打印日志时 Logback 内部都做了些什么
文 | 百川 on 资产管理
一、引言
Logback 是一个优秀的开源日志框架,我们很多项目都使用它来记录日志。实际使用时,通常仅需要一行语句即可记录相应的日志信息,如
logger.info("Hello world.");
那么,看似简单的语句背后都有哪些故事,打印日志时 Logback 内部都做了些什么?
本文以输出日志内容到文件为例,阐述 Logback 打印日志的工作流程。
二、Logback 设计
想要了解 Logback 打印日志的工作原理,首先需要清楚 Logback 所涉及的一些重要概念。
-
LoggingEvent
LoggingEvent 表示日志事件的概念,其中包括了所有与打印日志请求相关的参数,如当前请求线程、当前时间、消息内容、请求级别等。整个日志打印流程都围绕这个类来展开。
-
Logger
Logger 意为日志记录器,是打印日志的入口,打印日志时要先获取一个 Logger对象。每个 Logger 对象都有一个名字,且名字遵循层次化的命名规则。如 名为 "com.foo" 的 logger 是名为 "com.foo.Bar" 的 logger的父级。root logger 位于 logger 层级的最顶端,是所有 logger 的祖先。
-
Appender
Logback 允许日志输出到多个目的地,Appender 表示目的地这个概念,常见的 appender 有控制台、文件、socket 服务器、数据库等。一个 logger 可以关联多个 appender。
-
Layout
Layout 负责对日志消息进行格式化,用户可以自主设置日志输出的格式。
如,采用转换模式 "%-4relative [%thread] %-5level %logger{32} - %msg%n" 输出的日志格式如下:
176[main]DEBUG manual.architecture.HelloWorld-Helloworld.
其中,第一列表示时间戳,第二列表示日志请求线程,第三列表示请求级别,第四列表示请求的 logger 的名字,"-"之后的内容为具体的日志文本。
Logback 核心类图如下:
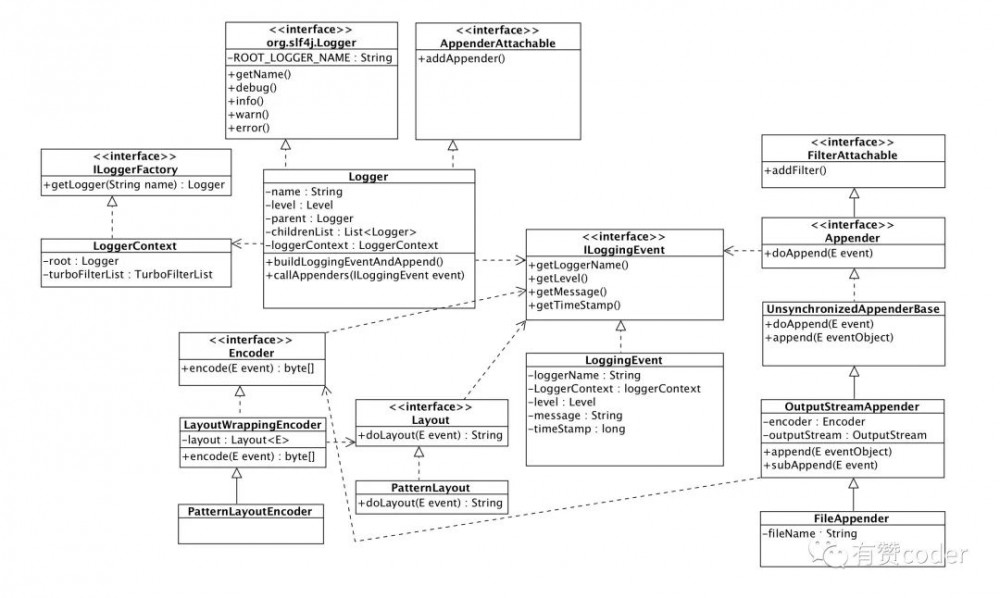
三、打印日志流程
清楚了Logback 中的核心概念,下面开始介绍 Loback打印日志流程。
3.1 获取 Logger
调用 org.slf4j.LoggerFactory 类的 getLogger 方法,即可获取 Logger 对象,如图。
相同名字对应的 Logger 对象相同,即 x,y 指向同一个对象。
3.2 调用 logger 打印方法
下面介绍调用 logger 的 info() 方法时做了哪些事情。
3.2.1 取得过滤链(filter chain)的判定结果
