优雅的使用WebMagic框架写Java爬虫
优雅的使用WebMagic框架,爬取唐诗别苑网的诗人诗歌数据
同时在几种动态加载技术(HtmlUnit、PhantomJS、Selenium、JavaScriptEngine)中对比作选择
WebMagic虽然差不多两年没有维护,但其本身是一个优秀的爬虫框架的实现,源码中有很多值得参考的地方,特别是对爬虫多线程的控制。另外,由于页面爬取到的是非结构化数据,所以数据保存到MongoDB。
技术准备
- IDE:IntelliJ IDEA 2018.3.5
- JDK版本:1.8.0_181
- 数据库:MongoDB 4.0.10
-
涉及技术:
- Webmagic轻量级爬虫框架
- HtmlUnit网页分析工具包,模拟浏览器运行
- PhantomJS
- JavaScriptEngine
- MongoDB ORM框架 Morphia
- JUC:Java线程池、线程协作、线程安全类
- 日志log4j 1.7.25
- Java反射
- 单例模式、工厂模式、代理模式
pom.xml文件中的依赖非常简单,并没有使用到Spring系列的框架,所以有些地方自己编码实现了Spring提供的功能
项目结构
- biz包:包括页面爬取逻辑的Processor类,爬虫结果保存的Pipeline类
- dao包:数据获取层
- entity包:实体类,映射保存在MongoDB的文档(Document)
- vo包:值对象,简单的Java对象
- util包:工具包,包括数据库连接类、爬虫辅助类
- common包:项目相关通用类
- Main类:程序入口
项目说明
根据需求将数据保存到MongoDB数据库,因此 在程序运行前必须设置好 resources/mongodb.properties 文件
最好保证MongoDB的版本是4.0以上。另外MongoDB的用户管理比较麻烦,过程大致如下:首先需要创建存储数据的数据库,如命名为user_tangpoem,并存入随便一条数据(集合)使数据库有效化,然后创建一个
admin数据库的root用户,继续创建一个可以读写应用数据库user_tangpoem的用户,然后修改MongoDB配置文件使其以安全认证模式启动。重启数据库,选择admin数据库(use admin)
用刚刚创建的用户(非root用户)使用db.auth()进行登录,返回1说明验证成功,选择user_tangpoem数据库(use user_tangpoem),输入show collections,如果看到最初创建数据库时的集合,则说明用户创建成功。
详细可参考 MongoDB4.0.0 远程连接及用户名密码认证登陆配置——windows
爬虫以多线程的方式运行,在 resources/spider.properties 文件中可以 设置线程数和线程睡眠时间 ,在设置好数据库配置的基础上,直接运行Main.main(),爬虫就会开始爬取。
线程睡眠,是WebMagic框架源码中每线程爬取完一个url后必然经历的过程,但作者文档并没有对此进行说明,请根据实际情况调整
动态加载技术的选择
1. PhantomJS和Selenium
WebMagic底层已经很好的使用了HttpClient加载静态页面,对于动态页面,也有 PhantomJSDownloader 和 SeleniumDownloader 两个常用的利用
浏览器内核模拟浏览器行为的实现,其中,PhantomJS需要指定phantomjs.exe和进行爬取的JS文件,而seleniumDownloader需要指定chromedriver.exe,需要自行下载对应操作系统的版本,
使用起来并不难,本项目不多作讨论。这里关键说明 HtmlUnit
2. HtmlUnit
一款开源的Java页面分析工具,读取页面后,可以有效的使用HtmlUnit分析页面上的内容。使用 纯Java实现的 模拟浏览器,不需要指定外部文件。
虽然其对JS的支持并不完全,但总体而言HtmlUnit的内存消耗、CPU消耗和效率都比PhantomJS和Selenium好,值得进行使用
本项目使用2.25版本的HtmlUnit并没有出现JS加在不成功的问题,但使用2.3x的版本会无法加载
3. JavaScriptEngine
- 既然要加载JS,为何不直接提取JS代码,使用Java自带的JS引擎处理呢?
因为 JavaScriptEngine是有局限性的 ,最明显就是其不支持jquery的语法,因为jquery使用了浏览器内置的对象,而JS引擎本身是没有浏览器对象的
- 那还能使用JS引擎吗?
当然可以,只要分析过页面的加载逻辑,如果不涉及浏览器对象的使用,或者将JS逻辑进行转化,还是能够使用JS引擎的,但 牺牲了泛用性 。本项目经分析后使用JS引擎加载
4. 横向对比
经过测试,三者比较如下
- 加载一个接口的效率:PhantomJS约13秒,HtmlUnit约10秒,JS引擎约6秒
- 内存消耗、CPU消耗:PhantomJS > HtmlUnit > JS引擎
PhantomJS使用外置的程序,所以JVM无法管理这部分的硬件资源,需要打开任务管理器
爬取过程
经过分析,爬取步骤分为4步:
- 爬取所有的诗人id。调用一次接口即可获得所有的诗人id,返回JSON格式数据,接口地址为: http://poem.studentsystem.org...
