你确定不来了解一下Redis列表的内部原理吗
在上一章中我们介绍了 String 的一些内部原理《 你确定不来了解下 Redis 字符串的原理吗 》,在这一章中我们再来讨论在五种数据结构中 List 的基本使用和一些内部实现.
基本介绍
Redis的List 呢相当于 Java 中的 LinkedList,也是双向链表.具有一些和 LinkedList 同样的特征,比如插入和删除一条很快,时间复杂度为 O(1),获取头结点和尾节点也很快,时间复杂度也为 O(1),随机读取则相对较慢时间复杂度为 O(n).常用作消息队列.
当做队列使用时,遵循先进先出原则:
> rpush books python java golang (integer) 3 > lpop books "python" > lpop books "java" 复制代码
当做栈使用时,遵循先进后出原则:
> rpush books python java golang (integer) 3 > rpop books "golang" > rpop books "java" 复制代码
同时还可以通过 get(index)的方法获取:
> rpush books python java golang (integer) 3 > lindex books 0 "python" > lindex books -1 "golang" 复制代码
index从 0 开始,可以为负数 -1 代表倒数第一个元素
内部实现
上述部分我们把 Redis 中的 List当做 Java 中的 LinkedList 操作,因为有很多相同的部分.但实际上在 Redis 中链表的内部实现可不是一个简单的双向链表.在数据量较少的时候它的底层存储结构为一块连续内存,称之为 ziplist (压缩列表).当数据量较多的时候将会变成链表的结构.后来因为链表需要 prev 和 next 两个指针占用内存很多,改用 ziplist+链表的混合结构,称之为 quicklist (快速链表). 在新的版本中 Redis 链表统一使用 quicklist来存储 .下面我们就来详细介绍这种数据结构.
ziplist 压缩列表
先来看看 ziplist 的数据结构:
struct ziplist<T>{
int32 zlbytes; //压缩列表占用字节数
int32 zltail_offset; //最后一个元素距离起始位置的偏移量,用于快速定位到最后一个节点
int16 zllength; //元素个数
T[] entries; //元素内容
int8 zlend; //结束位 0xFF
}
复制代码
如图所示:
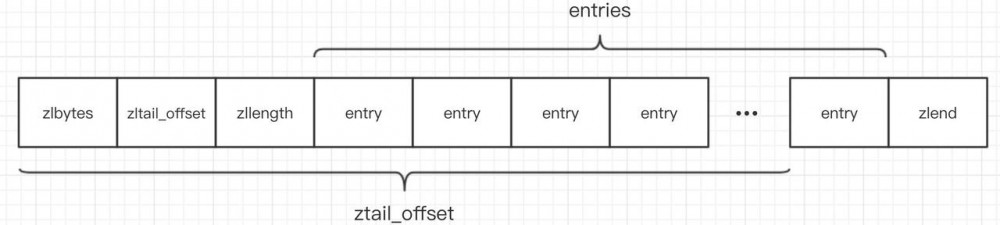
有了 ztail_offset 就可以快速的定位到最后一个节点,这样就可以倒序遍历了.也就是说 ziplist支持双向遍历.
下面再来看下 entry 的内部实现:
struct entry{
int<var> prevlen; //前一个 entry 的长度
int<var> encoding; //元素类型编码
optional byte[] content; //元素内容
}
复制代码
当 ziplist 倒序遍历的时候,就是通过这个pervlen定位到前一个元素位置的.
encoding 保存了 content 的编码类型.
content 则是保存的元素内容,它是optional 类型表示是这个字段是可选的.当content 是很小的整数时,他会内联到 encoding 字段的尾部.
quicklist 快速列表
quicklist 是 ziplist 和链表的混合体.下面是 quicklist和 node 的部分数据结构:
struct quicklist{
quicklistNode* head; //指向头结点
quicklistNode* tail; //指向尾节点
long count; //元素总数
int nodes; //quicklistNode节点的个数
int compressDepth; //压缩算法深度
...
}
复制代码
为了节约空间 Redis 还会对 ziplist 使用 LZF 算法进行压缩,可以选择压缩深度.我们待会在说.
