一个正常节点则导致服务提供方的流量不均匀,这些都是可以接受的,何况各个节点最终都会同步成功,也就是数据最终一致性,所以我们希望注册中心是高可用的,最好能满足最终一致性,而zookeeper是典型的CP设计,在网络分区情况下不可用,当节点超过半数挂掉不可用,违背了注册中心不能因为自身任何原因破坏服务本身的可连通性
- 另外我们分析下出现网络分区的情况
我们看下下图zookeeper三机房5节点部署的情况下,如果机房3和机房1机房2网络出现分区成为孤岛,zookeeper和机房3里的其他应用不能和外部通信,zookeeper由于联系不是leader将不可用,虽然zookeeper整个集群中其他4个节点依然可以对外提供服务,但是zookeeper为了保证在脑裂的情况下数据一致性,机房3的节点5将不能进行读写服务,这个时候机房3内的应用A虽然不能 调用其他机房的服务B但是可以调用机房3内的服务B,但是由于Zookeeper5不能读写,所以机房内也不能读写,这对应用来说是完全不能接受的,我们有时候为了性能考虑还好主动修改路由策略让应用尽量同机房调用,试想一下如果三个机房都出现网络分区相互成为孤岛,那么整个应用将不可用
[图片上传失败...(image-269105-1558422945065)]
- zookeeper的写服务并不支持水平扩展
zookeeper需要和所有的服务保持长连接,而随着服务的频繁发布,以及服务的健康检查,会导致zookeeper压力越来越大,而zookeeper并不能通过横向扩展节点解决,可以提供的方案是按照业务进行拆分到不同的zookeeper集群
- 健康检查
服务提供方是否可用,不能仅仅通过zookeeper的session是否存活判断,TCP活性并不能反映服务的真实健康状态,而需要完整的健康体系,CPU,内存,服务是否可用,数据库是否能联通等
正文到此结束
热门推荐










相关文章






Loading...
![[HBLOG]公众号](http://www.liuhaihua.cn/img/qrcode_gzh.jpg)

