架构设计:比 Hadoop 快至少10倍的物联网大数据平台

文章作 者: 程洪泽 涛思数据
编辑整理:Hoh Xil
内容来源:www.taosdata.com
出品社区:DataFun
注:欢迎转载,转载请注明出处。
▌前言
TDengine: 专为物联网而生的大数据平台
TDengine 是一个开源的专为物联网、车联网、工业互联网、IT 运维等设计和优化的大数据平台。除核心的快10倍以上的时序数据库功能外,还提供缓存、数据订阅、流式计算等功能,最大程度减少研发和运维的工作量。


▌正文
TDengine 是一款轻量级、高效且单机开源的面向物联网的数据处理引擎。作为一款专门为物联网设计并实现的数据引擎,TDengine 在数据的写入、查询以及存储方面拥有其他数据库无法比拟的优势。本文主要探讨了 TDengine 在架构设计和存储方面的创新,以方便用户理解 TDengine 强大性能背后的逻辑。
▌TDengine 架构设计
如图1所示,TDengine 服务主要包含两大模块: 管理节点模块(MGMT) 和 数据节点模块(DNODE) 。整个 TDengine 还包含 客户端模块 。
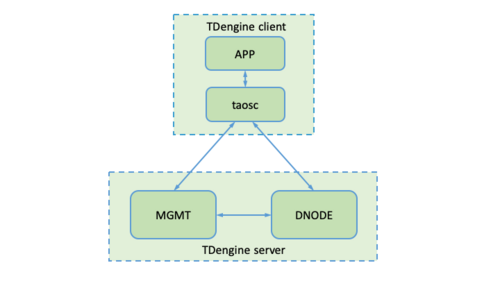
图 1 TDengine 架构示意图
1. 管理节点模块
管理节点模块主要负责元数据的存储和查询等工作,其中包括用户信息的管理、数据库和表信息的创建、删除以及查询等。应用连接 TDengine 时会首先连接到管理节点。在创建/删除数据库和表时,请求也会首先发送请求到管理节点模块。由管理节点模块首先创建/删除元数据信息,然后发送请求到数据节点模块进行分配/删除所需要的资源。在数据写入和查询时,应用同样会首先访问管理节点模块,获取元数据信息。然后根据元数据管理信息访问数据节点模块。
2. 数据节点模块
写入数据的存储和查询工作是由数据节点模块负责。为了更高效地利用资源,以及方便将来进行水平扩展,TDengine 内部对数据节点进行了虚拟化,引入了虚拟节点(vnode)的概念,作为存储、资源分配以及数据备份(商业版本中)的单元。如图2所示,在一个 dnode 上,通过虚拟化,可以将该 dnode 视为多个虚拟节点的集合。每个虚拟节点存储一定数量的表中的数据。不同的 vnode 之间资源互不共享。每个虚拟节点都有自己的缓存,在硬盘上也有自己的存储目录。而同一 vnode 内部无论是缓存还是硬盘的存储都是共享的。通过虚拟化,TDengine 可以将 dnode 上有限的物理资源合理地分配给不同的 vnode,大大提高资源的利用率和并发度。一台物理机器上的虚拟节点个数可以根据其硬件资源进行配置。
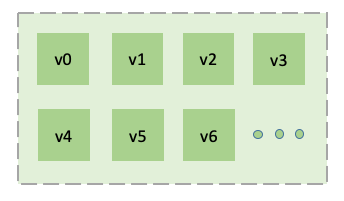
图 2 TDengine 虚拟化
3. 客户端模块
TDengine 客户端模块主要负责将应用传来的请求(SQL 语句)进行解析,转化为内部结构体再发送到服务端。TDengine 的各种接口都是基于 TDengine 的客户端模块进行开发的。
▌TDengine 写入流程
TDengine 的完整写入流程如图3所示。为了保证写入数据的安全性和完整性,TDengine 在写入数据时采用[预写日志算法]。客户端发来的数据在经过验证以后,首先会写入预写日志中,以保证 TDengine 能够在断电等因素导致的服务重启时从预写日志中恢复数据,避免数据的丢失。写入预写日志后,数据会被写到对应的 vnode 的缓存中。随后,服务端会发送确认信息给客户端表示写入成功。TDengine 中存在两种机制可以促使缓存中的数据写入到硬盘上进行持久化存储:
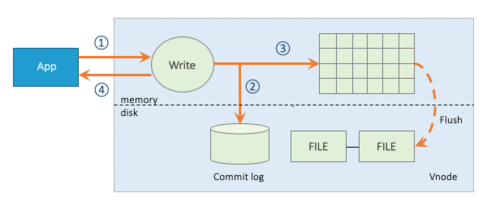
图 3 TDengine 写入流程
-
时间驱动的落盘 : TDengine 服务会定时将 vnode 缓存中的数据写入到硬盘上,默认为一个小时落一次盘。落盘间隔可在配置文件中配置。
-
数据驱动的落盘 : 当 vnode 中缓存的数据达到一定规模时,为了不阻塞后续数据的写入,TDengine 也会拉起落盘线程将缓存中的数据清空。数据驱动的落盘会刷新定时落盘的时间。
TDengine 在数据落盘时会打开新的预写日志文件,在落盘后则会删除老的预写日志文件,避免日志文件无限制的增长。
▌元数据的存储
TDengine 中的元数据信息包括 TDengine 中的数据库,表等信息。元数据信息默认存放在 /var/lib/taos/mgmt/ 文件夹下。
元数据文件只进行追加操作,即便是元数据的删除,也只是在数据文件中追加一条删除的记录。
▌写入数据的存储
