ThreadDump分析笔记(一) 解读堆栈
线程堆栈也就是所谓的线程调用栈(都是独立的),在Java线程堆栈式JVM线程状态的一个瞬时快照,快照包含了当前时刻所有线程的运行状态,包括每一个线程的调用栈,锁的持有等信息。每个虚拟机都提供了Thread Dump的后门帮助我们导出堆栈信息。借助线程堆栈会帮助我们迅速地缩小问题的范围, 找到突破口, 命中目标 。
线程堆栈一般包含的信息:1、线程名字,ID,线程的数量 2、线程运行状态、锁的状态(锁被哪个线程持有,哪个线程在等待) 3、函数调用层级关系。包括了完整类名,方法名,源代码行数
线程堆栈信息的多少,依赖于你系统的复杂度,借助堆栈信息,可分析很多问题,如线程死锁、锁竞争、死循环、识别耗时操作等。在多线程场景下进行稳定问题分析和性能分析他是最有效的方法,多数情况甚至无需了解系统就可以进行相应分析。
当然,线程堆栈也不是万能的,因为其是瞬时快照,所以对已消失没有留下痕迹的信息,是无法追踪历史的。这种情况只能借助于监控系统和日志进行分析。如连接池中的连接被哪些线程使用了没有被释放这类问题。其实也就是说线程堆栈分析的都是非功能性的问题。
线程堆栈善于分析以下问题:1、系统无缘无故CPU过高 2、系统挂起,无响应 3、系统运行越来越慢 4、线程死锁、死循环、饿死等。 5、由于线程数量太多导致系统失败(如无法创建线程等)
输出堆栈1、unix/Linux 使用kill -3 pid 进行转储 2、可以使用VisualVM等直接查看转储 3、JDK1.5以上的可以使用Thread.getStackTrace() 控制堆栈自动打印
2. 关于线程
只有实际操作了你才能更加的理解其概念,上一个DEMO
/**
* Created by QIANG on 2017/9/29
*/
public class ThreadTest {
Object obj1 = new Object();
Object obj2 = new Object();
public void fun1(){
synchronized (obj1){
fun2();
}
}
public void fun2(){
synchronized (obj2){
while (true){
System.out.println("我要一直跑跑跑。。。");
}
}
}
public static void main(String[] args){
ThreadTest aa = new ThreadTest();
aa.fun1();
}
}
复制代码
这里我是用VisualVM 打印线程堆栈,在完整的堆栈信息中我们可以看到各种系统线程,限于篇幅原因只留下我关注的信息
2017-10-19 10:46:09
Full thread dump Java HotSpot(TM) 64-Bit Server VM (25.144-b01 mixed mode):
"main" #1 prio=5 os_prio=0 tid=0x0000000002737000 nid=0x5d1c runnable [0x000000000270f000]
java.lang.Thread.State: RUNNABLE
at java.io.FileOutputStream.writeBytes(Native Method)
at java.io.FileOutputStream.write(FileOutputStream.java:326)
at java.io.BufferedOutputStream.flushBuffer(BufferedOutputStream.java:82)
at java.io.BufferedOutputStream.flush(BufferedOutputStream.java:140)
- locked <0x0000000081e1c728> (a java.io.BufferedOutputStream)
at java.io.PrintStream.write(PrintStream.java:482)
- locked <0x0000000081e1c0a0> (a java.io.PrintStream)
at sun.nio.cs.StreamEncoder.writeBytes(StreamEncoder.java:221)
at sun.nio.cs.StreamEncoder.implFlushBuffer(StreamEncoder.java:291)
at sun.nio.cs.StreamEncoder.flushBuffer(StreamEncoder.java:104)
- locked <0x0000000081e1c058> (a java.io.OutputStreamWriter)
at java.io.OutputStreamWriter.flushBuffer(OutputStreamWriter.java:185)
at java.io.PrintStream.write(PrintStream.java:527)
- eliminated <0x0000000081e1c0a0> (a java.io.PrintStream)
at java.io.PrintStream.print(PrintStream.java:669)
at java.io.PrintStream.println(PrintStream.java:806)
- locked <0x0000000081e1c0a0> (a java.io.PrintStream)
at com.ecej.test.Thread.ThreadTest.fun2(ThreadTest.java:21)
- locked <0x0000000081e0a300> (a java.lang.Object)
at com.ecej.test.Thread.ThreadTest.fun1(ThreadTest.java:14)
- locked <0x0000000081e1c0c0> (a java.lang.Object)
at com.ecej.test.Thread.ThreadTest.main(ThreadTest.java:28)
