使用Docker和Kubernetes将MongoDB作为微服务运行
【编者的话】MongoDB是NoSQL排名第一的数据库,Docker是最流行的容器引擎,Kubernetes是谷歌开源的容器编排工具!Kubernetes和Docker使MongoDB的开发运维部署变得更加简单和强大。
Docker背景介绍
想快速安装MongoDB吗?现在只需要执行一个Docker命令,就能快速启动一个轻量级,独立的沙盒;在多个不同的服务器环境中搭建集群,快速部署相同的应用?使用Docker容器会非常的简单,构建自己的Docker容器镜像,让开发、测试、运营和支持团队启动相同的环境克隆。
Docker容器正在彻底改变整个软件生命周期:从最早的技术实验和概念证明到开发、测试、部署和支持。
Kubernetes工具可以管理多个Docker容器的创建,升级和高可用性。Kubernetes业务流程还控制容器如何连接以从多个微服务容器构建复杂的应用程序。Docker容器和Kubernetes编排已经成为DevOps团队的最爱,现在广泛融入到持续集成(CI)和持续交付(CD)工作流程中。
本文深入探讨了在Docker容器中运行和编排MongoDB所面临的额外挑战,并介绍这些挑战的解决办法。
MongoDB容器的注意事项
使用Docker容器和Kubernetes运行MongoDB额外注意事项:
- MongoDB数据库节点有状态信息。如果Docker容器发生故障并重新编排可能导致数据丢失,我们并不希望丢失数据(可以从副本集中的其他节点恢复,但需要时间)。为了解决可能的数据丢失问题,可以使用诸如Kubernetes中的Volume卷抽象之类的功能来将容器中临时性MongoDB数据目录映射到持久性位置,这样就可以容忍容器故障和重新编排,而不会丢失数据。
- 集群中的MongoDB数据库节点必须相互通信。副本集中的所有节点都必须知道所有节点的地址,但是当Kubernetes重新编排容器时,可能会使用不同的IP地址重新启动。例如,Kubernetes Pod中的所有容器共享一个IP地址,该地址在重新编排Pod时会发生变化。使用Kubernetes,可以通过将Kubernetes服务与每个MongoDB节点相关联来处理,该节点使用Kubernetes DNS服务为通过重新安排保持不变的服务提供主机名。
- 每个MongoDB节点运行后(每个节点都在自己的容器中),必须初始化副本集并添加每个节点。这可能需要编排工具之外的代码。具体而言,必须使用目标副本集群中的主MongoDB节点执行rs.initiate和rs.add命令。
- 如果Kubernetes编排框架提供容器的自动重新调度(如Kubernetes那样),那么这可以提高MongoDB的弹性,因为可以自动重新创建失败的副本集成员,从而在没有人为干预的情况下恢复正常状态。
- 应该注意的是,虽然Kubernetes可能会监视容器的状态,但它不太可能监视容器内运行的应用程序或备份数据。这意味着我们需要再使用强大的监控和备份解决方案非常重要,例如MongoDB企业高级版和MongoDB专业版附带的MongoDB Cloud Manager。考虑创建自己的镜像,其中包含首选的MongoDB版本和MongoDB自动化代理。
使用Docker和Kubernetes实现MongoDB Replica Set副本集群
如上所述,当使用诸如Kubernetes之类的编排工具部署时,MongoDB等分布式数据库需要特别小心。本节将进一步详细介绍这一点。
我们首先在单个Kubernetes集群中创建整个MongoDB副本集群(通常位于单个数据中心内——显然不提供地理冗余)。实际上,很少需要更改配置来支持跨多个中心的集群架构,这些步骤将在后面介绍。
Replica Set副本集群的每个成员将作为单独的Pod运行,其中一个服务公开外部IP地址和端口。这个“固定”的IP地址很重要,因为外部应用程序和其他副本集成员可以依赖它,在重新编排Pod时保持地址不变。 如果你想和更多Kubernetes技术专家交流,可以加我微信liyingjiese,备注『加群』。群里每周都有全球各大公司的最佳实践以及行业最新动态 。
下图说明了其中一个Pod以及关联的Replication Controller和服务。
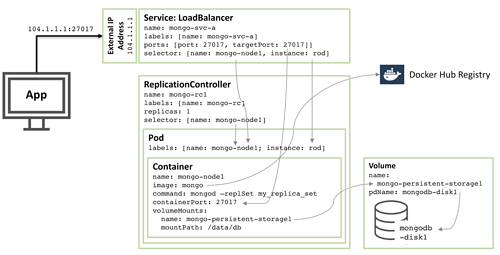
图1: MongoDB Replica Set副本集群成员配置为Kubernetes Pod并作为服务公开
配置Kubernetes Pod步骤如下:
-
开始创建名为mongo-node1的容器。 mongo-node1包含一个名为mongo的镜像,这是一个托管在Docker Hub上的公开可用的MongoDB容器镜像。容器公开集群中的端口27107。
