Querydsl-JPA学习(入门篇)
Springdata-JPA是对JPA使用的封装,Querydsl-JPA也是基于各种ORM之上的一个通用查询框架,使用它的API类库可以写出“Java代码的sql”,不用去手动接触sql语句,表达含义却如sql般准确。更重要的一点,它能够构建类型安全的查询,这比起JPA使用原生查询时有很大的不同,我们可以不必再对恶心的“Object[]”进行操作了。当然,我们可以SpringDataJPA +Querydsl-JPA联合使用,它们之间有着完美的相互支持,以达到更高效的编码。
gitub地址: github.com/querydsl/qu…
2.spring boot配置 Querydsl-JPA:
2.1:新增jar包:
<dependency>
<groupId>com.querydsl</groupId>
<artifactId>querydsl-jpa</artifactId>
</dependency>
<dependency>
<groupId>com.querydsl</groupId>
<artifactId>querydsl-apt</artifactId>
<scope>provided</scope>
</dependency>
复制代码
2.2:新增插件:
作用:对带有@Entity注解的实体类生成Q版实体类
<!-- query dsl 构建Q版实体类的插件-->
<plugin>
<groupId>com.mysema.maven</groupId>
<artifactId>apt-maven-plugin</artifactId>
<version>1.1.3</version>
<executions>
<execution>
<goals>
<goal>process</goal>
</goals>
<configuration>
<outputDirectory>target/generated-sources/java</outputDirectory>
<processor>com.querydsl.apt.jpa.JPAAnnotationProcessor</processor>
</configuration>
</execution>
</executions>
</plugin>
复制代码
2.3:JPAQueryFactory配置:
作用:使用QueryDSL的功能时,会依赖使用到JPAQueryFactory,而JPAQueryFactory在这里依赖使用EntityManager,所以在主类中做如下配置,使得Spring自动帮我们注入EntityManager与自动管理JPAQueryFactory
import javax.persistence.EntityManager;
import org.springframework.context.annotation.Configuration;
import org.springframework.web.servlet.config.annotation.WebMvcConfigurer;
import com.querydsl.jpa.impl.JPAQueryFactory;
@Configuration
public class WebMvcConfig implements WebMvcConfigurer {
@Bean
public JPAQueryFactory jpaQuery(EntityManager entityManager) {
return new JPAQueryFactory(entityManager);
}
}
复制代码
2.4:使用bean注入:
@Autowired
private JPAQueryFactory jpaQueryFactory;
复制代码
2.5:maven构建操作:
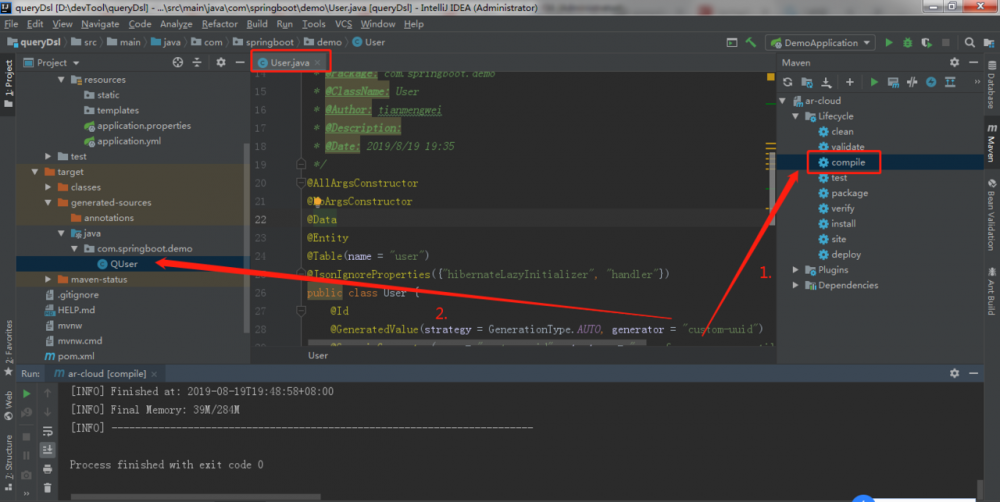
3.Querydsl-JPA单表操作:
3.1 新增实体类:
import com.fasterxml.jackson.annotation.JsonIgnoreProperties;
import lombok.AllArgsConstructor;
import lombok.Data;
import lombok.NoArgsConstructor;
import org.hibernate.annotations.GenericGenerator;
import javax.persistence.*;
import java.math.BigDecimal;
import java.sql.Timestamp;
@AllArgsConstructor
@NoArgsConstructor
@Data
@Entity
@Table(name = "user_tmw")
@JsonIgnoreProperties({"hibernateLazyInitializer", "handler"})
public class User {
@Id
@GeneratedValue(strategy = GenerationType.AUTO, generator = "custom-uuid")
@GenericGenerator(name = "custom-uuid", strategy = "com.springboot.demo.bean.CustomUUIDGenerator")
@Column(name = "id", nullable = false, length = 32)
private String id;
@Column(name = "name", length = 10)
private String name;
@Column(name = "age")
private Integer age;
@Column(name = "money")
private BigDecimal money;
@Column(name = "begin_time")
private Timestamp beginTime;
@Column(name = "end_time")
private Timestamp endTime;
}
复制代码
3.2 等于某个值的结果集:
QUser user = QUser.user;
//单表获取年龄为10的结果集
List<User> ageList = jpaQueryFactory.selectFrom(user).where(user.age.eq(10)).fetch();
String ageListStr = JSON.toJSONString(ageList);
