记一次 Java 服务性能优化
背景
前段时间我们的服务遇到了性能瓶颈,由于前期需求太急没有注意这方面的优化,到了要还技术债的时候就非常痛苦了。
在很低的 QPS 压力下服务器 load 就能达到 10-20,CPU 使用率 60% 以上,而且在每次流量峰值时接口都会大量报错,虽然使用了服务熔断框架 Hystrix,但熔断后服务却迟迟不能恢复。每次变更上线更是提心吊胆,担心会成为压死骆驼的最后一根稻草,导致服务雪崩。
在需求终于缓下来后,leader 给我们定下目标,限我们在两周内把服务性能问题彻底解决。近两周的排查和梳理中,发现并解决了多个性能瓶颈,修改了系统熔断方案,最终实现了服务能处理的 QPS 翻倍,能实现在极高 QPS(3-4倍)压力下服务正常熔断,且能在压力降低后迅速恢复正常,以下是部分问题的排查和解决过程。
转载随意,文章会持续修订,请注明来源地址: https://zhenbianshu.github.io 。
服务器高CPU、高负载
首先要解决的问题就是服务导致服务器整体负载高、CPU 高的问题。
我们的服务整体可以归纳为从某个存储或远程调用获取到一批数据,然后就对这批数据进行各种花式变换,最后返回。由于数据变换的流程长、操作多,系统 CPU 高一些会正常,但平常情况下就 CPU us 50% 以上,还是有些夸张了。
我们都知道,可以使用 top 命令在服务器上查询系统内各个进程的 CPU 和内存占用情况。可是 JVM 是 Java 应用的领地,想查看 JVM 里各个线程的资源占用情况该用什么工具呢?
jmc 是可以的,但使用它比较麻烦,要进行一系列设置。我们还有另一种选择,就是使用 jtop ,jtop 只是一个 jar 包,它的项目地址在 yujikiriki/jtop , 我们可以很方便地把它复制到服务器上,获取到 java 应用的 pid 后,使用 java -jar jtop.jar [options] <pid> 即可输出 JVM 内部统计信息。
jtop 会使用默认参数 -stack n 打印出最耗 CPU 的 5 种线程栈。
形如:
Heap Memory: INIT=134217728 USED=230791968 COMMITED=450363392 MAX=1908932608
NonHeap Memory: INIT=2555904 USED=24834632 COMMITED=26411008 MAX=-1
GC PS Scavenge VALID [PS Eden Space, PS Survivor Space] GC=161 GCT=440
GC PS MarkSweep VALID [PS Eden Space, PS Survivor Space, PS Old Gen] GC=2 GCT=532
ClassLoading LOADED=3118 TOTAL_LOADED=3118 UNLOADED=0
Total threads: 608 CPU=2454 (106.88%) USER=2142 (93.30%)
NEW=0 RUNNABLE=6 BLOCKED=0 WAITING=2 TIMED_WAITING=600 TERMINATED=0
main TID=1 STATE=RUNNABLE CPU_TIME=2039 (88.79%) USER_TIME=1970 (85.79%) Allocted: 640318696
com.google.common.util.concurrent.RateLimiter.tryAcquire(RateLimiter.java:337)
io.zhenbianshu.TestFuturePool.main(TestFuturePool.java:23)
RMI TCP Connection(2)-127.0.0.1 TID=2555 STATE=RUNNABLE CPU_TIME=89 (3.89%) USER_TIME=85 (3.70%) Allocted: 7943616
sun.management.ThreadImpl.dumpThreads0(Native Method)
sun.management.ThreadImpl.dumpAllThreads(ThreadImpl.java:454)
me.hatter.tools.jtop.rmi.RmiServer.listThreadInfos(RmiServer.java:59)
me.hatter.tools.jtop.management.JTopImpl.listThreadInfos(JTopImpl.java:48)
sun.reflect.NativeMethodAccessorImpl.invoke0(Native Method)
... ...
