让人抓头的Java并发(二) 线程池ThreadPoolExecutor分析
线程的创建需要开辟虚拟机栈、本地方法栈、程序计数器等线程私有的内存空间,在线程销毁时需要回收这些系统资源。频繁的创建销毁线程会浪费大量资源,使用线程池可以更好的管理和协调线程的工作。
线程池的好处
- 降低资源消耗,通过重复利用已有线程降低线程创建和销毁造成的消耗
- 提高响应速度,任务到达不必等待线程的创建
- 管理复用线程,限制最大并发数
- 实现定时执行或周期执行的任务(ScheduledThreadPoolExecutor)
- 隔离线程环境,避免不同服务线程相互影响,防止服务发生雪崩(在SpringCloud的hystrix中也是这样做的,不同服务调用采用不同线程池)
线程池的使用
ThreadPoolExecutor的构造方法如下:public ThreadPoolExecutor(int corePoolSize,
int maximumPoolSize,
long keepAliveTime,
TimeUnit unit,
BlockingQueue<Runnable> workQueue,
ThreadFactory threadFactory,
RejectedExecutionHandler handler) {
if (corePoolSize < 0 ||
maximumPoolSize <= 0 ||
maximumPoolSize < corePoolSize ||
keepAliveTime < 0)
throw new IllegalArgumentException();
if (workQueue == null || threadFactory == null || handler == null)
throw new NullPointerException();
…………
}
复制代码
1)构造参数分析:
- corePoolSize:表示常驻的核心线程数量。如果为0执行任务之后没有任何请求进入时将被销毁,如果大于0则不会被销毁。
- maximumPoolSize:表示线程池最大能够容纳同时执行的线程数,必须大于等于1。如果和corePoolSize相等即是固定大小线程池,如果待执行线程数大于此数则按照参数handler处理。
- keepAliveTime:表示线程池中的线程空闲时间,当空闲时间达到此值时,线程会被销毁直到剩下corePoolSize个线程。默认当线程数大于corePoolSize时才会起作用,但是当ThreadPoolExecutor的allowCoreThreadTimeOut设置为true时核心线程超时后也会被销毁。
- unit:keepAliveTime的时间单位
- workQueue:表示缓存队列,当请求线程数大于corePoolSize时,线程将进入BlockingQueue。
- threadFactory:线程工厂,它用来生产一组相同任务的线程。通过给这个factory增加组名前缀来实现线程池命名,以方便在虚拟机栈分析时知道线程任务是由哪个线程工程产生的。
- handler:执行拒绝策略的对象。当workQueue满了之后并且活动线程数大于maximumPoolSize的时候,线程池通过该策略处理请求。
2)拒绝策略分析: ThreadPoolExecutor中提供了四个RejectedExecutionHandler策略。
- AbortPolicy(默认):丢弃任务并抛出RejectedExecutionException异常。
- DiscardPolicy:丢弃当前任务。
- DiscardOldestPolicy:丢弃任务中等待最久的任务,然后把当前任务加入队列。
- CallerRunsPolicy:调用任务的run()方法绕过线程池直接执行。
3)创建线程池的其他方式(不推荐):Executors这个线程池静态工厂可以创建三个线程池的包装对象:ForkJoinPool、ThreadPoolExecutor、ScheduledThreadPoolExecutor。Executors中关于ThreadPoolExecutor的核心方法如下:
// SynchronousQueue是不存储元素的阻塞队列,并且maximumPoolSize为Integer.MAX_VALUE
即是无界,当主线程提交任务速度高于CachedThreadPool的处理速度时会不断创建线程,
极端情况下会发生OOM
public static ExecutorService newCachedThreadPool() {
return new ThreadPoolExecutor(0, Integer.MAX_VALUE,
60L, TimeUnit.SECONDS,
new SynchronousQueue<Runnable>());
// keepAliveTime为0意味着多余的空闲线程会被立刻终止,LinkedBlockingQueue的默认容量
是Integer.MAX_VALUE即无界,极端情况下会发生OOM
public static ExecutorService newFixedThreadPool(int nThreads) {
return new ThreadPoolExecutor(nThreads, nThreads,
0L, TimeUnit.MILLISECONDS,
new LinkedBlockingQueue<Runnable>());
// LinkedBlockingQueue的默认容量是Integer.MAX_VALUE即无界,极端情况下会发生OOM
public static ExecutorService newSingleThreadExecutor() {
return new FinalizableDelegatedExecutorService
