JDK源码阅读(六):HashMap源码分析
最近很多人加我问有没有源码的资料

其实最好的就是去看官方文档,这里有一个中文在线的API文档网站可以参考,毕竟吗英语是硬伤
blog.fondme.cn/apidoc/jdk-…

为了害怕你看不到我特意把表情包字体P成红色,不逼逼了
正文开始 注:JDK版本为1.8
HashMap1.8和1.8之前的源码差别很大
- 目录
- 简介
- 数据结构
- 类结构
- 属性
- 构造方法
- 增加
- 删除
- 修改
- 总结
- 简介
1.HashMap简介
HashMap基于哈希表的Map接口实现,是以key-value存储形式存在。(除了不同步和允许使用 null 之外,HashMap 类与 Hashtable 大致相同。)
HashMap 的实现不是同步的,这意味着它不是线程安全的。它的key、value都可以为null。此外,HashMap中的映射不是有序的。在 JDK1.8 中,HashMap 是由 数组+链表+红黑树构成,新增了红黑树作为底层数据结构,结构变得复杂了,但是效率也变的更高效。
1.2 HashMap数据结构
在 JDK1.8 中,HashMap 是由 数组+链表+红黑树构成,新增了红黑树作为底层数据结构,结构变得复杂了,但是效率也变的更高效。当一个值中要存储到Map的时候会根据Key的值来计算出他的
hash,通过哈希来确认到数组的位置,如果发生哈希碰撞就以链表的形式存储 在Object源码分析中解释过 ,但是这样如果链表过长来的话,HashMap会把这个链表转换成红黑树来存储。

来看依一下HashMap的存储结构
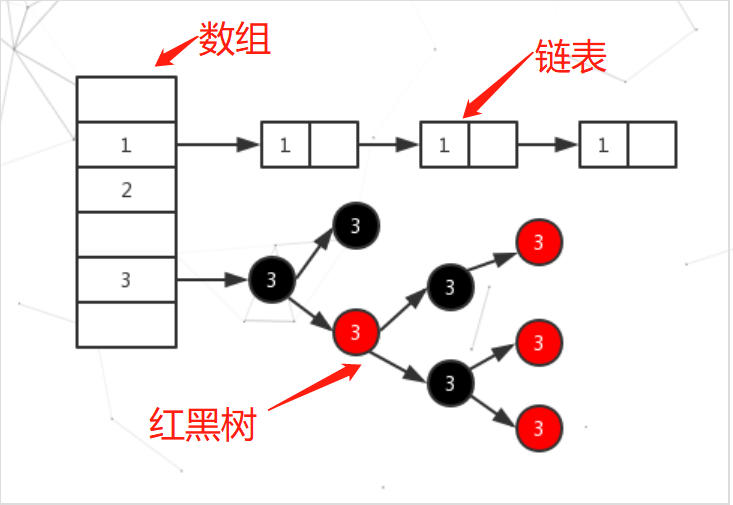
但是这样的话问题来了,HashMap为什么要使用红黑树呢,这样结构的话不是更麻烦了吗??
这个问题我也没有想过,其实很多在看的时候只会在乎红黑树的实现而忽略到了为什么要使用的这个问题,我也是在写本文的时候突发疑惑。参考了网上的例子,同时也解释了为什么阀值为8:
因为Map中桶的元素初始化是链表保存的,其查找性能是O(n),而树结构能将查找性能提升到O(log(n))。当链表长度很小的时候,即使遍历,速度也非常快,但是当链表长度不断变长,肯定会对查询性能有一定的影响,所以才需要转成树。至于为什么阈值是8,我想,去源码中找寻答案应该是最可靠的途径。
参考地址:dwz.cn/nPFXmXwJ
2.类结构
我们来看一下类结构
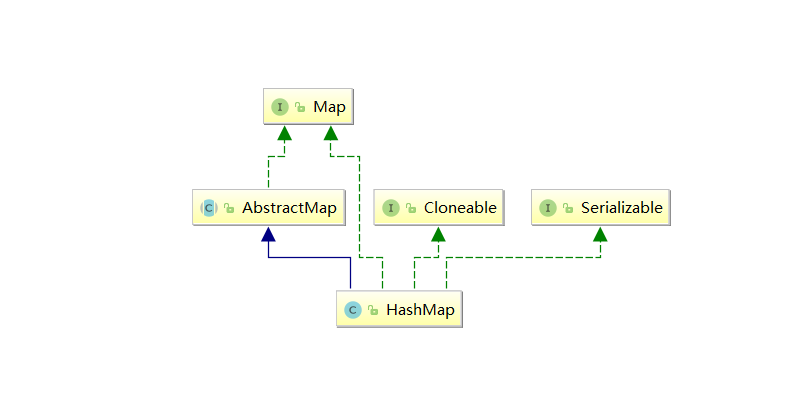
在阅读源码的时候一直有个问题很困惑就是HashMap已经继承了AbstractMap而AbstractMap类实现了Map接口,同样在ArrayList中LinkedList中都是这种结构。
据 java 集合框架的创始人Josh Bloch描述,这样的写法是一个失误。在java集合框架中,类似这样的写法很多,最开始写java集合框架的时候,他认为这样写,在某些地方可能是有价值的,直到他意识到错了。显然的,JDK的维护者,后来不认为这个小小的失误值得去修改,所以就这样存在下来了。

- Cloneable 空接口,表示可以克隆
- Serializable 序列化
- AbstractMap 提供Map实现接口
正文到此结束
热门推荐









相关文章






Loading...
![[HBLOG]公众号](http://www.liuhaihua.cn/img/qrcode_gzh.jpg)

