《大型网站系统与Java中间件》读书笔记(上)
前言
只有光头才能变强。
文本已收录至我的GitHub仓库,欢迎Star: https://github.com/ZhongFuCheng3y/3y
这本书买了一段时间了,之前在杭州没带过去,现在读完第三章,来做做笔记

这本书前三章都在 科普和回顾 中间件/分布式的基础,讲得非常通俗易懂。在之前已经我写过基础分布式相关文章,大家可以先去看看:
- 外行人都能看懂的SpringCloud,错过了血亏!
- 什么是ZooKeeper?
- 什么是消息队列?
- 什么是单点登录(SSO)
一、为什么分布式?
在之前的文章( 外行人都能看懂的SpringCloud,错过了血亏! )也提过为什么要分布式:
- 模块之间独立,各做各的事, 便于扩展,复用性高
- 高吞吐量 。某个任务需要一个机器运行10个小时,将该任务用10台机器的分布式跑(将这个任务拆分成10个小任务),可能2个小时就跑完了
在书上给出的观点:
- 升级单机的处理能力的性价比越来越低,单机的处理能力存在瓶颈
- 分布式系统 更加稳定和可用 (单机挂了就挂了,分布式挂了一般还有备用/不至于整个链路全挂)
1.1 大型网站架构演进过程