通过观察线程栈,我们可以找到要优化的代码点。
在我们的代码里,发现了很多 json 序列化和反序列化和 Bean 复制耗 CPU 的点,之后通过代码优化,通过提升 Bean 的复用率,使用 PB 替代 json 等方式,大大降低了 CPU 压力。
熔断框架优化
服务熔断框架上,我们选用了 Hystrix,虽然它已经宣布不再维护,更推荐使用 resilience4j 和阿里开源的 sentinel,但由于部门内技术栈是 Hystrix,而且它也没有明显的短板,就接着用下去了。
先介绍一下基本情况,我们在控制器接口最外层和内层 RPC 调用处添加了 Hystrix 注解,隔离方式都是线程池模式,接口处超时时间设置为 1000ms,最大线程数是 2000,内部 RPC 调用的超时时间设置为 200ms,最大线程数是 500。
响应时间不正常
要解决的第一个问题是接口的响应时间不正常。在观察接口的 access 日志时,可以发现接口有耗时为 1200ms 的请求,有些甚至达到了 2000ms 以上。服务正常时,这种情况对于线程池隔离方式是不可能发生的,因为线程池模式下,Hystrix 会创建一个新的线程去执行真正的业务逻辑,而主线程则一直在等待,一旦等待超时,主线程是可以立刻返回的。所以接口耗时超过超时时间,问题很可能发生在 Hystrix 框架层、Spring 框架层或系统层。
这时候可以对运行时线程栈来分析,我使用 jstack 打印出线程栈,并将多次打印的结果制作成火焰图(参见应用调试工具-火焰图)来观察。

如上图,可以看到很多线程都停在 LockSupport.park(LockSupport.java:175) 处,这些线程都被锁住了,向下看来源发现是 HystrixTimer.addTimerListener(HystrixTimer.java:106) , 而再向下就是我们的业务代码了。
Hystrix 注释里解释这些 TimerListener 是 HystrixCommand 用来处理异步线程超时的,这些 TimerListener 会在调用超时时执行,将超时结果返回。而在调用量大时,进入线程池时这些 TimerListener 的设置就会因为锁而阻塞,而这些 TimerListener 的设置被阻塞后,就会导致接口设置的超时时间不生效。
要解决这个问题,只能修改服务的隔离策略了,将 Hystrix 的隔离策略改为信号量模式。信号量模式下,Hystrix 会在每次执行 HystrixCommand 时获取一次信号量,在执行结束后还回。由于信号量的操作效率非常高,而且没有其他附加操作,所以在使用信号量隔离模式时不会有其他性能损耗。
但使用信号量隔离模式也要注意一个问题:信号量只能限制方法是否能够进入,如果可以进入执行,则在原来的主线程内执行,执行的过程中 Hystrix 是无法干预的,只能在方法返回后再判断接口是否超时并对超时进行处理,这可能会导致有部分请求耗时超长时,一直占用一个信号量,但框架却无法处理。
在修改了 Hystrix 的隔离模式后,接口的最大耗时就稳定了,而且由于方法都在主线程执行,少了 Hystrix 线程池维护和主线程与 Hystrix 线程的上下文切换,系统 CPU 使用率又有进一步下降。
服务隔离和降级
另一个问题是服务不能按照预期的方式进行服务隔离和降级,我们认为流量在非常大的情况下应该会持续熔断时,而 Hystrix 总表现为半熔断半执行,我们认为多余的请求不会进入方法内部时,它们偏偏还能被执行。
开始时,我们对日志进行观察,由于日志被设置成异步,看不到实时日志,而且有大量的报错信息干扰,过程痛苦而低效。后来得知 Hystrix 还有可视化界面后,才算找到正确的调优方式。
Hystrix 可视化模式分为服务端和客户端,服务端就是我们要观察的服务,需要在服务内引入 hystrix-metrics-event-stream 包并添加一个接口来输出 Metrics 信息。要将这些信息展示出来,只需要启动 hystrix-dashboard 客户端并填入服务端地址即可。
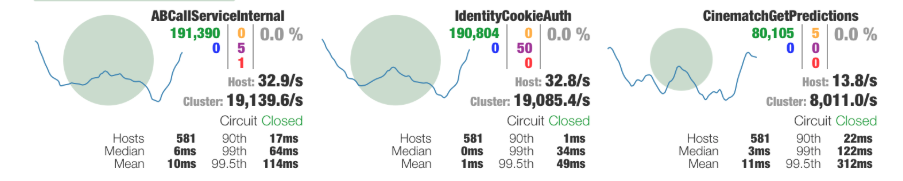
通过可视化界面,Hystrix 的整体状态就展示得非常清楚了,我们就可以根据这些状态信息对它的熔断配置进行调整了。由于上文的优化,接口的最大响应时间完全可控,可以通过严格限制接口方法的并发量来修改服务的拒绝策略了。
假设接口平均响应时间为 50ms,而服务能容纳的最大 QPS 为 2000,那么可以通过 2000*50/1000=100 得到适合的信号量限制,如果被拒绝的错误数过多,可以再添加一些冗余。
这样,在流量突变时,就可以通过拒绝一部分连接来控制进入服务的总请求数,而在进入服务的总请求里,又严格限制了平均耗时,如果错误数过多,还可以通过熔断来进行降级。多种策略同时进行,就能保证接口的平均响应时长了。
熔断时高负载导致无法恢复
接下来就要解决服务熔断时,服务负载持续升高,而在 QPS 压力降低后服务迟迟无法恢复的问题。
在服务器负载特别高时,使用各种工具来观测服务内部状态,结果都是不靠谱的,因为观测一般都采用打点收集的方式,在观察服务的同时已经改变了服务。例如使用 jtop 在高负载时查看占用 CPU 最高的线程时,获取到的结果总是 JVM TI(Java 动态字节码技术) 相关的栈。
不过,观察服务外部可以发现,这个时候会有大量的错误日志输出,往往在服务已经稳定好久了,还有之前的错误日志在打印,延时的单位甚至以分钟计。大量的错误日志不仅造成 I/O 压力,而且线程栈的获取、日志存储内存的分配都很有可能会增加服务器压力。而且我们的服务早因为日志量大而改为了异步日志,这使得通过 I/O 阻塞线程的屏障也消失了。
要验证这项猜测也很简单,修改服务内的日志记录点,在打印日志时不再打印异常栈,再重写 Spring 框架的 ExceptionHandler,彻底减少日志量的输出。
结果非常符合预期,在错误量极大时,日志输出也被控制在正常范围,这样熔断后,就不会再因为日志给服务增加压力,一旦 QPS 压力下降,熔断开关被关闭,服务很快就能恢复正常状态。
Spring 数据绑定异常
另外,在查看 jstack 输出的线程栈时,还偶然发现了一种奇怪的栈。
