自动驾驶思考:基础架构篇

图片来自网络
文章作者:王方浩
编辑整理:Hoh Xil
内容来源:无人驾驶@知乎专栏
出品社区:DataFun
注:欢迎转载,转载请注明出处。
周末参加了小马智行的线下分享,获益良多。很羡慕北京的环境,大部分的线下都是在北京,难得有在深圳的。深圳虽然被誉为最有创新价值的城市,但关于技术方面的交流简直少的令人发指。
下面根据这次分享的内容,依次介绍下我的一些思考。
首先分享的是无人驾驶的基础架构。 如果说之前自动驾驶秀肌肉,都是通过 demo 演示下雨天真实路况穿越隧道。那么之后会逐步转变为秀基础架构。我觉得现在如果哪个无人驾驶公司对基础架构还不够重视,基本上就已经掉出第一梯队了。那么我们需要哪些基础架构呢?
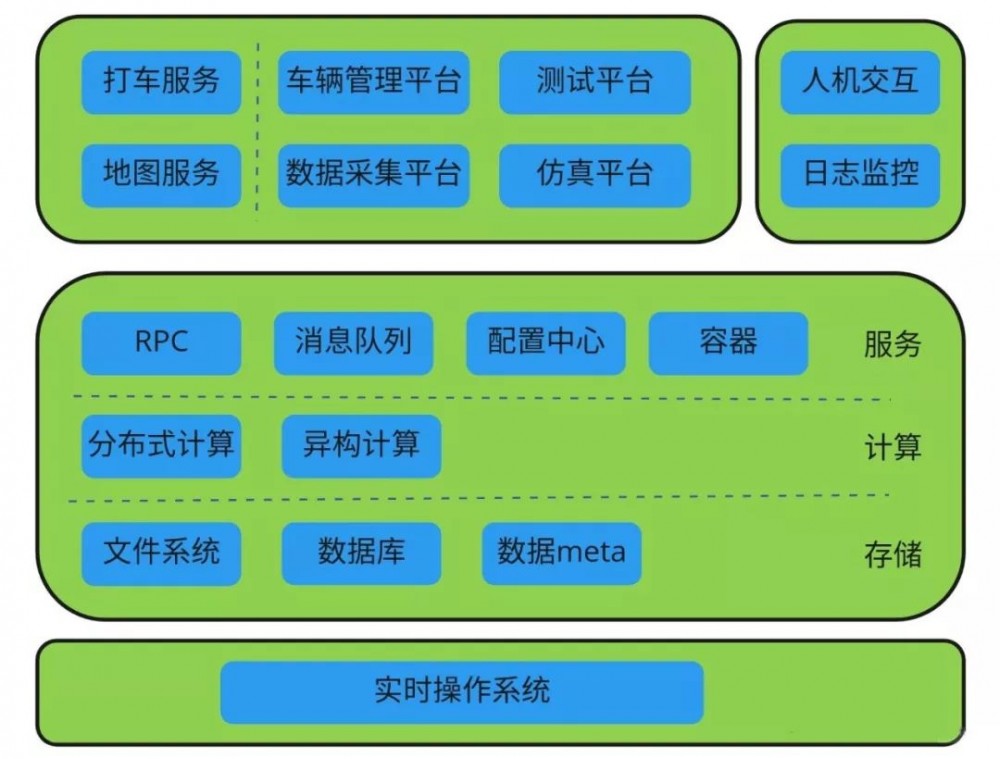
下面根据各个模块的内容,逐个分析下有哪些应用场景,为什么我们需要这些系统。
▌ 存储
首先我们看下存储,在自动驾驶中如何应用,有哪些应用场景?