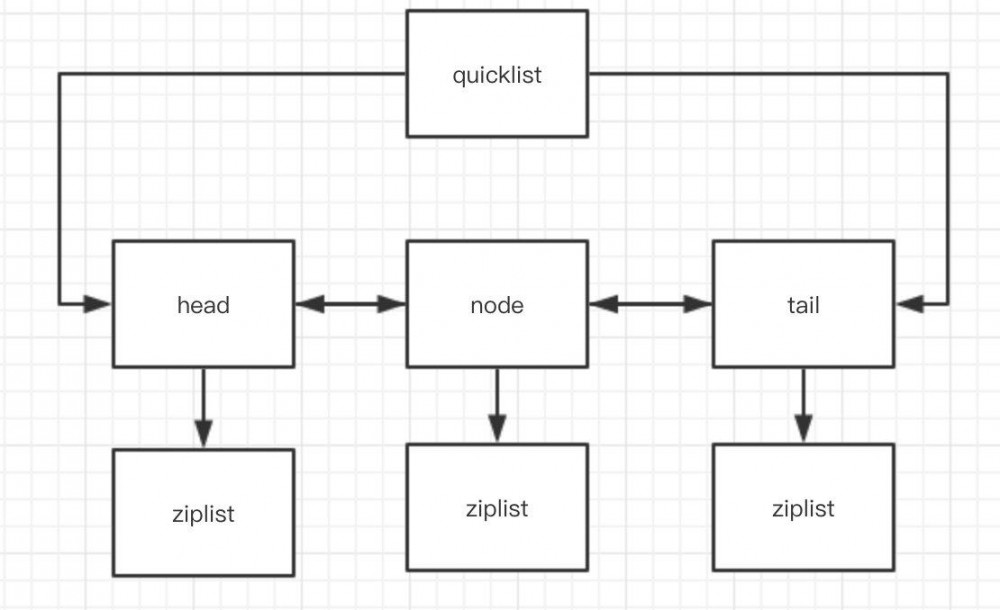
如上图所示,quicklist含有两个 quicklistNode 代表头结点和尾节点,其中每个head 和 tail 之间是双向链表.每个quicklistNode指向一个 ziplist.
struct quicklistNode{
quicklistNode* prev; //前一个节点
quicklistNode* next; //后一个节点
ziplist* zl; //压缩列表
int32 size; //ziplist大小
int16 count; //ziplist 中元素数量
int2 encoding; //编码形式 存储 ziplist 还是进行 LZF 压缩储存
...
}
复制代码
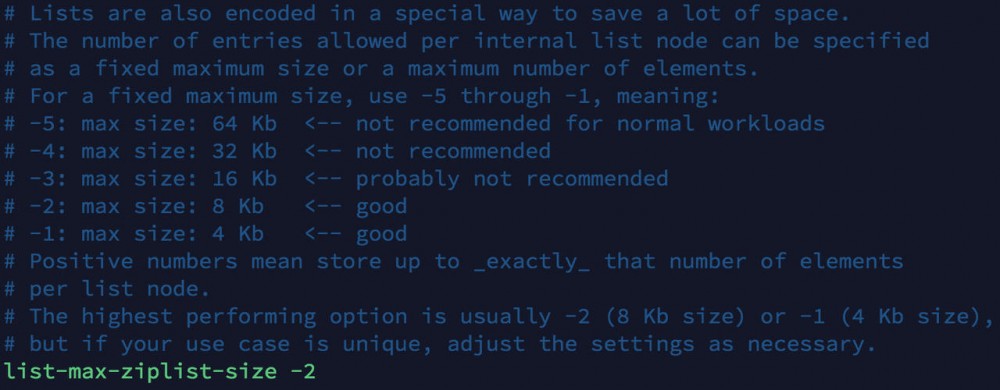
在 quicklist 中每个 ziplist 默认大小是 8kb,超出这个字节就会增加一个 ziplist.这个默认大小是可配置的,由 list-max-ziplist-size 决定.
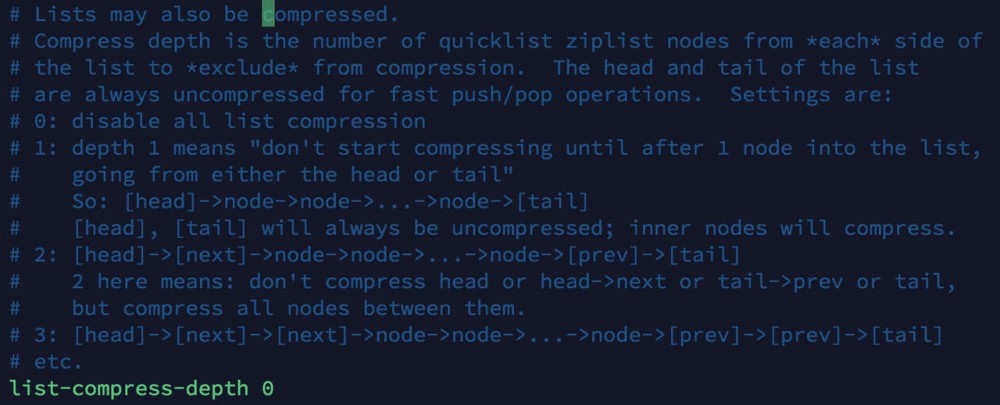
上面说到 ziplist 可以使用 LZF 算法压缩,通过 list-compress-depth 配置.默认情况下quicklist 的压缩深度是 0,也就是不压缩.配置为 1 的话代表从头/尾开始第 1 个ziplsit 进行压缩.
下章预告,Redis 数据结构之 Hash
正文到此结束
热门推荐










相关文章

近期评论
-
你这基本没有更新呀,最近文章显示还是2019年的文章。不符合要求哈
-
关键词:慕云博客 链接:https://www.lilun.me 描述:分享原创文字的个人博客
-
-
-
可以提供一下源码吗
-
不是商业站,鸡娃学习笔记
-
-
-
-
听他们说很厉害的样子
Loading...
![[HBLOG]公众号](http://www.liuhaihua.cn/img/qrcode_gzh.jpg)

