『互联网架构』软件架构-Sharding-Sphere分库分表(66)
今天介绍下sharding-sphere,主要介绍他的特性,分库分表的技术的详解。
源码:https://github.com/limingios/netFuture/tree/master/shardingSphere

(一)下载源码
-
官网地址获取源码
> https://shardingsphere.apache.org/index_zh.html
-
下载源码
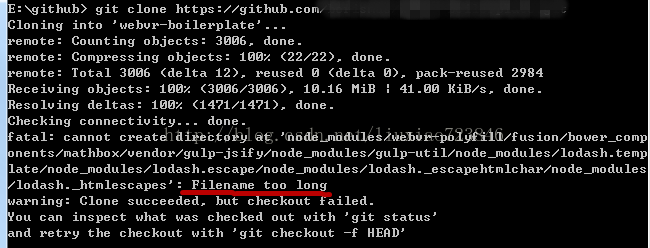
> 因为git的包名比较长,git有可以创建4096长度的文件名,然而在windows最多是260,因为git用了旧版本的windows api,为此踩了个坑。
从github克隆一个项目下发出现了错误:
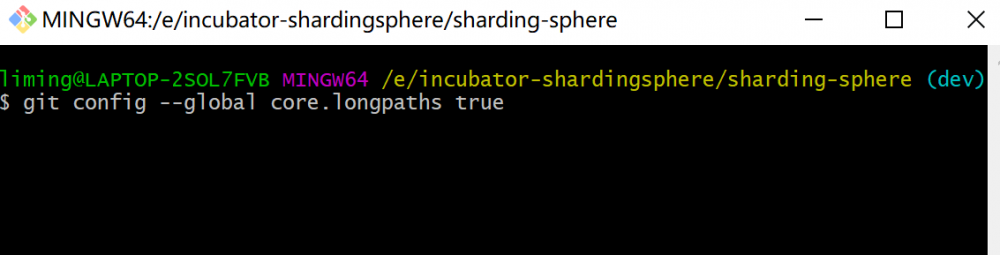
git config --global core.longpaths true
克隆项目
没选择github,毕竟国外服务器,下载还是比较慢
idea下载完毕
(二)分片的核心概念
-
SQL核心概念
> 逻辑表
水平拆分的数据库(表)的相同逻辑和数据结构表的总称。例:订单数据根据主键尾数拆分为10张表,分别是t_order_0到t_order_9,他们的逻辑表名为t_order。
真实表
在分片的数据库中真实存在的物理表。即上个示例中的t_order_0到t_order_9。
数据节点
数据分片的最小单元。由数据源名称和数据表组成,例:ds_0.t_order_0。
绑定表
指分片规则一致的主表和子表。例如:t_order表和t_order_item表,均按照order_id分片,则此两张表互为绑定表关系。绑定表之间的多表关联查询不会出现笛卡尔积关联,关联查询效率将大大提升。
广播表
指所有的分片数据源中都存在的表,表结构和表中的数据在每个数据库中均完全一致。适用于数据量不大且需要与海量数据的表进行关联查询的场景,例如:字典表。
逻辑索引
某些数据库(如:PostgreSQL)不允许同一个库存在名称相同索引,某些数据库(如:MySQL)则允许只要同一个表中不存在名称相同的索引即可。 逻辑索引用于同一个库不允许出现相同索引名称的分表场景,需要将同库不同表的索引名称改写为索引名 + 表名,改写之前的索引名称成为逻辑索引。
-
分片
> 分片键
用于分片的数据库字段,是将数据库(表)水平拆分的关键字段。例:将订单表中的订单主键的尾数取模分片,则订单主键为分片字段。 SQL中如果无分片字段,将执行全路由,性能较差。 除了对单分片字段的支持,ShardingSphere也支持根据多个字段进行分片。
分片算法
通过分片算法将数据分片,支持通过=、BETWEEN和IN分片。分片算法需要应用方开发者自行实现,可实现的灵活度非常高。
目前提供4种分片算法。由于分片算法和业务实现紧密相关,因此并未提供内置分片算法,而是通过分片策略将各种场景提炼出来,提供更高层级的抽象,并提供接口让应用开发者自行实现分片算法。
1.精确分片算法
对应PreciseShardingAlgorithm,用于处理使用单一键作为分片键的=与IN进行分片的场景。需要配合StandardShardingStrategy使用。
2.范围分片算法
对应RangeShardingAlgorithm,用于处理使用单一键作为分片键的BETWEEN AND进行分片的场景。需要配合StandardShardingStrategy使用。
3.复合分片算法