其实在没接触过分布式之前,在逛论坛的时候,经常会出现一些 看起来 很牛逼的词,诸如”读写分离“、”分库分表“、”主从架构“、”负载均衡“、”单点故障“等等名词,就觉得很高大上。下面我就稍微顺着”大型网站架构演进过程“来讲解一下这些词
在我们最开始接触Java项目的时候,一般来说是单机的(数据库、Web服务器都是同一台机器)
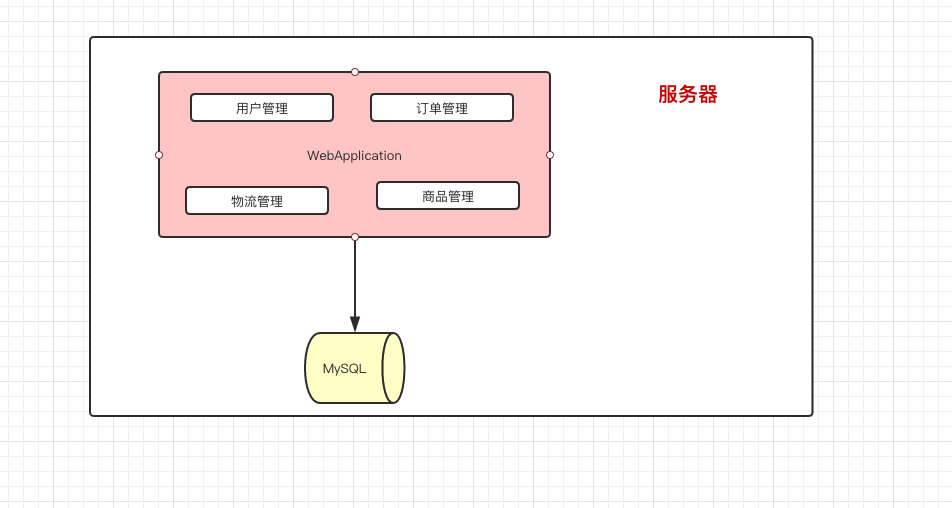
网站对外开放以后,访问量增大,服务器的压力也随之提高。此时,我们最简单的做法就是可以将 数据库和应用分开 ,这样可以缓解一下当前系统的压力
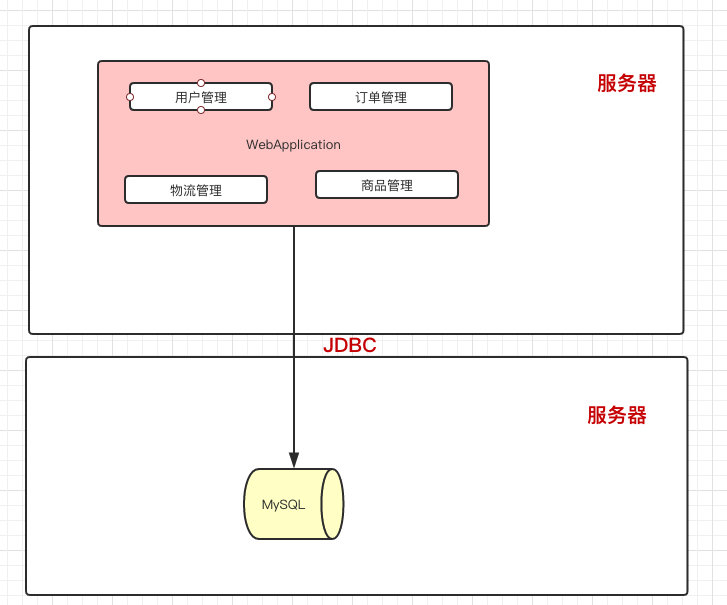
应用服务器的压力继续增大,我们可以把应用服务器做成集群(说白了,就是加了台机器)
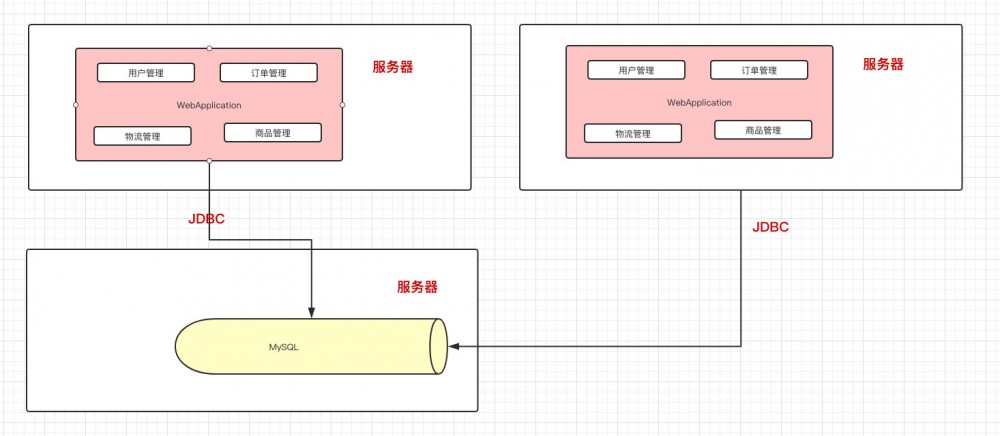
加了台应用服务器以后,就出现 新的 问题了:
- 用户请求的时候,走哪台服务器啊?
- Session是依赖单台服务器的,那Session怎么搞?
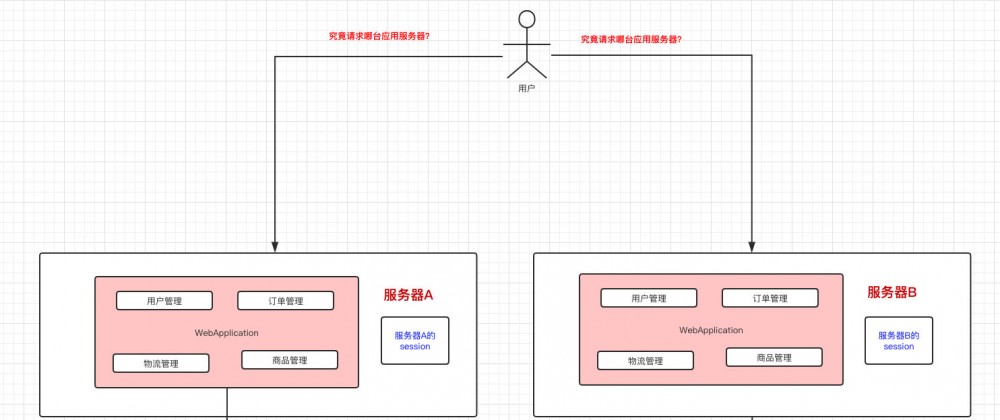