Locked ownable synchronizers:
- None
"VM Thread" os_prio=2 tid=0x0000000017928800 nid=0x3160 runnable
"VM Periodic Task Thread" os_prio=2 tid=0x000000001a2d8000 nid=0x3dac waiting on condition
复制代码
线程堆栈是从下往上看,借助这些信息当前系统做了什么就一目了然了。从main线程堆栈看出, - locked <0x0000000081e1c0c0> (a java.lang.Object) 这句代表该线程已经占有锁,锁ID为0x0000000081e1c0c0,这个ID是系统自动生成的,只需要知道每次打印堆栈同一ID表示同一个锁就行了。
分析下堆栈第一行信息"main" (线程名字)#1 prio=5(线程优先级) os_prio=0 tid=0x0000000002737000(线程ID) nid=0x5d1c(线程对应本地线程ID) runnable(线程状态) [0x000000000270f000](线程占用内存地址)
nid=0x5d1c(线程对应本地线程ID) 这个大家看的有点懵逼,因为java我们开启一个线程就必然对应JVM中一个本地线程,也就是说本地线程数和java线程堆栈线程数相同。 在linux下我们可以使用以下方式:
- 使用ps -ef | grep java 获得Java进程ID。
- 使用pstack 获得Java虚拟机的本地线程的堆栈6。
如获得Thread 8 (Thread 4067802000 (LWP 3356)),其中Thread 4067802000 (LWP 3356)都是表示为本地线程ID。这里LWP 就对应了ThreadDump中的nid(native thread id ),只是nid用的是16进制表示的。分析得知,java线程和本地线程是同一个东西,本地线程才是真正的线程实体。
继续分析标识,其中“runable”表示当前线程处于运行状态。这个runable标识只能表示在JVM中此线程处于运行状态,熟悉线程的同学一定知道,此状态不代表真的在消耗PU。处于Runable的线程只能说明该线程没有被阻塞在java的wait/sleep上,也没有等待在锁上。但如果该线程调用了本地方法,而本地方法处于等待状态,那JVM是不知道本地代码中发生了什么,尽管当前线程实际处于阻塞状态,但实际显示出来的还是runable状态,这种情况不消耗CPU。看个例子:
java.lang.Thread.State: RUNNABLE
at java.net.SocketInputStream.socketRead0(Native Method)
复制代码
在实际中socket的本地方法大多数时间是阻塞的,除非缓冲区有数据。因此我们在分析哪个线程在消耗大量CPU时, 不能以这个"runnable"字样作为判断该线程是否消耗CPU的依据。 我们常在线程堆栈中发现".init"或者".clinit"字样的函数, 比如下面得信息 at java.util.logging.LogManager.(LogManager.java:156)
“.”表示当前正在执行类的初始化。“”正在执行对象得构造函数。下面说下两种初始化:
类初始化:编译器把类的变量初始化语句和类型得静态初始化器都收集到cllinit方法内,只能由JVM调用并保证线程安全。再初始化前必须保证其超类已经被初始化。
并非所有的类都会拥有一个() 方法, 在以下条件中该类不会拥有() 方法: • 该类既没有声明任何类变量, 也没有静态初始化语句; • 该类声明了类变量, 但没有明确使用类变量初始化语句或静态初始化语句初始化; • 该类仅包含静态final 变量的类变量初始化语句, 并且类变量初始化语句是编译时常量表达式
说白话一点就是类是初始化静态变量的,final static 直接进常量池了,不在此步骤。这一阶段其实就是类加载的最后一阶段。对象的初始化是代表了此对象生命周期的开始,只是调用了构造方法包括其里面的内容。
3. 关于锁
在进行堆栈解读前再了解下锁的基本常识,大家都知道wait()/sleep()的重大区别吧。相同点就是都释放CPU,不同点就是wait()释放锁而sleep()不释放。
从上边例子的堆栈信息可以看出锁的重要信息: 1、当一个线程占有一个锁时,线程堆栈会打印 - locked <0x0000000081e06858> (a java.io.InputStreamReader) 2、当一个线程正在等待其它线程释放该锁, 线程堆栈中会打印—waiting to lock <0x0000000081e06858> 3、当一个线程占有一个锁, 但又执行到该锁的wait()上, 线程堆栈中首先打印locked,然后又会打印—waiting on <0x0000000081e06858>
从解读中可以看出锁有三个重要的特征字:locked,waiting to lock,waiting on,了解这三个特征字, 就能够对锁进行分析了 。大多数是有一个 -—waiting to lock就必然有一个locked,当然有时候你也会找不到locked,因为一个线程释放锁和另一个线程被唤醒有一个空窗期,这时候转储就会发生此种情况。
4. 关于状态
借助堆栈可以分析很多类型问题,CPU消耗分析是堆栈的一个重要内容,先看下java的线程流转图(图来源于网络)
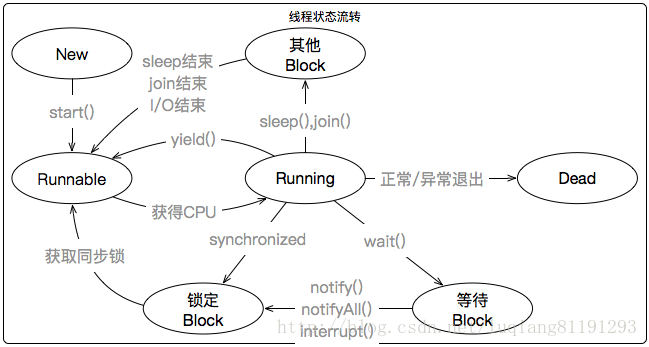
下面说下堆栈中的线程状态
RUNABLE 从JVM来说,此状态就是线程正在运行,但是咧,实际上他不一定消耗CPU,有可能是正在进行网络IO,此时线程大多数是被挂起的,只有当数据到达后,线程才会重新被唤醒,挂起发生在本地代码(Native)中,JVM其实根本就不知道(可不是调用wait/sleep)。
来个例子,下面的堆栈表示了当前程序正在从网络读取数据。