(new ThreadPoolExecutor(1, 1,
0L, TimeUnit.MILLISECONDS,
new LinkedBlockingQueue<Runnable>()));
复制代码
看过了上述方法之后可以发现这三个方法构造出来的线程池都存在OOM的风险。并且不能灵活的配置线程工厂和拒绝策略,所以不推荐使用Executors来创建线程池。
4)向线程池提交任务:有两个方法execute()和submit()可以向线程池提交任务。execute()方法用于提交不需要返回值的任务,无法判断任务是否被线程池执行成功。submit()方法用于提交有返回值的任务(Callable)。线程池会返回一个future类型对象,通过future的get()方法可以获取返回值,值得注意的是get()方法会阻塞当前线程直到任务完成。
5)关闭线程池:有两个方法shutdown()和shutdownNow()可以关闭线程池。它们的原理是遍历线程池中的工作线程,然后逐个的调用线程的interrupt()方法来中断线程(无法响应中断的线程无法终止)。它们的区别在于shutdownNow()首先将线程池状态设置为STOP,然后尝试停止所有线程;shutdown()是将线程池状态设置为SHOTDOWN,然后中断所有没有正在执行任务的线程。
线程池的原理解析
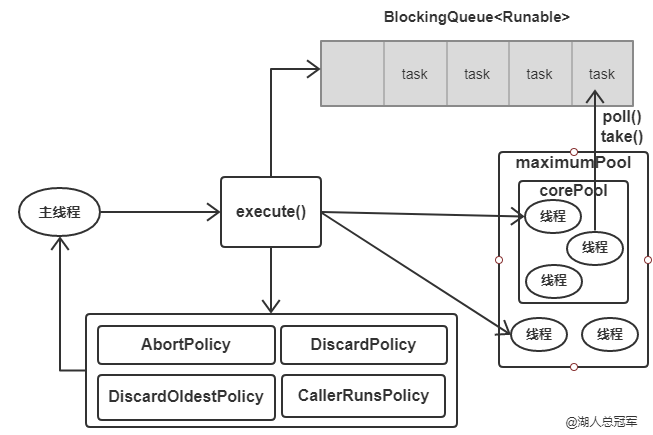
当线程池接收到一个任务之后,执行流程如下图:
- 判断当前工作线程数是否达到核心线程数,如果没有则创建一个新的线程来执行任务,如果达到了则进行下一个判断。
- 判断工作队列是否已经满了,如果工作队列没有满,则将任务加入工作队列中,否则进行下一个判断。
- 判断线程池是否已经满了,如果没有则创建新线程执行任务,否则按照饱和策略处理任务。
ThreadPoolExecutor执行示意图:
下面是ThreadPoolExecutor中execute()方法的核心代码:
public void execute(Runnable command) {
if (command == null)
throw new NullPointerException();
// 获取用于返回线程数和线程池状态的integer数值
int c = ctl.get();
// 1、如果工作线程数小于核心线程数,则创建任务并执行
if (workerCountOf(c) < corePoolSize) {
if (addWorker(command, true))
return;
c = ctl.get();
}
// 2、如果线程池处于RUNNING状态则将任务加入队列
if (isRunning(c) && workQueue.offer(command)) {
int recheck = ctl.get();
if (! isRunning(recheck) && remove(command))
reject(command);
else if (workerCountOf(recheck) == 0)
addWorker(null, false);
}
// 3、核心线程池和队列都满了,尝试创建一个新的线程
else if (!addWorker(command, false))
// 4、如果创建失败则执行拒绝策略
reject(command);
}
复制代码
addWorker()主要是创建工作线程 -- 将任务包装成Worker类。 在1、3两个步骤中创建线程时需要获取全局锁ReentrantLock避免被干扰,当当前工作线程数大于等于corePoolSize之后几乎所有的execute()都是在执行步骤2。 Worker在执行完任务之后还会循环获取工作队列的任务来执行 while (task != null || (task = getTask()) != null) ,getTask()方法中获取阻塞队列中的任务(poll()或take(),如果核心线程会被销毁或者当前线程数大于核心线程数则用poll()超时获取)
boolean timed = allowCoreThreadTimeOut || wc > corePoolSize;
Runnable r = timed ? workQueue.poll(keepAliveTime, TimeUnit.NANOSECONDS)
: workQueue.take();
复制代码
线程池的工作原理代码在这里就不具体分析了,下图直观的展示了线程池的工作原理。
合理配置线程池
想要合理的配置线程池首先需要分析任务特性:CPU密集型任务、IO密集型任务、混合型任务 .
-
CPU密集型任务:尽量使用较小的线程池,一般为CPU核心数+1。CPU密集型任务的CPU使用率很高,过多的线程数运行只能增加上下文切换的次数,因此会带来额外的开销。
-
IO密集型任务:使用稍大的线程池,一般为2*CPU核心数。IO密集型任务CPU使用率并不高,可以让CPU在等待IO的时候去处理别的任务,充分利用CPU。
-
混合型任务:可以将任务分成IO密集型和CPU密集型任务,然后分别用不同的线程池去处理。只要分完之后两个任务的执行时间相差不大,那么就会比串行执行高效。如果划分之后两个任务执行时间相差甚远,那么最终的时间仍然取决于后执行完的任务,而且还要加上任务拆分与合并的开销。
在线程池的实现中还涉及了很多并发包中的知识比如BlockingQueue、ReentrantLock、Condition等,在这里就暂时不进行介绍了,后续会介绍它们。
正文到此结束
热门推荐










相关文章






Loading...
![[HBLOG]公众号](http://www.liuhaihua.cn/img/qrcode_gzh.jpg)