此处使用的过滤器类为 TurboFilter,TurboFilter 与日志上下文绑定,在日志事件(LoggingEvent)创建之前被调用,会过滤所有的日志请求。如果过滤链的判断结果为 FilterReply.DENY,则记录请求被抛弃。如果结果是 FilterReply.NEUTRAL,则继续下一步,即进入2.2。如果结果是 FilterReply.ACCEPT,则忽略第二步, 直接进入第三步,即2.3。
3.2.2 检查日志级别
对 logger 的有效级别与日志请求级别进行比较。如果请求级别数值小于有效级别,本次请求将 被禁用,Logback 会直接抛弃请求,不做进一步处理;否则,继续下一步。
3.2.3 创建 LoggingEvent 对象
只有到了这一步,logback 才会创建 LoggingEvent 对象,该对象包含所有与请求相关的参数,如请求用的 logger、请求级别、消息、请求携带的异常、当前时间、当前线程等。
3.2.4 调用 appenders 的 doAppend() 方法
在创建 LoggingEvent 对象以后,logback 将调用所有可用 appender 的 doAppend()方法,进行日志输出。
doAppender()方法会调用 appender 关联的过滤器,此处使用的过滤器类为 Filter,执行过滤链判定, 返回结果同 TurboFilter 判定结果,都是一个 FilterReply 枚举值。如果当前过滤器返回结果是 FilterReply.DENY,则记录请求被抛弃;如果结果是 FilterReply.NEUTRAL,则将日志事件交由过滤链中下一个过滤器来处理;如果结果是 FilterReply.ACCEPT,日志事件被立即处理,不再经过剩余的过滤器。
3.2.5 格式化日志信息
appender 在输出日志信息前,需要对日志事件(LoggingEvent)进行格式化。以 OutputStreamAppender 为例,它使用 Encoder 将日志事件转换为字节数组并把字节数组写出到相应的输出流,在转换为字节数组前,Encoder 通过调用 Layout 的 doLayout() 方法将日志事件格式化为字符串。
3.2.6 输出日志信息
日志信息格式化完成以后,将会输出到各个 appender 对应的目的地。
Logback 打印日志整体流程如下图:
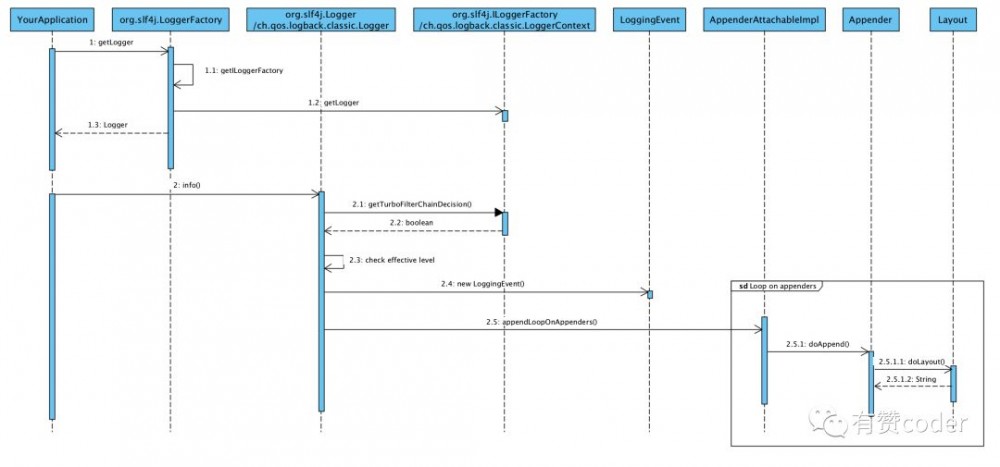
四、额外的工作
日志输出到文件以后,会引出一些新的问题。如单个文件太大能否进行切割,能否对文件进行归档,超出一定时间的历史日志能否自动删除等。Logback 内部,RollingFileAppender 担此重任,用来处理这类问题。
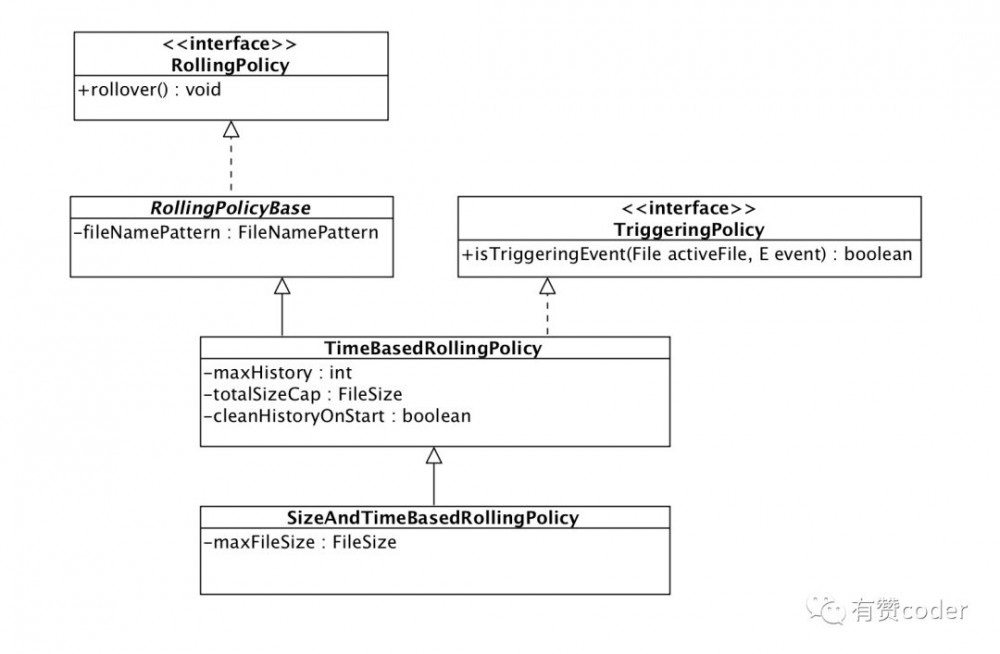
RollingFileAppender 继承自 FileAppender,能够滚动记录文件,其内部依赖两个重要组件。一个是 RollingPolicy,负责滚动处理(rollover)。另一个是 TriggeringPolicy,决定是否滚动以及何时进行滚动处理。