2.Kubernetes volumes卷用于将/data/db目录映射到名为mongo-persistent-storage1的持久存储元素;然后映射到在Google Cloud中创建的名为mongodb-disk1的磁盘。这是MongoDB存储数据的位置,以便在容器重新调度时保持不变。
3.Pod内的容器实例,标签mongo-node,实例名称rod。
4.名为mongo-rc1的复制控制器,目的是确保mongo-node1 pod的单个实例始终在运行。
5.名为mongo-svc-a的LoadBalancer服务向外界公开IP地址以及27017的端口,该端口映射到容器中的相同端口号。该服务使用与pod标签匹配的选择器来识别正确的pod。该外部IP地址和端口将由应用程序和副本集成员之间的通信使用。每个容器也有本地IP地址,但这些容器在移动或重新启动容器时会发生更改,因此不会用于Replica Set副本集群。
下图显示了Replica Set副本集群的第二个成员的配置。
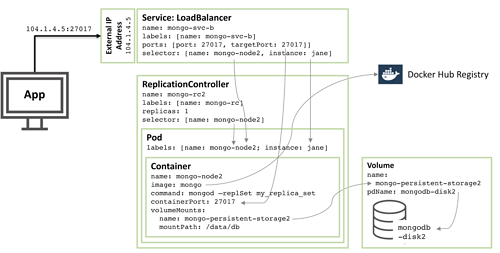
图2:第二个MongoDB副本集群成员配置为Kubernetes Pod
只有这些配置不一样,其他90%的配置是相同的:
- 磁盘和卷名称必须唯一,因此使用名称:mongodb-disk2和mongo-persistent-storage2
- Pod标签:jane和name:mongo-node2,以便新服务可以将它与图1中rod的Pod区分开来。
- 复制控制器名为mongo-rc2
- 该服务名为mongo-svc-b,并获取唯一的外部IP地址(在此示例中,Kubernetes已分配104.1.4.5)
第三个副本集成员的配置遵循相同的模式,下图是完整的Replica Set副本集群:
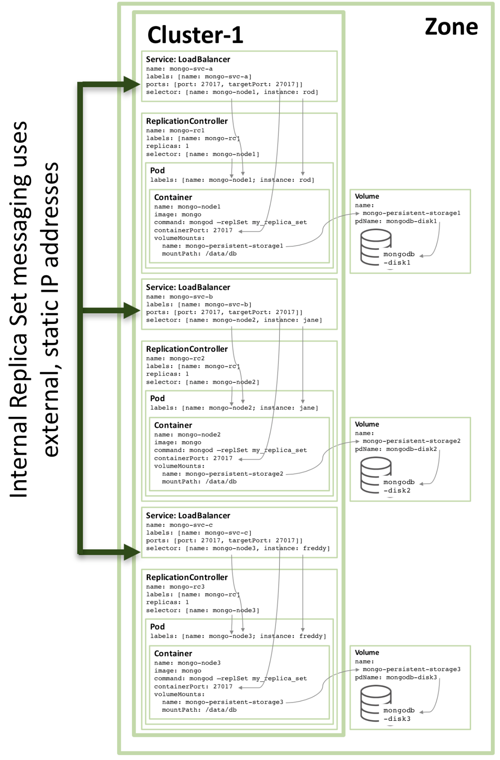
图3:配置为Kubernetes服务的完整副本集群成员
请注意,即使在三个或更多节点的Kubernetes集群上运行图3所示的配置,Kubernetes也可能(通常会)在同一主机上安排两个或更多MongoDB Replica Set副本集群成员。 这是因为Kubernetes将三个pod当作三个独立服务。
为了增加冗余(在区域内),可以创建额外的Headless Service服务。 该服务不向外界提供任何服务(甚至不具有IP地址),但它用于通知Kubernetes三个MongoDB pod构成的节点信息,Kubernetes可以尝试在不同节点上编排这些Pod实例。
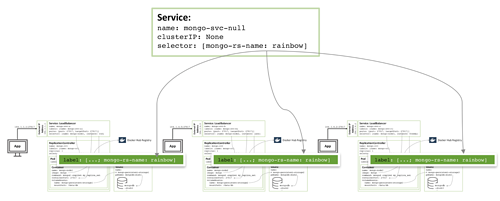
图4:Headless service无头服务,以避免MongoDB副本集成员的共同定位
可以在《 启用微服务:容器和编排说明 》白皮书中找到Kubernetes编排和启动MongoDB Replica Set副本集群所需的实际配置文件和命令。特别是,将三个MongoDB实例组合成一个功能强大的HA集群需要一些特殊步骤,这些副本集在本文中有所描述。
多个可用区MongoDB Replica Set副本集群
上面创建的副本集存在当机风险,因为一切都在同一个GCE集群中运行,本质上在同一可用区中。如果发生可用区脱机的重大事故,则整个MongoDB副本集将不可用。如果需要做地理空间的分布式冗余,可以在三个不同的可用区域或区域中运行三个窗格。
创建三个可用区域的分布式副本集群,并不需要太多的配置修改——只需要创建三个集群。每个群集都需要自己的Kubernetes YAML文件,该文件为集群中的单个节点定义Pod,Replication Controller和服务。
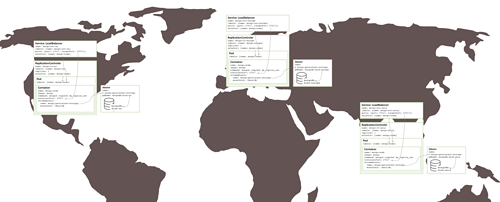
图5:在多个可用区域上运行的副本集
扩展阅读
要了解有关Docker容器和Kubernetes编排的更多信息——包括所涉及的技术及其提供的业务优势——请阅读“启用微服务:容器和编排说明”白皮书。 https://www.mongodb.com/collat ... ained ,这个白皮书还提供了在Google容器引擎中的Docker和Kubernetes上启动并运行本文中描述的副本集群的完整说明。
原文链接: https://yq.aliyun.com/articles/693940
正文到此结束
热门推荐










相关文章

近期评论
-
你这基本没有更新呀,最近文章显示还是2019年的文章。不符合要求哈
-
关键词:慕云博客 链接:https://www.lilun.me 描述:分享原创文字的个人博客
-
-
-
可以提供一下源码吗
-
不是商业站,鸡娃学习笔记
-
-
-
-
听他们说很厉害的样子
Loading...
![[HBLOG]公众号](http://www.liuhaihua.cn/img/qrcode_gzh.jpg)

