记一次JVM FullGC引发严重线上事故的定位、分析、解决过程!
公众号后台回复“ 学习 ”,获取作者独家秘制精品资料

扫描下方海报二维码,试听课程:
(课程详细大纲,请参见文末)

“ 这篇文章给大家聊一次线上生产系统事故的解决经历,其背后代表的是线上生产系统的JVM FullGC可能引发的严重故障。
一、业务场景介绍
先简单说说线上生产系统的一个背景,因为仅仅是文章作为案例来讲,所以弱化大量的业务背景。
简单来说,这是一套分布式系统,系统A需要将一个非常核心以及关键的数据通过网络请求,传输给另外一个系统B。
所以这里其实就考虑到了一个问题,如果系统A刚刚将核心数据传递给了系统B,结果系统B莫名其妙宕机了,岂不是会导致数据丢失?
所以在这个分布式系统的架构设计中,采取了非常经典的一个 Quorum算法 。
这个算法简单来说,就是系统B必须要部署奇数个节点,比如说至少部署3台机器,或者是5台机器,7台机器,类似这样子。
然后系统A每次传输一个数据给系统,都必须要对系统B部署的全部机器都发送请求,将一份数据传输给系统B部署的所有机器。
要判定系统A对系统B的一次数据写是成功的,要求系统A必须在指定时间范围内对超过Quorum数量的系统B所在机器传输成功。
举个例子,假设系统B部署了3台机器,那么他的Quorum数量就是:3 / 2 + 1 = 2,也就是说系统B的Quorum数量就是:所有机器数量 / 2 + 1。
所以系统A要判定一个核心数据是否写成功,如果系统B一共部署了3台机器的话,那么系统A必须在指定时间内收到2台系统B所在机器返回的写成功的响应。
此时系统A才能认为这条数据对系统B是写成功了。 这个就是所谓的Quorum机制 。
也就是说,分布式架构下,系统之间传输数据,一个系统要确保自己给另外一个系统传输的数据不会丢失,必须要在指定时间内,收到另外一个系统Quorum(大多数)数量的机器响应说写成功。
这套机制实际上在很多分布式系统、中间件系统中都有非常广泛的使用,我们线上的分布式系统也是采用了这个Quorum机制在两个系统之间传输数据。
给大家上一张图,一起来看一下这套架构长啥样。
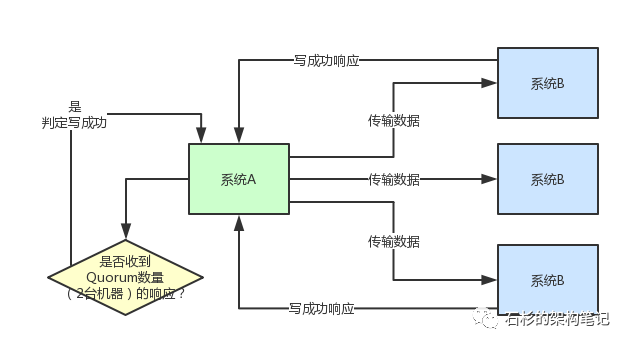
如上图所示,图中很清晰的展示了系统A和系统B之间传输一份数据时的Quorum机制。
接下来,我们用代码给大家展示一下,上面的Quorum写机制在代码层面大概是什么样子的。
PS: 因为实际这套机制涉及大量的底层网络传输、通信、容错、优化的东西,所以下面代码经过了大幅度简化,仅仅表达出了一个核心的意思。
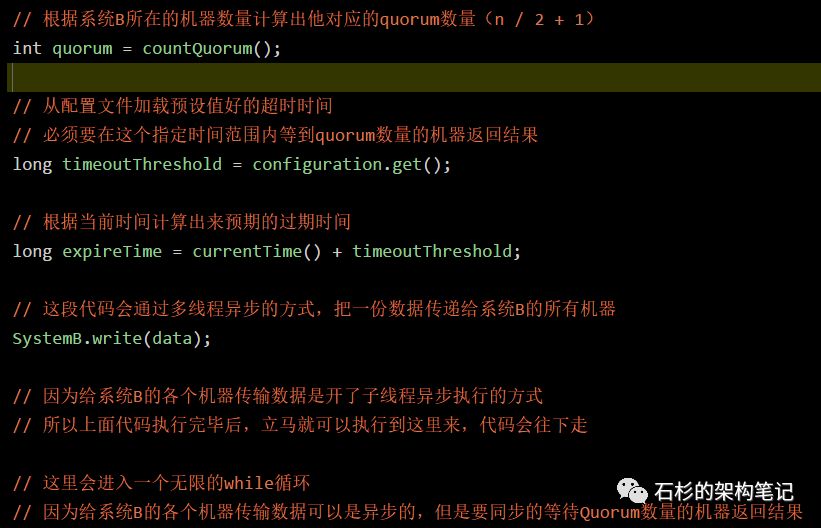