-
文件系统
-
数据库
-
数据 meta
自动驾驶每天会产生大量的数据,之所以有这么多数据是因为无人车配置了多种传感器,这些传感器包括摄像头,激光雷达,GPS 等。每秒钟会生产大量的数据,30分钟的数据量就有几百 G,如果是一天的时间一辆车可能就产生几T的数据。由于数据量太大,我们有3种处理方式,第一种,缓存最近2分钟的数据,其他的数据处理完之后丢弃,这也是无人车正常情况下的做法,但是这种场景只适合正常运行的无人车,如果我的需求是采集地图,或者收集训练数据,那么就不太合适了。为了解决上述问题,后面的2种方法就是考虑如何把数据保存下来。第二种,保存到硬盘,之后再回传到数据中心,这种方法是目前普遍的方法,由于磁盘读写速率要求太大,普通的机械硬盘根本满足不了需求,只能采用 SSD 硬盘,1T 的 SSD 硬盘1200多块钱,还是很烧钱的。最后一种就是通过网络传输,目前 4G 的网速肯定是支持不了这么大数据的,5G 目前看是有可能,但也禁不起这么大流量,合理的做法是小数据通过网络传输,大数据落盘,把车的位置信息通过网络实时回传到数据中心,实现所有无人车的管理,其他的信息落到硬盘,记录运行情况。
介绍了自动驾驶的数据生产场景,那么再接下来看我们需要什么样的存储,首先我们需要一个分布式的文件系统, 大数据时代已经被广泛证明了分布式文件系统的好处,最主要的好处就是容量可以水平扩展,而且可靠性高 。 这样每天产生的几十T的数据都可以通过分布式文件系统保存下来。
接下来就是数据库的要求,这里主要分析下自动驾驶场景和传统互联网的区别,分享的老师也提到了,互联网的数据生产方式是几亿用户,每人产生几条数据,合起来几个T,而无人车是一辆车,每天产生几T数据,这里的差别很大。互联网中针对几亿用户,一般是选择 key-value 结构的数据库,例如 HBase。但是如果把 HBase 照搬到自动驾驶的场景就很别扭,因为 HBase 的单条数据最好是 10M 以内,否则会影响读写性能。这时候有人说我们可以把数据做拆分,把几个 T 的数据,根据地理位置信息或者时间做拆分,把地理位置信息或者时间作为 key,当时的数据作为 value,这样就可以实现一条数据很小,拆分成很多 key-value 的小数据了。我们再回过头去看下互联网的应用场景,互联网场景下是拿用户的 ID 作为 key,如果同时频繁的命中相邻的 ID,被称为单点问题,即容量上不去,每次访问都到一台机器上面去了。而按照地理位置或者时间的方式刚好又导致了这个问题,因为数据读取的时候就是按照地理位置顺序读取的,每次都命中到一台机器,导致整个系统的容量上不去。如果我们把 key 做哈希散列,把地理位置信息打散,这样容量是提高上去了。而这恰恰又和我们的应用场景有冲突,我们需要的不是高并发读取,即同时几十万的并发,而是一个用户连续读取大量数据,这样反而是单台读取的性能最高,因为会对数据做预取。所以我一度怀疑,自动驾驶的大数据需求都是伪需求,虽然说数据几 T 几 T 的,但是根本不是大数据,就是数据量大而已,根本不需要数据库,只需要文件系统就可以了。如果需要管理结构化的数据,还不如用数据库存储文件路径,而文件本身放到文件系统中。
