高并发下架构师为什么更喜欢进程内缓存

进程内缓存是指缓存和应用程序在相同地址空间。即同一个进程内。分布式缓存是指缓存和应用程序位于不同进程的缓存,通常部署在不同服务器上。
从前有个机构,机构的主人叫做 CPU,这个机构专门派仆人取一些东西然后做相应的处理。下面是这个机构日常的场景。
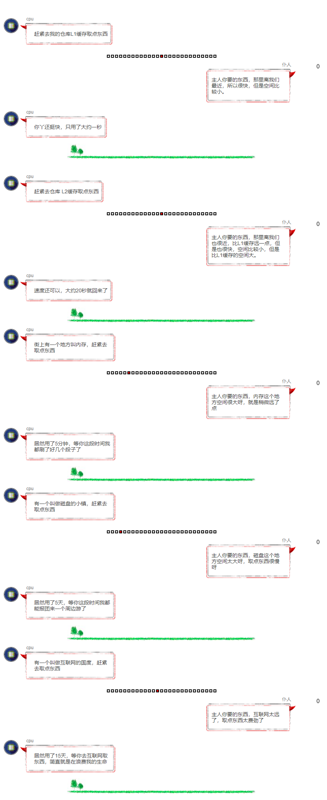
以上故事纯属预估数据,真实数据会根据不同的硬件配置和网络环境有误差。
通过以上不正经的小故事,我们可以了解到cpu取各个设备数据的大体差距。至于YY妹子的问题,大家也应该了解了。
- 首先把数据从磁盘加载到内存做缓存,这个是对的。毕竟磁盘的IO速度比内存要慢的多。就拿我们现在使用的大多数PC机以及服务器来说,磁盘往往是性能的瓶颈。
- 如果有条件或者框架支持可以实现进程内缓存,我还是推荐使用进程内缓存,毕竟类似Redis这样的kv存储和应用程序多数情况不在一台服务器上,虽然局域网的速度肉眼看起来非常快,但是对于cpu来讲,还是让cpu休了一个大假。
至于什么情况下适合应用进程内缓存,我觉得有几点需要注意:
- 相同的请求或者设置的相同缓存key的请求每次都是同一个服务器上的同一个程序去处理,这样这个请求的缓存正常情况下只会产生一份。 如果每次请求都会路由到不同的服务器,便会产生多个缓存的副本,维护这些缓存数据的一致性是需要代价的。
- 当有新的服务器节点加入或者服务器节点退出的时候,不能发生雪崩现象,所有缓存请求都穿透到达数据库,那是比较要命的。比如可以看一下菜菜以前的文章:分布式缓存的一条明路(附代码)
- 如果缓存的处理服务器发生变化,比如:由于某种原因,开始请求是由服务器A来处理,后来A服务器down了,现在由服务器B来处理,在缓存转移的过程中,必须能保证数据的正确性和一致性。
- 程序的进程内缓存必须有过期策略,在有限内存大小的情况下,合理的使用。推荐使用LRU淘汰算法来保证内存不会撑爆。
- 系统的并发量及其大,对性能的要求及其高,可以考虑使用进程内缓存。
- 如果是小部分只读数据,并且访问量比较大,例如经常使用的字典数据等,可以考虑使用进程内缓存。
相对于分布式缓存,比如Redis,进程内缓存有哪些优势呢?
- 进程内缓存性能比较高,延迟会更小,更节省带宽,毕竟分布式缓存网络调用的性能和本地调用比起来慢太多,
- 由于和应用程序位于同一进程,共享相同的虚拟内存,所以在状态维护上更容易一些,
- 其次进程内的缓存不设计到网络传输,所以没有序列化的过程,在性能上更胜一筹。
- 进程内缓存的数据类型几乎可以是语言级别支持的任意类型,数据类型设计上比大多数分布式缓存设备支持要灵活许多。
在应对高并发的情况下,如果有适当的环境菜菜还是觉得进程内缓存为首选,另外一点程序要尽量避免线程切换,尽量异步化。如果可以最好能预估出缓存数据的大小,避免内存泄漏等现象发生。
当然分布式缓存有自己的优势,在监控,容灾,扩展性,易用性等方面更胜一筹。至于用进程内还是分布式缓存,没有定论,能解决业务痛点就是最好的结果
写在最后
程序如果要想最大程度的提升并发量,缩短响应时间, 就把用户需要的数据放在离用户最近的地方
添加关注,查看更精美版本,收获更多精彩

正文到此结束
热门推荐










相关文章

近期评论
-
你这基本没有更新呀,最近文章显示还是2019年的文章。不符合要求哈
-
关键词:慕云博客 链接:https://www.lilun.me 描述:分享原创文字的个人博客
-
-
-
可以提供一下源码吗
-
不是商业站,鸡娃学习笔记
-
-
-
-
听他们说很厉害的样子
Loading...
![[HBLOG]公众号](http://www.liuhaihua.cn/img/qrcode_gzh.jpg)