对应ComplexKeysShardingAlgorithm,用于处理使用多键作为分片键进行分片的场景,包含多个分片键的逻辑较复杂,需要应用开发者自行处理其中的复杂度。需要配合ComplexShardingStrategy使用。
4.Hint分片算法
对应HintShardingAlgorithm,用于处理使用Hint行分片的场景。需要配合HintShardingStrategy使用。
-
分片策略
> 包含分片键和分片算法,由于分片算法的独立性,将其独立抽离。真正可用于分片操作的是分片键 + 分片算法,也就是分片策略。目前提供5种分片策略。
1.标准分片策略
对应StandardShardingStrategy。提供对SQL语句中的=, IN和BETWEEN AND的分片操作支持。StandardShardingStrategy只支持单分片键,提供PreciseShardingAlgorithm和RangeShardingAlgorithm两个分片算法。PreciseShardingAlgorithm是必选的,用于处理=和IN的分片。RangeShardingAlgorithm是可选的,用于处理BETWEEN AND分片,如果不配置RangeShardingAlgorithm,SQL中的BETWEEN AND将按照全库路由处理。
2.复合分片策略
对应ComplexShardingStrategy。复合分片策略。提供对SQL语句中的=, IN和BETWEEN AND的分片操作支持。ComplexShardingStrategy支持多分片键,由于多分片键之间的关系复杂,因此并未进行过多的封装,而是直接将分片键值组合以及分片操作符透传至分片算法,完全由应用开发者实现,提供最大的灵活度。
3.行表达式分片策略
对应InlineShardingStrategy。使用Groovy的表达式,提供对SQL语句中的=和IN的分片操作支持,只支持单分片键。对于简单的分片算法,可以通过简单的配置使用,从而避免繁琐的Java代码开发,如: t_user_$->{u_id % 8} 表示t_user表根据u_id模8,而分成8张表,表名称为t_user_0到t_user_7。
4.Hint分片策略
对应HintShardingStrategy。通过Hint而非SQL解析的方式分片的策略。
5.不分片策略
对应NoneShardingStrategy。不分片的策略。
- 配置
分片规则
分片规则配置的总入口。包含数据源配置、表配置、绑定表配置以及读写分离配置等。
数据源配置
真实数据源列表。
表配置
逻辑表名称、数据节点与分表规则的配置。
数据节点配置
用于配置逻辑表与真实表的映射关系。可分为均匀分布和自定义分布两种形式。
均匀分布
指数据表在每个数据源内呈现均匀分布的态势,例如:
db0 ├── t_order0 └── t_order1 db1 ├── t_order0 └── t_order1
那么数据节点的配置如下:
db0.t_order0, db0.t_order1, db1.t_order0, db1.t_order1
自定义分布
指数据表呈现有特定规则的分布,例如:
db0 ├── t_order0 └── t_order1 db1 ├── t_order2 ├── t_order3 └── t_order4
那么数据节点的配置如下:
db0.t_order0, db0.t_order1, db1.t_order2, db1.t_order3, db1.t_order4
分片策略配置
对于分片策略存有数据源分片策略和表分片策略两种维度。
1.数据源分片策略