所以以后自动驾驶的公司再提到大数据,别以为有多了不起,就是一个人虚胖了而已。但有一点我认为很重要,就是数据 meta,为什么需要数据 meta 呢? 数据 meta 是详细的记录了数据信息的数据,比如采集的时间,地点,天气,采集的人,当时的情况等信息,对数据做分类管理。 类似你到了一个图书馆,图书馆的书都是按照类目分门别类,然后你找书的时候直接按照索引来找就行了,试想一下,如果你去了一个图书馆,没有分类,书是按照出版时间来放置的,那么让你找一本烹饪类的但是不知道出版时间的书,试问你如何找到呢?由于自动驾驶的数据极其不具备可视化,就是一大堆二进制文件,没有什么可视化的信息。而且自动驾驶的场景多样,路况,时间,天气都不一样,数据量巨大,版本更新快。如果不分门别类,做好信息的 meta,那么后面假如你需要找所有下雨天的数据来进行测试,你如何去找呢?还得每个包确认下是否下雨?另一种应用场景就是测试数据的管理,每天测试的大量数据,什么时候因为什么原因接管的,这在后面回归测试和仿真中很关键,如果没有这些 meta 信息,假如我需要查找所有红绿灯引起的问题,来回归测试,我怎么怎么去查找呢?数据 meta 对自动驾驶的数据管理尤为关键,甚至目前我觉得自动驾驶只需要数据 meta 和文件系统就可以了。
当然有一个 HBase 的 Committer 加入了小马,我觉得 HBase 可能主要应用在他们的打车服务上,比如 routing 路线的记录,车和用户的信息管理等。可以看得出来小马对基础建设这块还是很重视的,也希望更多的人能够提出更多更好的基础建设。
▌计算
有了数据之后,需要计算才能得到结果,这就要用到计算平台。 计算可以分为2块,一块是离线计算,一块是在线计算。 离线计算就是数据的处理,这一块应该是可以完全借鉴互联网的分布式计算平台,因为无人车收集的数据需要分类,清洗,以及一些处理。一部分的应用场景是高精度地图的制作,需要把采集到的地理位置信息离线计算生成高精度地图;另一部分的应用场景是离线计算好一些数据给到在线,利用空间换时间。比如 planning 模块 reference line 的生成;routing 线路事先计算保存;感知的 ROI 区域;定位的点云数据处理等。主要的需求是能够更快的处理数据,这一部分用 spark 就可以解决了。
在线计算主要是无人车的实时计算,感知车当前的环境,控制车辆前进。 这一部分目前主要是一些异构计算,通用的计算放在 CPU 上,神经网络的计算放在 GPU 上,控制部分有单独拿处理器做的,这一块可以参考下博世等厂家。目前看好的趋势是拿 FPGA 做一些定制的算法开发,好处是比纯软件快,而且灵活,并且 FPGA 可以和硬件传感器深度定制。比如4路 camera,之前遇到一个问题是关于4个 camera 如何保持同步,即每个摄像头拍照的时间戳如何同步,看起来很难处理,你怎么保证它们同时拍摄呢,其实摄像头有一个 trigger 功能,即每次拍照类似按下快门,如果每次拍照的时候同时按下4个摄像头的快门,这样就能保证摄像头的同步了,高级点的摄像头都带有这个功能,可以预见 FPGA 和硬件算法的融合,会在在线计算中扮演越来越重要的角色。在线计算还需要低时延,这一块在自动驾驶平台中再介绍,我们到底需要一个什么样的自动驾驶平台?