解决用户走哪台服务器,我们就在用户请求到达应用服务器之前,加了一个”负载均衡器“,这个”负载均衡器“说白了就写了 用户请求会到哪台应用服务器的逻辑
- 比如说,一个用户请求过来,负载均衡器指派这个请求到服务器A。另一个用户请求过来,负载均衡器指派这个请求到服务器B。这样就 平摊 了请求— 这种方式就叫做 轮询
- ...策略还有很多种,就看你想怎么实现了,反正这个逻辑的代码放在负载均衡器上。
而Session的问题,我之前写 什么是单点登录(SSO) 已经讲过了,一般来说我们可以将Session保存在Redis上就行了。
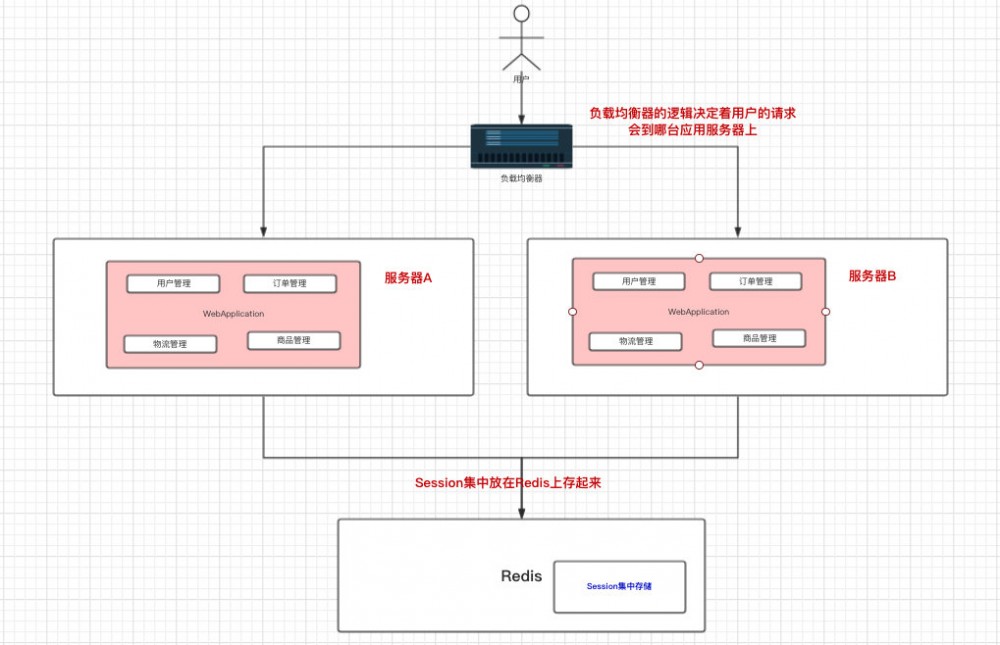
随着业务的发展,我们的数据量和访问量都在增长,现在有不少的业务都是 读多写少 的,对于这种业务也是会直接反应到 数据库 上。
于是,我们可以增加一个 读库 。写入的操作走服务器C的MySQL,读取的操作走服务器D的MySQL。这样就实现了 读写分离 。
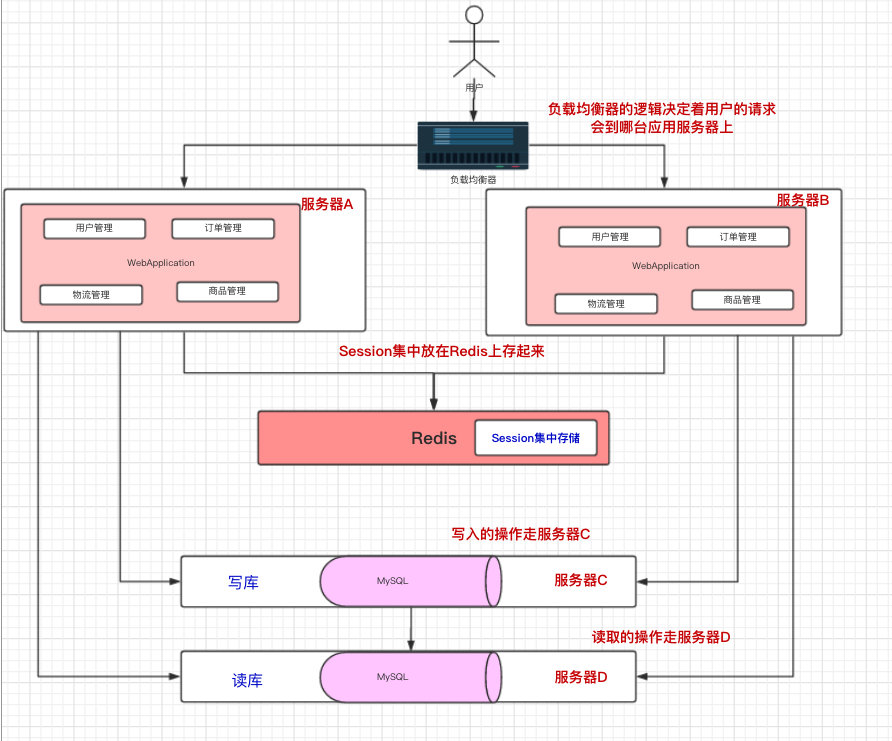
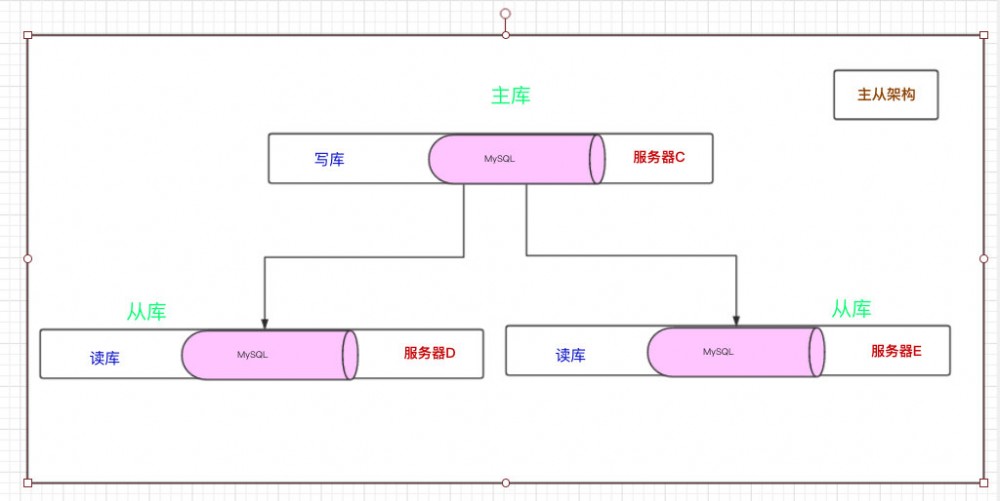