TDengine 中写入的数据在硬盘上是按时间维度进行分片的。同一个 vnode 中的表在同一时间范围内的数据都存放在同一文件组中,如下图中的 v0f1804* 文件。这一数据分片方式可以大大简化数据在时间维度的查询,提高查询速度。在默认配置下,硬盘上的每个文件存放10天数据。用户可根据需要进行配置。
数据在文件中是按块存储的。每个数据块只包含一张表的数据,且数据是按照时间主键递增排列的。数据在数据块中按列存储,这样使得同类型的数据存放在一起,可以大大提高压缩的比例,节省存储空间。
TDengine 的数据文件默认存放在 /var/lib/taos/data/ 下。
而 /var/lib/taos/tsdb/ 文件夹下存放了 vnode 的信息、vnode 中表的信息以及数据文件的链接。完整目录结构如下所示:
1. meterObj 文件
每个 vnode 中只存在一个 meterObj 文件。该文件中存储了 vnode 的基本信息(创建时间,配置信息,vnode 的统计信息等)以及该 vnode 中表的信息。其结构如下所示:
其中,文件头大小为512字节,主要存放 vnode 的基本信息。每条表记录代表属于该 vnode 中的一张表在硬盘上的表示。
2. head 文件
head 文件中存放了其对应的 data 文件中数据块的索引信息。该文件组织形式如下:
文件开头的偏移量列表表示对应表的数据索引块的开始位置在文件中的偏移量。每张表的数据索引信息在 head 文件中都是连续存放的。这也使得 TDengine 在读取单表数据时,可以将该表所有的数据块索引一次性读入内存,大大提高读取速度。表的数据索引块组织如下:
其中,索引块信息中记录了数据块的个数等描述信息。每个数据块索引对应一个在 data 文件或 last 文件中的一个单独的数据块。索引信息中记录了数据块存放的文件、数据块起始位置的偏移量、数据块中数据时间主键的范围等。索引块中的数据块索引是按照时间范围顺序排放的,这也就是说,索引块 M 对应的数据块中的数据时间范围都大于索引块 M-1 的。这种预先排序的存储方式使得在 TDengine 在进行按照时间戳进行查询时可以使用折半查找算法,大大提高查询速度。
3. data 文件
data 文件中存放了真实的数据块。该文件只进行追加操作。其文件组织形式如下:
每个数据块只属于 vnode 中的一张表,且数据块中的数据按照时间主键排列。数据块中的数据按列组织排放,使得同一类型的数据排放在一起,方便压缩和读取。每个数据块的组织形式如下所示:
列信息中包含该列的类型,列的压缩算法,列数据在文件中的偏移量以及长度等。除此之外,列信息中也包含该内存块中该列数据的预计算结果,从而在过滤查询时根据预计算结果判定是否读取数据块,大大提高读取速度。
4. last 文件
为了防止数据块的碎片化,提高查询速度和压缩率,TDengine 引入了 last 文件。当要落盘的数据块中的数据条数低于某个阈值时,TDengine 会先将该数据块写入到 last 文件中进行暂时存储。当有新的数据需要落盘时,last 文件中的数据会被读取出来与新数据组成新的数据块写入到 data 文件中。last 文件的组织形式与 data 文件类似。
▌小结
TDengine 通过其创新的架构和存储结构设计,有效提高了计算机资源的使用率。一方面,TDengine 的虚拟化使得 TDengine 的水平扩展及备份非常容易。另一方面,TDengine 将表中数据按时间主键排序存储且其列式存储的组织形式都使 TDengine 在写入、查询以及压缩方面拥有非常大的优势。
嘉宾介绍
程洪泽,北京涛思数据科技有限公司 联合创始人。美国密西根大学EE硕士,中国科大本科,是中国科大最高荣誉的郭沫若奖学金获得者。主要研究方向为大数据分析和机器学习。
——END——
文章推荐:
网易大数据体系之时序数据技术
时序数据在滴滴实时数据开发平台中的处理和应用
阿里巴巴双十一千万级实时监控系统技术揭秘
关于 DataFun:
DataFun 定位于最实用的数据智能平台,主要形式为线下的深度沙龙、线上的内容整理。希望将工业界专家在各自场景下的实践经验,通过 DataFun 的平台传播和扩散,对即将或已经开始相关尝试的同学有启发和借鉴。
DataFun 的愿景是:为大数据、人工智能从业者和爱好者打造一个分享、交流、学习、成长的平台,让数据科学领域的知识和经验更好的传播和落地产生价值。
DataFun 成立至今,已经成功在全国范围内举办数十场线下技术沙龙,有超过三百位的业内专家参与分享,聚集了数万大数据、算法相关领域从业者。

点个「在看」,支持下! :point_down:
正文到此结束
热门推荐










相关文章






Loading...
![[HBLOG]公众号](http://www.liuhaihua.cn/img/qrcode_gzh.jpg)