▌ 基础服务
有了计算和存储,我们可以搭建基础的自动驾驶服务,但是如果要提供更多的服务,我们还需要以下几个部分。
-
RPC
-
消息队列
-
配置中心
-
容器
基本就是互联网服务的编排,部署和运维了。主要的应用场景比如打车服务,需要用到微服务架构,需要消息队列,需要配置中心,需要容器编排,这些都是比较成熟的架构了,网上有大量资料,就不展开了。
下面我们主要讲下实时计算平台,也就是无人车的自动驾驶平台,听到小马说我们是自己研发的一套自动驾驶操作系统,我还是感到有点震惊的,后面仔细想想其实可以把问题转换一下,看起来也就不是那么遥不可及了,当然如果要自研一套这样的系统,肯定是需要一个稳定成熟的团队。首先看下我们需要一个什么样的自动驾驶平台呢?我们由自动驾驶需要哪些模块来进行展开。
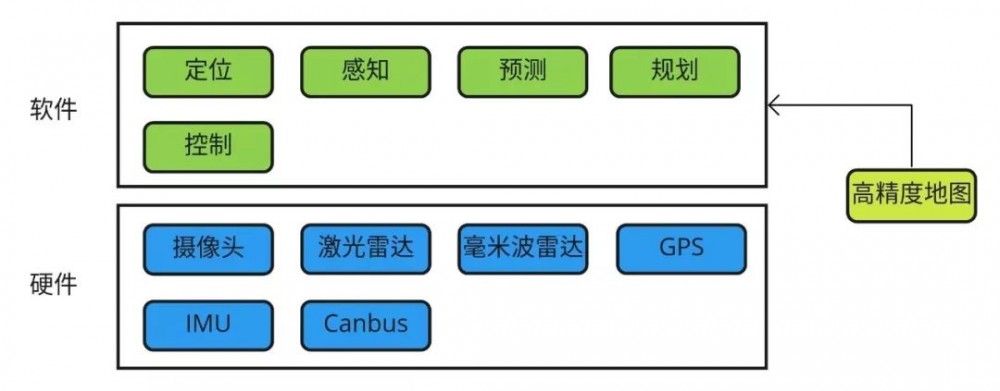
下面我们看下各个模块是如何工作的,我们以激光雷达来举例子,激光雷达实时的拍摄了一帧数据,然后放到了系统内存,这时候感知和定位模块都需要处理激光雷达的数据,一个不好的方式的是把数据拷贝一份分别给感知和定位模块,因为大数据的拷贝很耗时间,影响系统性能。我们需要换一种方式,以传递内存地址的方式把数据给感知和定位模块,减少内存的拷贝,分享的老师也强调了这点。接下来我们把刚才的过程抽象一下,即来了一份激光雷达的数据之后,系统分别调用定位和感知的函数,并且把数据在内存中的地址作为参数传递进去。接着我们把模块抽象一下,我们有3个模块,系统平台需要把 A 模块的数据传递给 B 和 C 模块,这样一来,我们需要的是一个能够同时发送消息给多个模块的功能,即一个分布式的消息队列。
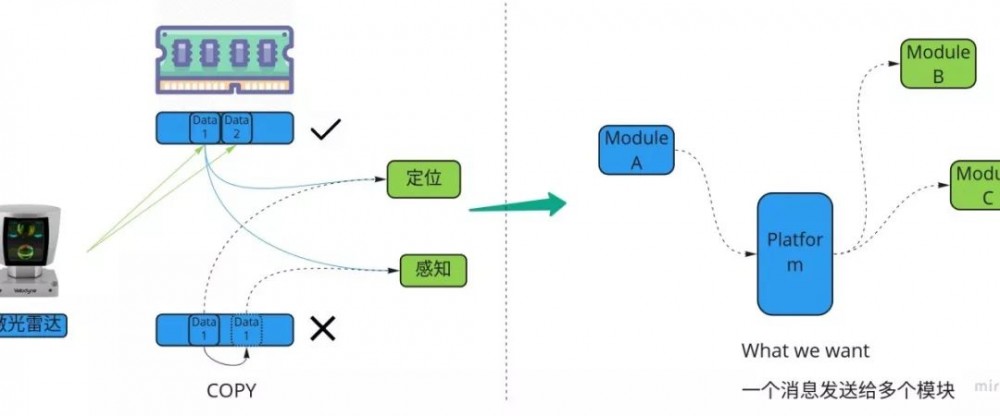
也就是说 自动驾驶平台实际上实现2个功能就可以了,一个是分布式消息队列,一个是各个模块的调度执行 。 所以我们把研发一个自动驾驶操作系统,转换为研发分布式消息队列和进程调度的问题了,这样看起来就简单了很多,因为都有现成的例子可以借鉴,回过头来看 Apollo 的 cyber 也就是实现了这2件事。最后还分享了一下研发效率提升的一些基础建设,包括代码管理,代码 review,内存泄露检测,代码扫描等,这些都代表了开发质量和生产力。
▌ 业务场景
上面主要是分享了一下基础的建设,那么如何和业务场景联系呢,我们接下来看目前的一些业务场景:
-
打车服务 - 小马主打 L4 的自动驾驶,目前主要是运营打车业务,类似一个滴滴提供的服务。
-
地图服务 - 主要是提供高精度地图服务。
-
人机交互 - 主要是人和车如何交互,如何知道车当前的状态,所处的环境等。比如坐车的时候可以通过界面知道车当前的状态,自己所处的位置,有没有异常等。不仅仅应用在乘客,还可以应用在内部测试和研发。这一部分我觉得主要是夸平台,免得二次开发,目前来看大部分的公司采用的都是 web 服务。
-
车辆管理 - 类似现在的美团外卖,实时知道外卖员的位置和派单信息,用算法来动态调度,无人车还需要多一个功能就是实时监控无人车的健康状态,可以理解为监控满大街在跑的服务器?