Thread-39" daemon prio=1 tid=0x08646590 nid=0x666d runnable [5beb7000..5beb88b8] java.lang.Thread.State: RUNNABLE at java.net.SocketInputStream.socketRead0(Native Method) 复制代码
下面这个堆栈表示了线程实实在在的在消耗CPU
"Thread-444" prio=1 tid=0xa4853568 nid=0x7ade runnable [0xafcf7000..0xafcf8680] java.lang.Thread.State: RUNNABLE at org.apache.commons.collections.ReferenceMap.getEntry(Unknown Source) at org.apache.commons.collections.ReferenceMap.get(Unknown Source) 复制代码
TIMED_WAITING(on object monitor) 表示当前线程被挂起一段时间,正在执行obj.wait(int time)方法
"JMX server connection timeout 16" #16 daemon prio=5 os_prio=0 tid=0x000000001a59f000 nid=0x5a74 in Object.wait() [0x000000001b7df000]
java.lang.Thread.State: TIMED_WAITING (on object monitor)
at java.lang.Object.wait(Native Method)
- waiting on <0x0000000081f218e0> (a [I)
at com.sun.jmx.remote.internal.ServerCommunicatorAdmin$Timeout.run(ServerCommunicatorAdmin.java:168)
- locked <0x0000000081f218e0> (a [I)
at java.lang.Thread.run(Thread.java:748)
复制代码
TIMED_WAITING(sleeping) 表示当前线程被挂起一段时间,即正在执行Thread.sleep(intt ime)方法
"Comm thread" daemon prio=10 tid=0x00002aaad4107400 nid=0x649f waiting on condition [0x000000004133b000..0x000000004133ba00] java.lang.Thread.State: TIMED_WAITING (sleeping) at java.lang.Thread.sleep(Native Method) at org.apache.hadoop.mapred.Task$1.run(Task.java:282) at java.lang.Thread.run(Thread.java:619) 复制代码
TIMED_WAITING(parking) 当前线程被挂起一段时间,即正在执行Thread.sleep(int time)方法 ,就是执行本地方法的sleep
"RMI TCP" daemon prio=6 tid=0x0ae3b800 nid=0x958 waiting on condition [0x17eff000..0x17effa94] java.lang.Thread.State: TIMED_WAITING (parking ) 复制代码
WAINTING(on object monitor) 当前线程被挂起, 即正在执行obj.wait()方法 (无参数的wait()方法)
"IPC Client" daemon prio=10 tid=0x00002aaad4129800 nid=0x649d in Object.wait() [0x039000] java.lang.Thread.State: WAITING (on object monitor) at java.lang.Object.wait(Native Method) 复制代码
SO,处于TIMED_WAITING、 WAINTING状态的线程一定不消耗CPU. 处于RUNNABLE的线程, 要结合当前线程代码的性质判断, 是否消耗CPU. • 如果是纯Java运算代码, 则消耗CPU. • 如果是网络IO,很少消耗CPU. • 如果是本地代码, 结合本地代码的性质判断(可以通过pstack/gstack获取本地线程堆栈),如果是纯运算代码, 则消耗CPU, 如果被挂起, 则不消耗CPU,如果是IO,则不怎么消耗CPU。
小结:此次从线程、锁、状态这三方面做了基础概念的笔记整理,下面将结合实际问题进行分析。

正文到此结束
- 本文标签: 多线程 final ACE JVM unix 线程 数据 锁 CPU过高 java线程 Hadoop grep UI 缩小 生命 id 编译 map 参数 http Collection apache 突破 安全 Collections ask IO stream java https TCP src NIO 连接池 rmi ip apr 时间 client 自动生成 synchronized linux mina cat 代码 Connection Logging 构造方法 remote 进程
- 版权声明: 本文为互联网转载文章,出处已在文章中说明(部分除外)。如果侵权,请联系本站长删除,谢谢。
- 本文海报: 生成海报一 生成海报二
热门推荐










相关文章

近期评论
-
你这基本没有更新呀,最近文章显示还是2019年的文章。不符合要求哈
-
关键词:慕云博客 链接:https://www.lilun.me 描述:分享原创文字的个人博客
-
-
-
可以提供一下源码吗
-
不是商业站,鸡娃学习笔记
-
-
-
-
听他们说很厉害的样子
Loading...
![[HBLOG]公众号](http://www.liuhaihua.cn/img/qrcode_gzh.jpg)