一般来说,我们的写库也叫做主库,读库也叫做从库,在互联网架构中,这叫做 主从架构 ,比如常见的架构: 一主多从 (详细的参考资料: 如何给老婆解释什么是 Master-Slave )
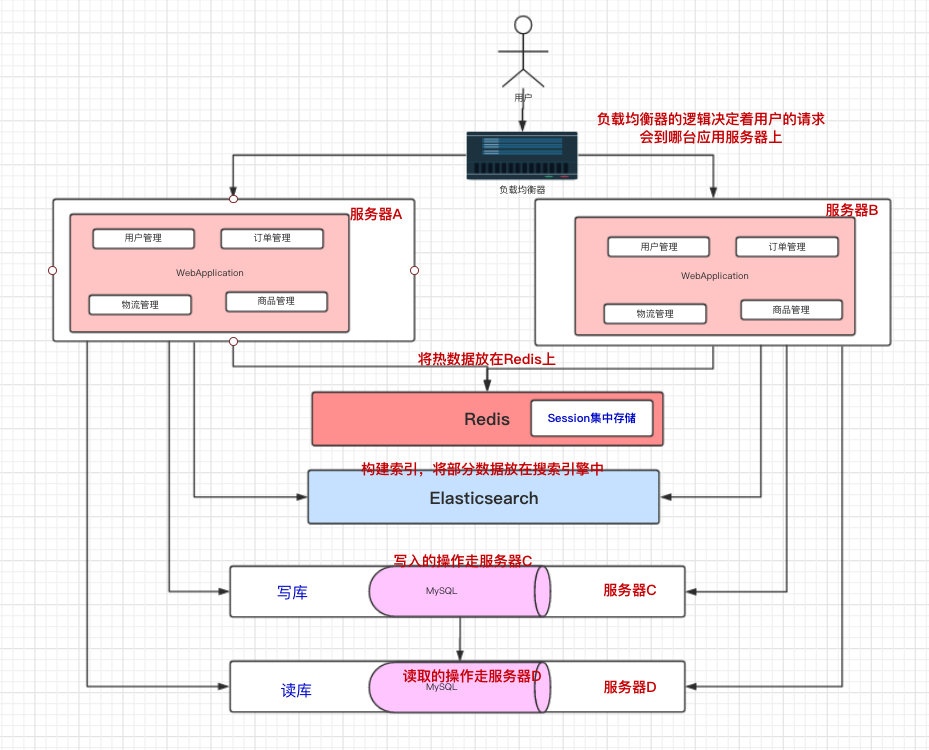
针对读多写少的业务,我们还有优化策略,引入 搜索引擎和缓存 。
- 搜索引擎也相当于一个读库,使用搜索引擎的 倒排表 方式,能够大大提升检索的速度
- 缓存则将 热数据 放入内存中,如果查询的数据在缓存中存在,则直接返回
搜索引擎和缓存的参考资料:
- Redis合集
- 什么是Lucene
- Elasticsearch入门
注:这里说的索引和缓存就未必特指ES和Redis,比如缓存我也可以用本地缓存而不一定是Redis的。这里用Redis和ES只是我画图方便。
继读写分离之后,数据库还是遇到了瓶颈,此时我们就可以采用 分库分表 策略了:
- 垂直拆分— 不同的业务数据分到不同的数据库
- 水平拆分— 将同一张表的数据拆分到不同的数据库中(原因是这张表的数据量/更新量太大了)
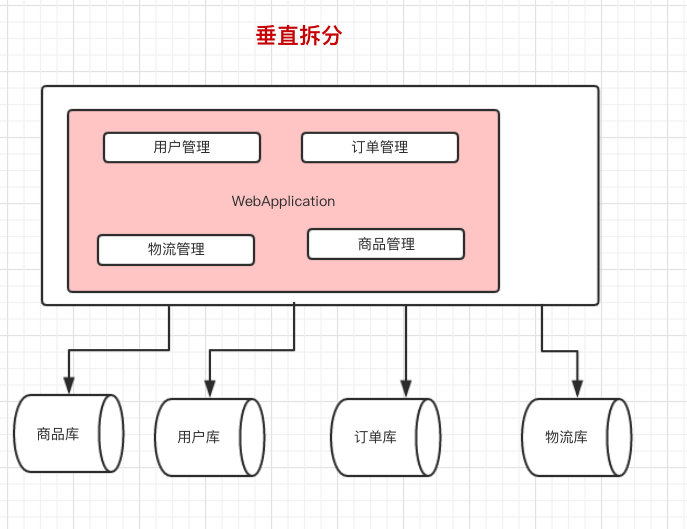
注:单表行数 超过500万行或者单表容量超过2GB 才推荐进行 分库分表 (如果预计三年都达不到这个数据量,不要在创建表的时候就分库分表!) —《阿里巴巴 Java开发手册》