- 爬取所有的诗人信息。根据上一步的诗人id逐一爬取对应的诗人详细信息,一共有 2529 条数据,则接口调用 2529 次,返回JSON格式数据,接口地址为: http://poem.studentsystem.org... {id}
- 爬取所有的诗歌信息。根据上一步的诗人信息获取所有的诗歌id,然后逐一调用接口获取诗歌详细信息,一共有约 48000 条数据,则接口调用 48000 次,返回html页面,需要模拟浏览器动态执行JS,接口地址为: http://poem.studentsystem.org... {id}
- 由于动态执行JS可会能超时,因此最后要处理未成功加载完毕的诗歌信息,从数据库中读取这类数据,再次构成url调用接口爬取,直到所有数据都完整。这类数据约占1%,则接口调用约 480 次
优化后使用Java8的nashorn JS引擎执行JS代码,不需要动态加载JS,所以不会出现4的问题
耗时估计
根据爬取过程分析,忽略程序启动时间和调用获取诗人id接口的时间
在开启8线程的并发模式下(使用HtmlUnit进行动态加载):
- 调用获取诗人信息的接口,每次需要5秒(5秒是线程内置的睡眠时间,可设置)
- 调用获取诗歌信息的接口,每次需要10秒(包含了上述的5秒)
一共需要: 2529 / 8 5 + 48000 (1 + 0.01)/ 8 * 10 ≈ 62596秒 ≈ 1043分钟 ≈ 17.4小时
上述数据是在本地测试中得到的,配置为 win10 8G i5-4210M 4核
优化后,用JS引擎取代模拟浏览器动态加载JS,获取诗歌信息的耗时明显缩短,由10秒缩短到6秒左右,因此重新计算耗时如下:
2529 / 8 5 + 48000 / 8 6 ≈ 37185秒 ≈ 620分钟 ≈ 10.3小时
性能评估
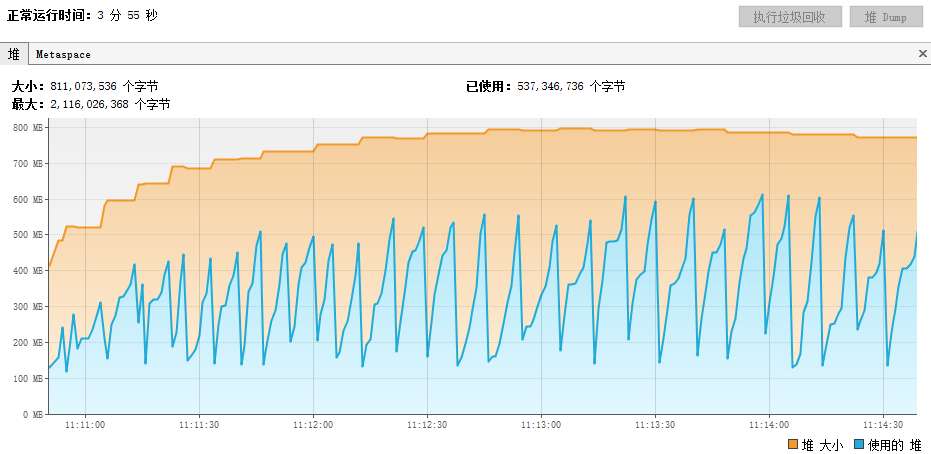
当使用模拟浏览器动态加载JS时,观察JVM的使用情况,发现爬取诗歌阶段频繁发生Minor GC(新生代GC),差不多10秒一次,如下图所示,
后判明是多线程模拟浏览器加载页面行为非常的耗内存(参考同时打开8个浏览器加载网页),对象频繁创建,频繁消耗,
建议运行时通过-Xms -Xmx把JVM内存设置得大些,至少1G,然后把新生代的比例设大,如 -Xms2048M -Xmx2048M -XX:+UseParallelOldGC -XX:NewRatio=1
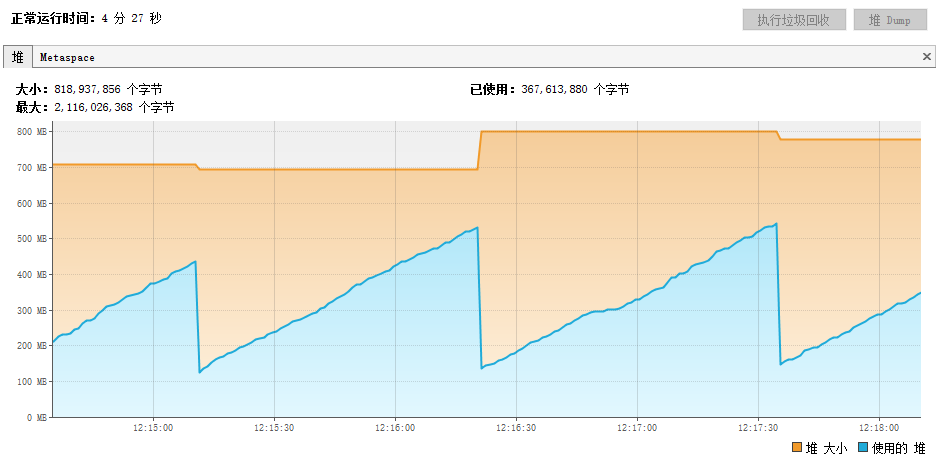
后来,用JS引擎取代模拟浏览器动态加载JS,不仅速度得到明显提升,而且内存的消耗大幅度降低,Minor GC平均1分钟发生一次,如下图所示,
最后附上GitHub项目地址: https://github.com/Kanarienvogels/spider-tangpoem
正文到此结束
- 本文标签: spring db 线程 多线程 json entity id windows 数据库 管理 Document src Collection 认证 IDE MongoDB client IO 并发 源码 js 数据 HTML 开源 ORM zab 测试 https UI 时间 操作系统 JavaScript java反射 root git jquery 需求 Chrome 线程池 JVM web ip 配置 代码 XML 下载 java线程 java pom 安全 GitHub Collections http mongo
- 版权声明: 本文为互联网转载文章,出处已在文章中说明(部分除外)。如果侵权,请联系本站长删除,谢谢。
- 本文海报: 生成海报一 生成海报二
热门推荐










相关文章






Loading...
![[HBLOG]公众号](http://www.liuhaihua.cn/img/qrcode_gzh.jpg)