对应于DatabaseShardingStrategy。用于配置数据被分配的目标数据源。
2.表分片策略
对应于TableShardingStrategy。用于配置数据被分配的目标表,该目标表存在与该数据的目标数据源内。故表分片策略是依赖与数据源分片策略的结果的。
两种策略的API完全相同。
自增主键生成策略
通过在客户端生成自增主键替换以数据库原生自增主键的方式,做到分布式主键无重复。
(三)java连接数据库jdbc协议
- Java.sql.Connection 数据库连接对象。
- Java.sql.DataSource 连接数据源对象。
- Java.sql.Statement 编译sql sql注入。
- Java.sql.PreparedStement 预编译sql。
- Java.sql.ResultSet 查询返回结果。
(四)数据库定义
1.数据查询语言(DQL: Data Query Language)
数据检索语句,用于从表中获取数据。通常最常用的为保留字SELECT,并且常与FROM子句、WHERE子句组成查询SQL查询语句。
2.数据操纵语言(DML:Data Manipulation Language)
主要用来对数据库的数据进行一些操作,常用的就是INSERT、UPDATE、DELETE。
3.事务处理语言(DPL)
事务处理语句能确保被DML语句影响的表的所有行及时得以更新。TPL语句包括BEGIN TRANSACTION、COMMIT和ROLLBACK。
4.数据控制语言(DCL)
通过GRANT和REVOKE,确定单个用户或用户组对数据库对象的访问权限。
5.数据定义语言(DDL)
常用的有CREATE和DROP,用于在数据库中创建新表或删除表,以及为表加入索引等。
6.指针控制语言(CCL)
它的语句,想DECLARE CURSOR、FETCH INTO和UPDATE WHERE CURRENT用于对一个或多个表单独行的操作。
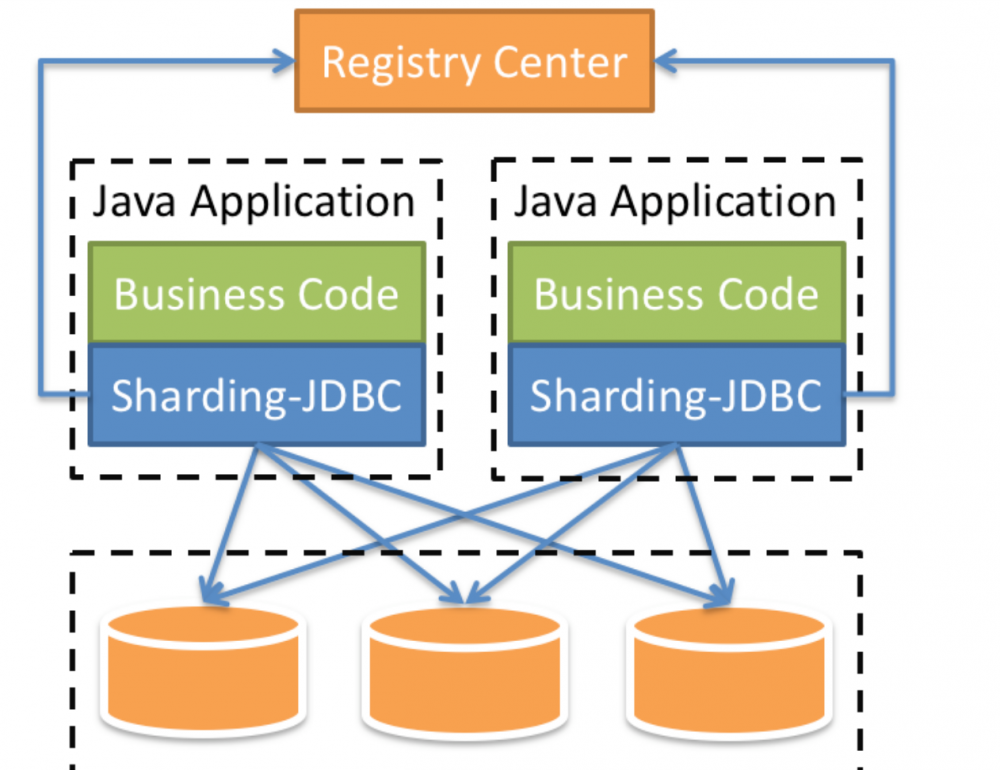
(五)sharding-jdbc
定位为轻量级Java框架,在Java的JDBC层提供的额外服务。它使用客户端直连数据库,以jar包形式提供服务,无需额外部署和依赖,可理解为增强版的JDBC驱动,完全兼容JDBC和各种ORM框架。
(六)源码
PS:Sharding-Sphere特性,还是直接看源码吧,结合api,写的在多也没api写的清楚。
>>原创文章,欢迎转载。转载请注明:转载自,谢谢!>>原文链接地址:上一篇:已是最新文章
正文到此结束
- 本文标签: update db 配置 代码 多个字段 id 2019 ssh windows sql GitHub 开发 删除 Master 部署 java tab 互联网 API 关联查询 http IO ResultSet mysql 源码 数据库 NSA 软件 DDL ORM Statement 协议 IDE key core Action JDBC 编译 https 数据 Select src IOS 索引 服务器 git 开发者 解析 Connection 下载 sharding apache ip UI HTML dataSource 文章 分布式
- 版权声明: 本文为互联网转载文章,出处已在文章中说明(部分除外)。如果侵权,请联系本站长删除,谢谢。
- 本文海报: 生成海报一 生成海报二
热门推荐










相关文章






Loading...
![[HBLOG]公众号](http://www.liuhaihua.cn/img/qrcode_gzh.jpg)

