Sharding-JDBC:查询量大如何优化?
主人公小王入职了一家刚起步的创业公司,公司正在研发一款App。为了快速开发出能够投入市场进行宣传的版本,小王可是天天加班到很晚,忙了一段时间后终于把第一个版本赶出来了。
初期功能不多,表也不多,用的MySql存储业务数据。就一个节点,当然每天凌晨有定时备份机制。
下图是目前的一个现状:
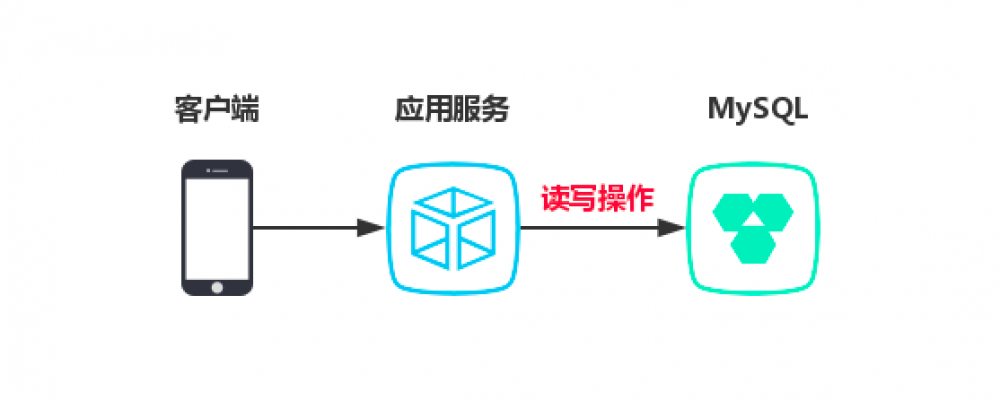
得益于运营人员的大力推广,这款App初见成效。注册用户越来越多,查询量越来越大,对于不太会更新的数据小王加上了缓存,又撑了一段时间。
对于某些数据还是要查数据库,按目前的业务发展,单节点的数据库已经快满足不了需求了。而且读和写都在一起,小王打算进行一次优化,将数据库做读写分离,一主多从。
下图是改进后的一个现状:
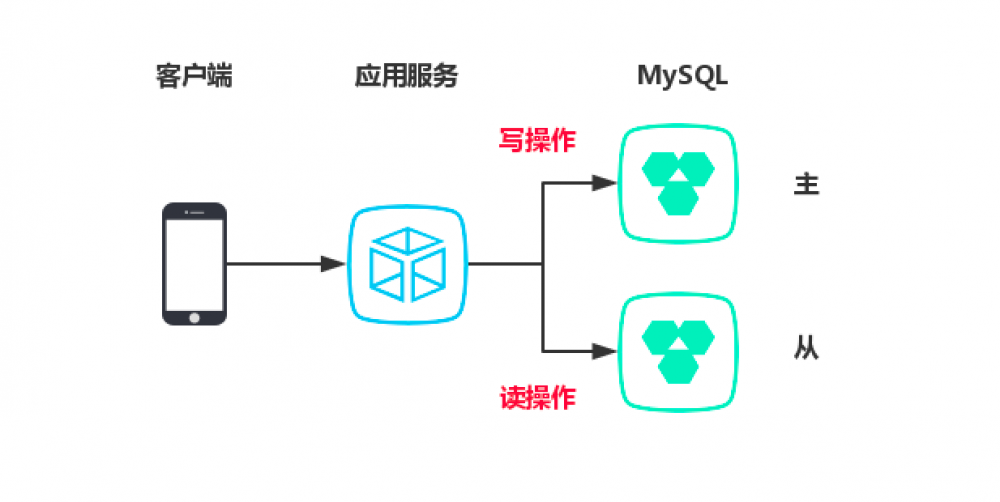
将读请求全部走从节点,主节点只写入来缓解数据的查询压力,数据库部署这块正好小王公司有个运维可以搞定,但是应用程序这块也得支持多数据源才行呀。
小王是个雷厉风行的人,行动力极强,马上脑袋中就有了方案,配置多个数据源不就行了,然后用不同的数据源进行数据操作就可以了嘛!