在数据存储方面,除了关系型数据库之外,如果有别的业务场景,可能还需要引入 分布式存储系统
- 分布式文件系统
- 分布式Key-Value系统
- 分布式数据库
数据库问题解决之后,应用也面临着挑战(应用的功能会越做越多,应用也随之越做越大),为了不让应用持续变大,这就需要 把应用拆开 ,从一个应用变为两个/多个应用。
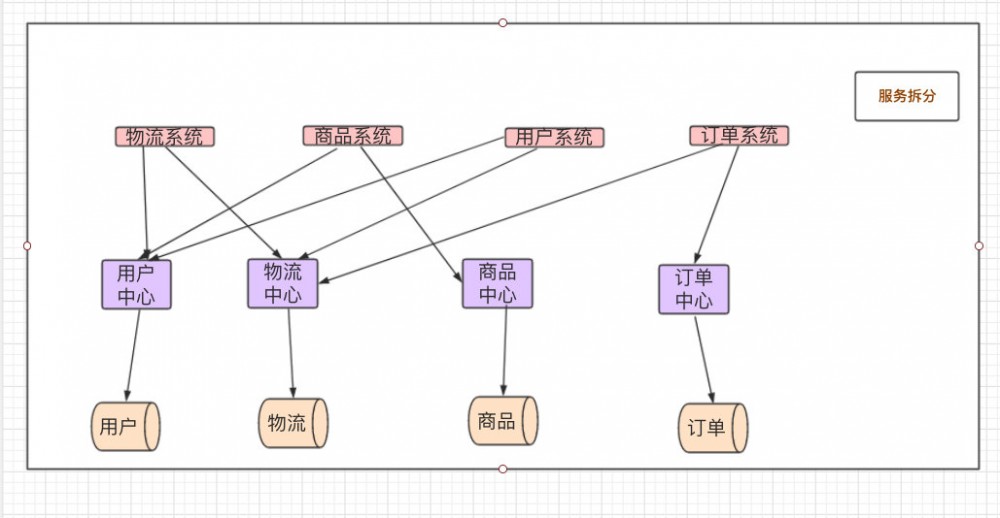
不同功能/模块之间的调用不再单纯通过本机调用,引入了 远程的服务调用 。
某个应用只有一台机器上运行着,如果这台机器上出现了问题,导致这个应用无法运行,这就叫 单点故障 。
最后
这本书《大型网站系统与Java中间件》的前三章主要是铺垫什么是中间件、什么是分布式(从单机演进到分布式的过程)以及讲述了网站的架构演进过程,剩下的是回顾一些基础。比如说:
- bio/nio/aio
- HTTP/Session
- JVM
- Java多线程以及并发的基础知识
- JUC包下的常见类
这些我都曾经多多少少都做过笔记,不妨在我的公众号下找找相关的文章。总的来说,还是读得很过瘾的!后面读完下面的章节,我会继续分享,敬请期待。
乐于输出 干货 的Java技术公众号: Java3y 。公众号内 有200多篇原创 技术文章、海量视频资源、精美脑图, 关注即可获取!

觉得我的文章写得不错,点 赞 !
正文到此结束
- 本文标签: 并发 java 数据库 zookeeper 时间 文章 分布式系统 缓存 spring tar 阿里巴巴 代码 http Elasticsearch mysql 集群 GitHub src 分布式 AIO 负载均衡 搜索引擎 多线程 开发 Master BIO https 网站 redis 架构演进 文件系统 JVM git 互联网 数据 value 主从架构 索引 服务器 压力 UI key IO session 分布式文件系统 web 线程 sql 消息队列 NIO springcloud
- 版权声明: 本文为互联网转载文章,出处已在文章中说明(部分除外)。如果侵权,请联系本站长删除,谢谢。
- 本文海报: 生成海报一 生成海报二
热门推荐










相关文章






Loading...
![[HBLOG]公众号](http://www.liuhaihua.cn/img/qrcode_gzh.jpg)