at java.lang.Throwable.fillInStackTrace(Native Method) at java.lang.Throwable.fillInStackTrace(Throwable.java:783) - locked <0x00000006a697a0b8> (a org.springframework.beans.NotWritablePropertyException) at java.lang.Throwable.<init>(Throwable.java:287) at java.lang.Exception.<init>(Exception.java:84) at java.lang.RuntimeException.<init>(RuntimeException.java:80) at org.springframework.core.NestedRuntimeException.<init>(NestedRuntimeException.java:66) at org.springframework.beans.BeansException.<init>(BeansException.java:50) at org.springframework.beans.FatalBeanException.<init>(FatalBeanException.java:45) at org.springframework.beans.InvalidPropertyException.<init>(InvalidPropertyException.java:54) at org.springframework.beans.InvalidPropertyException.<init>(InvalidPropertyException.java:43) at org.springframework.beans.NotWritablePropertyException.<init>(NotWritablePropertyException.java:77) at org.springframework.beans.BeanWrapperImpl.createNotWritablePropertyException(BeanWrapperImpl.java:243) at org.springframework.beans.AbstractNestablePropertyAccessor.processLocalProperty(AbstractNestablePropertyAccessor.java:426) at org.springframework.beans.AbstractNestablePropertyAccessor.setPropertyValue(AbstractNestablePropertyAccessor.java:278) at org.springframework.beans.AbstractNestablePropertyAccessor.setPropertyValue(AbstractNestablePropertyAccessor.java:266) at org.springframework.beans.AbstractPropertyAccessor.setPropertyValues(AbstractPropertyAccessor.java:97) at org.springframework.validation.DataBinder.applyPropertyValues(DataBinder.java:839) at org.springframework.validation.DataBinder.doBind(DataBinder.java:735) at org.springframework.web.bind.WebDataBinder.doBind(WebDataBinder.java:197) at org.springframework.web.bind.ServletRequestDataBinder.bind(ServletRequestDataBinder.java:107) at org.springframework.web.servlet.mvc.method.annotation.ServletModelAttributeMethodProcessor.bindRequestParameters(ServletModelAttributeMethodProcessor.java:157) at org.springframework.web.method.annotation.ModelAttributeMethodProcessor.resolveArgument(ModelAttributeMethodProcessor.java:153) at org.springframework.web.method.support.HandlerMethodArgumentResolverComposite.resolveArgument(HandlerMethodArgumentResolverComposite.java:124) at org.springframework.web.method.support.InvocableHandlerMethod.getMethodArgumentValues(InvocableHandlerMethod.java:161) at org.springframework.web.method.support.InvocableHandlerMethod.invokeForRequest(InvocableHandlerMethod.java:131) at org.springframework.web.servlet.mvc.method.annotation.ServletInvocableHandlerMethod.invokeAndHandle(ServletInvocableHandlerMethod.java:102) at org.springframework.web.servlet.mvc.method.annotation.RequestMappingHandlerAdapter.invokeHandlerMethod(RequestMappingHandlerAdapter.java:877) at org.springframework.web.servlet.mvc.method.annotation.RequestMappingHandlerAdapter.handleInternal(RequestMappingHandlerAdapter.java:783) at org.springframework.web.servlet.mvc.method.AbstractHandlerMethodAdapter.handle(AbstractHandlerMethodAdapter.java:87) at org.springframework.web.servlet.DispatcherServlet.doDispatch(DispatcherServlet.java:991)
jstack 的一次输出中,可以看到多个线程的栈顶都停留在 Spring 的异常处理,但这时候也没有日志输出,业务也没有异常,跟进代码看了一下,Spring 竟然偷偷捕获了异常且不做任务处理。
List<PropertyAccessException> propertyAccessExceptions = null;
List<PropertyValue> propertyValues = (pvs instanceof MutablePropertyValues ?