-
数据采集 - 主要是针对测试和采集地图的场景,需要一套全自动的采集流程,并提供可视化的交互,如果全部手工完成工作量太大了。
-
测试平台 - 主要是针对无人车的各项测试,包括硬件和软件,这涉及到各个模块,我觉得主要是流程的维护和测试项的定义,保证质量。
-
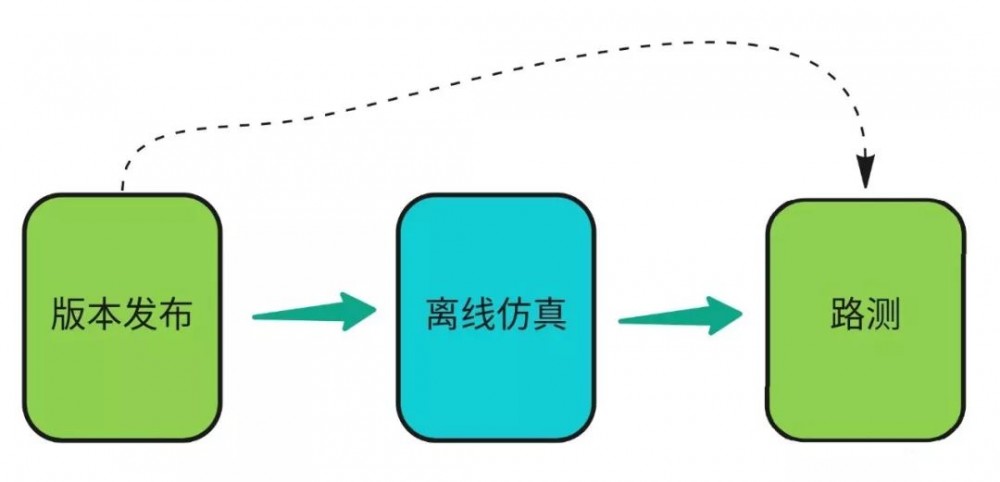
仿真平台 ,仿真是介绍的重点之一, 在版本发布之前,都需要在仿真平台测试 ,目前宣称的测试里程是 30W 公里,这一块肯定用到了分布式计算,否则没法实现。另外我觉得这个流程也挺有意义,在无人车路测之前进行仿真,可以减少故障,类似发布之前的集成测试。由于不需要真车,可以跑大量的测试,对工程化是很重要的一环。关于仿真还有另外的用途就是复现场景,比如一次撞车或者接管事故,现场不可能再去复现,成本太高,而通过仿真去模拟复现这些问题就变得容易多了,另外一个应用是训练模型,对于需要大量数据的训练,仿真可以虚拟和合成大量的数据,提高效率。关于仿真可以参考。
▌ 总结
以上就是根据上次宣讲凭记忆整理出来的一些思考和体会,有错误或者疏漏的地方欢迎指正,另外也期待更多的关于基础架构的介绍和分享,后面会接着介绍硬件和感知的分享和体会。
嘉宾介绍
王方浩,前蚂蚁金服高级软件工程师。一直从事软件相关工作,是操作系统、大数据、自动驾驶相关技术的爱好者。
对作者感兴趣的小伙伴,欢迎点击文末阅读原文,与作者交流。
——END——
文章推荐:
Pony.ai 的基础架构挑战与实践
高精地图和定位在自动驾驶的应用
关于 DataFun:
DataFun 定位于最实用的数据智能平台,主要形式为线下的深度沙龙、线上的内容整理。希望将工业界专家在各自场景下的实践经验,通过 DataFun 的平台传播和扩散,对即将或已经开始相关尝试的同学有启发和借鉴。
DataFun 的愿景是:为大数据、人工智能从业者和爱好者打造一个分享、交流、学习、成长的平台,让数据科学领域的知识和经验更好的传播和落地产生价值。
DataFun 成立至今,已经成功在全国范围内举办数十场线下技术沙龙,有超过三百位的业内专家参与分享,聚集了数万大数据、算法相关领域从业者。

点个「在看」,支持下! :point_down:
正文到此结束
- 本文标签: web 数据库 管理 key 开发 文章 进程调度 索引 云 事故 大数据 消息队列 操作系统 http 文件系统 配置中心 数据 智能 参数 运营 图片 工程师 部署 https UI 空间 滴滴 src 处理器 模型 分布式文件系统 质量 配置 软件工程师 快的 线下 数据科学 高并发 并发 测试 HBase 时间 美团 同步 无人车 分布式 微服务 定制 互联网 需求 软件 神经网络 id 服务器 进程 代码 value 总结 trigger 希望 缓存
- 版权声明: 本文为互联网转载文章,出处已在文章中说明(部分除外)。如果侵权,请联系本站长删除,谢谢。
- 本文海报: 生成海报一 生成海报二
热门推荐










相关文章






Loading...
![[HBLOG]公众号](http://www.liuhaihua.cn/img/qrcode_gzh.jpg)