伪代码如下:
// 主数据源
@Bean(name = "primaryDataSource")
@Qualifier("primaryDataSource")
//指定数据源配置前缀
@ConfigurationProperties(prefix = "spring.datasource.primary")
public DataSource primaryDataSource() {
return DataSourceBuilder.create().build();
}
// 从数据源
@Bean(name = "secondaryDataSource")
@Qualifier("secondaryDataSource")
@Primary //在同样的DataSource中,首先使用被标注的DataSource
@ConfigurationProperties(prefix = "spring.datasource.secondary")
public DataSource secondaryDataSource() {
return DataSourceBuilder.create().build();
}
复制代码
假设我们用JdbcTemplate操作数据库:
@Bean(name = "primaryJdbcTemplate")
public JdbcTemplate primaryJdbcTemplate(@Qualifier("primaryDataSource") DataSource dataSource) {
return new JdbcTemplate(dataSource);
}
@Bean(name = "secondaryJdbcTemplate")
public JdbcTemplate secondaryJdbcTemplate(@Qualifier("secondaryDataSource") DataSource dataSource) {
return new JdbcTemplate(dataSource);
}
复制代码
配置完成后我们在操作数据的时候选用不同的JdbcTemplate就可以满足需求了。有个问题是一旦从节点多了起来,也就意味着会有多个JdbcTemplate,使用的时候是不是还得有个算法,用哪个来操作,比较麻烦。
于是小王找到了我,我这人是个热心肠。既然找到了我肯定得帮助下,当然我不是帮小王写代码,只是给他提供思路+方案。
我对小王说:ShardingSphere知道么,你用这个吧,比你自己去配多数据源简单多了。ShardingSphere是后来规划的,最开始是只有 Sharding-JDBC 一款产品,基于客户端形式的分库分表。后面发展变成了现在的Apache ShardingSphere(Incubator) ,它是一套开源的分布式数据库中间件解决方案组成的生态圈,它由Sharding-JDBC、Sharding-Proxy和Sharding-Sidecar(规划中)这3款相互独立,却又能够混合部署配合使用的产品组成。它们均提供标准化的数据分片、分布式事务和数据库治理功能,可适用于如Java同构、异构语言、容器、云原生等各种多样化的应用场景。
经过我的指导小王还是顺利的用Sharding-JDBC将读写分离整出来了,下面给大家分享下步骤。
第一步:创建2个数据库,模拟一主一从,当然如果你有现成的主从环境更好啦
CREATE DATABASE `ds_0` CHARACTER SET 'utf8' COLLATE 'utf8_general_ci'; CREATE DATABASE `ds_1` CHARACTER SET 'utf8' COLLATE 'utf8_general_ci'; CREATE TABLE `user`( id bigint(64) not null, city varchar(20) not null, name varchar(20) not null, PRIMARY KEY (`id`) ) ENGINE=InnoDB DEFAULT CHARSET=utf8; 复制代码
在ds_0和ds_1这两个库中分别创建一个user表,用于数据操作演示。
第二步:创建一个Maven项目,增加需要的依赖,下面只贴出Sharding-JDBC的,其余的后面我会给出源码地址给大家参考:
<dependency> <groupId>org.apache.shardingsphere</groupId> <artifactId>sharding-jdbc-spring-boot-starter</artifactId> <version>4.0.0-RC1</version> </dependency> 复制代码
第三步:配置读写分离的数据源