项目中名为 “ERROR” 的 appender 配置如下,应用通过该 appender,将 ERROR 级别的日志输出到 error.log 文件中,同时,使用基于大小和时间的滚动策略来对 error.log 文件进行处理。
这里用到了 SizeAndTimeBasedRollingPolicy,它同时实现了 RollingPolicy 和 TriggeringPolicy,该类类图如下:
RollingFileAppender 在输出日志信息时,会调用一个 subAppend()方法,代码如下:
在同步代码块中,首先判断是否触发翻转操作,如果是,则对日志文件进行翻转处理。 可见,日志翻转发生在打印日志时。 这里翻转操作有两种情况。
4.1 基于文件大小滚动
如果当前日志文件大小超过了设置的 maxFileSize,会触发一次翻转操作,将当前文件归档,同时创建一个新的活动文件,用来输出日志。
4.2 基于时间滚动
Logback 在初始化时会设置一个滚动触发时间点,当到达该时间点以后,会触发一次翻转操作,同样将当前文件归档,同时创建一个新的活动文件,用来输出日志;此外,会按照 maxHistory 的设置对归档日志文件进行删除,若设置了 totalSizeCap,还会判断归档日志文件大小是否超过了该值,超过则会进行清理。清理工作由异步线程来进行,关键代码如下:
五、尾声
至此,Logback 打印日志到文件的工作流程就介绍完了。
翻阅 Logback资料时,在官方 jira 上看到过一个问题:有个桌面应用使用 Logback 记录日志,该应用每天运行几次,但基本不会在凌晨使用;问题现象是应用配置了 maxHistory ,历史日志文件并没有被删除。经分析,是因为 Logback 滚动触发时间是在每次应用启动的时候进行设置,按天滚动就设置为第二天凌晨记录日志时触发,由于该应用只在白天运行,且每次启动都会重新设置触发时间,导致滚动策略永远不会触发,所以历史日志文件不会被删除。
在后面的版本中,Logback 在 TimeBasedRollingPolicy 中增加了 cleanHistoryOnStart 属性,配置为 true 以后,可以在应用启动时执行历史日志删除工作,解决了上述问题。
由此可见,任何优秀的系统都不是一蹴而就的,而是在满足业务场景的基础上不断迭代演化而来的。
推荐阅读:
-
记一次故障引发的线程池使用的思考
-
营销系统在预付卡场景下的演进
-
CAP一致性协议及应用解析
-The End-
Vol.201
有赞技术团队
为 442 万商家,150 个行业,330 亿电商交易额
提供技术支持
微商城|零售|美业 | 教育
微信公众号:有赞coder 微博:@有赞技术
技术博客:tech.youzan.com
The bigger the dream,
the more important the team.
正文到此结束
热门推荐










相关文章






Loading...
![[HBLOG]公众号](http://www.liuhaihua.cn/img/qrcode_gzh.jpg)