上面就是经过大幅精简后的代码,不过核心的意思是表达清晰了。大家可以仔细看两遍,其实还是很容易弄懂的。
这段代码其实含义很简单,说白了就是异步开启线程发送数据给系统B所有的机器,同时进入一个while循环等待系统B的Quorum数量的机器返回响应结果。
如果超过指定超时时间还没收到预期数量的机器返回结果,那么就判定系统B部署的集群出现故障,接着让系统A直接退出,相当于系统A宕机。
整个代码,就是这么个意思!
二、问题凸现
光是看代码其实没啥难的,但是问题就在于线上运行的时候,可不是跟你写代码的时候想的一样简单。
有一次线上生产系统运行的过程中,整体系统负载都很平稳,本来是不应该有什么问题,但是结果突然收到报警,说系统A突然宕机了。
然后就开始进行排查,左排查右排查,发现系统B集群都好好的,不应该有问题。
然后再查查系统A,发现系统A别的地方也没什么问题。
最后结合系统A自身的日志,以及系统A的JVM FullGC进行垃圾回收的日志,我们才算是搞清楚了具体的故障原因。
三、定位问题
其实原因非常的简单,就是系统A在线上运行一段时间后,会偶发性的进行长时间Stop the World的JVM FullGC,也就是大面积垃圾回收。
但是,此时会造成系统A内部的工作线程大量的卡顿,不再工作。要等JVM FullGC结束之后,工作线程才会恢复运作。
我们来看下面那个代码片段:

但是这种系统A的莫名宕机是不正确的,因为如果没有JVM FullGC,本来上面那个if语句是不会成立的。
他会停顿1秒钟进入下一轮while循环,接着就可以收到系统B返回的Quorum数量的结果,这个while循环就可以中断,继续运行了。
结果因为出现了JVM FullGC卡顿了几十秒,导致莫名其妙就触发了if判断的执行,系统A莫名其妙就退出宕机了。
所以, 线上JVM FullGC导致的系统长时间卡顿,是造成系统不稳定运行的隐形杀手之一!
四、解决问题
至于上述代码稳定性的优化,也很简单。我们只要在代码里加入一些东西,监控一下上述代码中是否发生了JVM FullGC。
如果发生了JVM FullGC,就自动延长expireTime就可以了。
比如下面代码的改进:
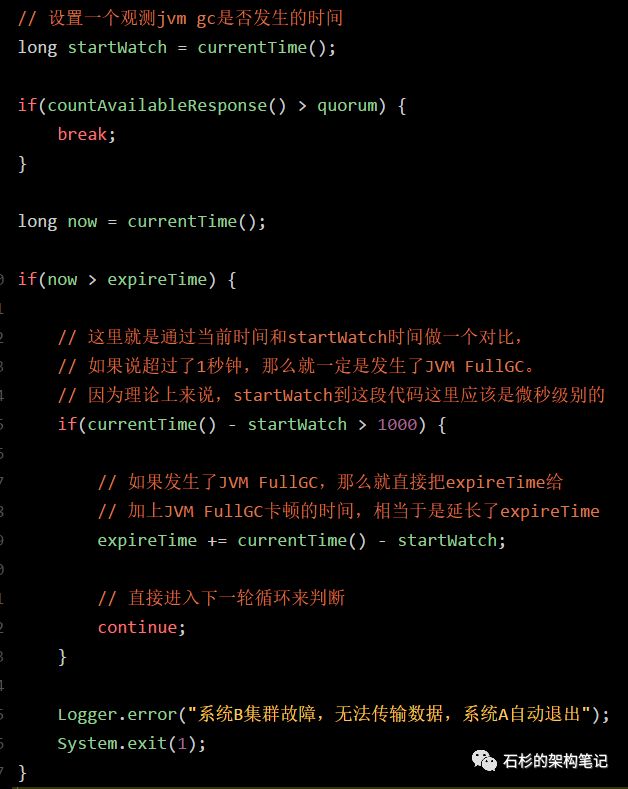
通过上述代码的改进,就可以有效的优化线上系统的稳定性,保证其在JVM FullGC发生的情况下,也不会随意出现异常宕机退出的情况了。
END
如有收获,请划至底部,点击“ 在看 ”,谢谢!
欢迎长按下图关注公众号 石杉的架构笔记

BAT架构经验倾囊相授
正文到此结束
热门推荐









相关文章

近期评论
-
你这基本没有更新呀,最近文章显示还是2019年的文章。不符合要求哈
-
关键词:慕云博客 链接:https://www.lilun.me 描述:分享原创文字的个人博客
-
-
-
可以提供一下源码吗
-
不是商业站,鸡娃学习笔记
-
-
-
-
听他们说很厉害的样子
Loading...
![[HBLOG]公众号](http://www.liuhaihua.cn/img/qrcode_gzh.jpg)