((MutablePropertyValues) pvs).getPropertyValueList() : Arrays.asList(pvs.getPropertyValues()));
for (PropertyValue pv : propertyValues) {
try {
// This method may throw any BeansException, which won't be caught
// here, if there is a critical failure such as no matching field.
// We can attempt to deal only with less serious exceptions.
setPropertyValue(pv);
}
catch (NotWritablePropertyException ex) {
if (!ignoreUnknown) {
throw ex;
}
// Otherwise, just ignore it and continue...
}
... ...
}
结合代码上下文再看,原来 Spring 在处理我们的控制器数据绑定,要处理的数据是我们的一个上下文类 ApiContext,它是由多个字段组成的参数传输 Bean。
控制器代码类似于:
@RequestMapping("test.json")
public Map testApi(@RequestParam(name = "id") String id, ApiContext apiContext) {}
按照正常的套路,我们应该为这个 ApiContext 类添加一个参数解析器(HandlerMethodArgumentResolver),这样 Spring 会在解析这个参数时会调用这个参数解析器为方法生成一个对应类型的参数。可是如果没有这么一个参数解析器,Spring 会怎么处理呢?
答案就是会使用上面的那段”奇怪”代码,先创建一个空的 ApiContext 类,并将所有的传入参数依次尝试 set 进这个类,如果 set 失败了,就 catch 住异常继续执行,而 set 成功后,就完成了 ApiContext 类内一个属性的参数绑定。
而不幸的是,我们的接口上层会为我们统一传过来三四十个参数,所以每次都会进行大量的”尝试绑定”,造成的异常和异常处理就会导致大量的性能损失,在使用参数解析器解决这个问题后,接口性能竟然有近十分之一的提升。
小结
性能优化不是一朝一夕的事,把技术债都堆到最后一块解决绝不是什么好的选择。平时多注意一些代码写法,在使用黑科技时注意一下其实现有没有什么隐藏的坑才是正解,还可以进行定期的性能测试,及时发现并解决代码里近期引入的不安定因素。
关于本文有什么疑问可以在下面留言交流,如果您觉得本文对您有帮助,欢迎关注我的微博 或 GitHub 。您也可以在我的 博客REPO 右上角点击 Watch 并选择 Releases only 项来 订阅 我的博客,有新文章发布会第一时间通知您。
正文到此结束
- 本文标签: value src 文章 Hystrix stream 测试 科技 调试 时间 json Connection ACE id QPS ssl UI 需求 解析 微博 jstack 服务端 拒绝策略 服务器 js 配置 代码 HTML 开源 博客 MQ 字节码 web https map GitHub App 性能问题 多个字段 IO JVM java git cat Google CEO 锁 http bean Dashboard spring servlet 压力 多线程 参数 统计 Property Sentinel 2019 rmi mina 进程 API TCP list core 线程池 性能优化 并发 tab 线程 数据 注释
- 版权声明: 本文为互联网转载文章,出处已在文章中说明(部分除外)。如果侵权,请联系本站长删除,谢谢。
- 本文海报: 生成海报一 生成海报二
热门推荐










相关文章

近期评论
-
你这基本没有更新呀,最近文章显示还是2019年的文章。不符合要求哈
-
关键词:慕云博客 链接:https://www.lilun.me 描述:分享原创文字的个人博客
-
-
-
可以提供一下源码吗
-
不是商业站,鸡娃学习笔记
-
-
-
-
听他们说很厉害的样子
Loading...
![[HBLOG]公众号](http://www.liuhaihua.cn/img/qrcode_gzh.jpg)