# 数据源名称集合,对应下面数据源配置的名称 spring.shardingsphere.datasource.names=master,slave # 主数据源 spring.shardingsphere.datasource.master.type=com.alibaba.druid.pool.DruidDataSource spring.shardingsphere.datasource.master.driver-class-name=com.mysql.jdbc.Driver spring.shardingsphere.datasource.master.url=jdbc:mysql://localhost:3306/ds_0?characterEncoding=utf-8 spring.shardingsphere.datasource.master.username=root spring.shardingsphere.datasource.master.password=123456 # 从数据源 spring.shardingsphere.datasource.slave.type=com.alibaba.druid.pool.DruidDataSource spring.shardingsphere.datasource.slave.driver-class-name=com.mysql.jdbc.Driver spring.shardingsphere.datasource.slave.url=jdbc:mysql://localhost:3306/ds_1?characterEncoding=utf-8 spring.shardingsphere.datasource.slave.username=root spring.shardingsphere.datasource.slave.password=123456 # 读写分离配置 spring.shardingsphere.masterslave.load-balance-algorithm-type=round_robin # 最终的数据源名称 spring.shardingsphere.masterslave.name=dataSource # 主库数据源名称 spring.shardingsphere.masterslave.master-data-source-name=master # 从库数据源名称列表,多个逗号分隔 spring.shardingsphere.masterslave.slave-data-source-names=slave 复制代码
load-balance-algorithm-type用于配置从库负载均衡算法类型,可选值:ROUND_ROBIN(轮询),RANDOM(随机)
配置完成后可以自行插入数据进行查询和插入的测试,对于应用层使用什么ORM框架无任何影响,你可以用我们前面讲的JdbcTemplate,也可以用Mybatis 等
测试步骤我就不写出来了,比较简单,当然我这边也提供了测试代码,仅供参考:
github.com/yinjihuan/s…
觉得不错的记得给我个Star哦!
还有个问题在读写分离架构中经常出现,那就是读延迟的问题如何解决?
刚插入一条数据,然后马上就要去读取,这个时候有可能会读取不到?
归根到底是因为主节点写入完之后数据是要复制给从节点的,读不到的原因是复制的时间比较长,也就是说数据还没复制到从节点,你就已经去从节点读取了,肯定读不到。
mysql5.7 的主从复制是多线程了,意味着速度会变快,但是不一定能保证百分百马上读取到,这个问题我们可以有两种方式解决:
- 业务层面妥协,是否操作完之后马上要进行读取
- 对于操作完马上要读出来的,且业务上不能妥协的,我们可以对于这类的读取直接走主库,当然Sharding-JDBC也是考虑到这个问题的存在,所以给我们提供了一个功能,可以让用户在使用的时候指定要不要走主库进行读取
在读取前使用下面的方式进行设置就可以了:
public List<User> list() {
// 强制路由主库
HintManager.getInstance().setMasterRouteOnly();
return userRepository.list();
}
复制代码

正文到此结束
- 本文标签: key lib bean JDBC apache git 压力 GitHub 分布式事务 build Word sharding java maven 线程 多线程 DOM MySQL5 加班 分布式 部署 spring db 数据库 IDE App dataSource 凌晨 id rand 云 tab 创业 数据 创业公司 开源 http Master druid mysql 源码 tar UI 时间 开发 推广 IO 缓存 测试 配置 需求 mybatis 运营 ORM Qualifier 备份 负载均衡 sql 代码 list src 业务层 Proxy root https 产品
- 版权声明: 本文为互联网转载文章,出处已在文章中说明(部分除外)。如果侵权,请联系本站长删除,谢谢。
- 本文海报: 生成海报一 生成海报二
热门推荐










相关文章

近期评论
-
Your article is a perfect article without a hitch. Thank you. My site: horse racing betting game
-
-
你这基本没有更新呀,最近文章显示还是2019年的文章。不符合要求哈
-
关键词:慕云博客 链接:https://www.lilun.me 描述:分享原创文字的个人博客
-
-
-
可以提供一下源码吗
-
不是商业站,鸡娃学习笔记
-
-
Loading...
![[HBLOG]公众号](http://www.liuhaihua.cn/img/qrcode_gzh.jpg)