System.out.println("单表获取年龄为10的结果集:"+ageListStr);
复制代码
3.3 等于某个值查询单个:fetchFirst的用法:
QUser user = QUser.user;
//fetchFirst的用法: 单表获取年龄为10的首个结果
User user1 = jpaQueryFactory.selectFrom(user).where(user.age.eq(10)).fetchFirst();
System.out.println("单表获取年龄为10的首个结果:"+user1.toString());
复制代码
3.4 模糊检索的用法1(like关键字):
QUser user = QUser.user;
//模糊检索的用法:单表获取名称包含小的用户并且按照年龄倒排序
List<User> nameList = jpaQueryFactory.selectFrom(user).where(user.name.like("%小%")).orderBy(user.age.desc()).fetch();
String nameListStr = JSON.toJSONString(nameList);
System.out.println("单表获取名称包含小的用户并且按照年龄倒排序的结果集:"+nameListStr);
复制代码
3.5 模糊检索的用法2(startsWith):
QUser user = QUser.user;
//模糊检索的用法:单表获取名称是以小开头的用户并且按照年龄正序排
List<User> nameAscList = jpaQueryFactory.selectFrom(user).where(user.name.startsWith("小")).orderBy(user.age.asc()).fetch();
String nameAscListStr = JSON.toJSONString(nameAscList);
System.out.println("单表获取名称是以小开头的用户并且按照年龄正序排的结果集:"+nameAscListStr);
复制代码
3.6 区间用法(between):
QUser user = QUser.user;
//between 区间的用法:单表获取开始时间是XX-XX 区间的用户
String time = "2019-07-22 00:00:00";
SimpleDateFormat df = new SimpleDateFormat("yyyy-MM-dd HH:mm:ss");
Date date= df.parse(time);
Timestamp nousedate = new Timestamp(date.getTime());
String time1 = "2019-07-23 00:00:00";
Date date1= df.parse(time1);
Timestamp nousedate1 = new Timestamp(date1.getTime());
List<User> beginTimeList = jpaQueryFactory.selectFrom(user).where(user.beginTime.between(nousedate, nousedate1)).fetch();
String beginTimeListStr = JSON.toJSONString(beginTimeList);
System.out.println("单表获取开始时间是XX-XX 区间的用户的结果集:"+beginTimeListStr);
复制代码
3.7 in的用法:
QUser user = QUser.user;
//in 的用法:单表获取年龄是10,20的用户
List<Integer> ageLists = new ArrayList<>();
ageLists.add(10);
ageLists.add(20);
List<User> ages = jpaQueryFactory.selectFrom(user).where(user.age.in(ageLists)).fetch();
String agesStr = JSON.toJSONString(ages);
System.out.println("单表获取年龄是10,20的用户的结果集:"+agesStr);
复制代码
3.8 聚合函数max,avg,min的用法:
QUser user = QUser.user;
//聚合函数-concat()的使用:单表查询将用户id,名称,年龄拼接的结果
List<String> concatList = jpaQueryFactory.select(user.id.concat(user.name).concat(user.age.stringValue())).from(user).fetch();
String concatListStr = JSON.toJSONString(concatList);
System.out.println("单表查询将用户id,名称,年龄拼接的结果:"+concatListStr);
复制代码
3.9 聚合函数groupby的用法:
QUser user = QUser.user;
List<Map<String,Object>> tupleJPAQuery = jpaQueryFactory.select(user.age, user.count().as("count")).from(user).groupBy(user.age)
.fetch().stream().map(x->{
Map<String,Object> resultMap = new HashMap<>();
resultMap.put("age",x.get(0,QUser.class));
resultMap.put("count",x.get(1,QUser.class));
return resultMap;
}).collect(Collectors.toList());
String userQueryResultsStr = JSON.toJSONString(tupleJPAQuery);
System.out.println("单表分组的结果集:"+userQueryResultsStr);
复制代码
3.10 多条件拼接的使用(BooleanBuilder):
QUser user = QUser.user;
//多条件处理
BooleanBuilder booleanBuilder = new BooleanBuilder();
booleanBuilder.and(user.age.eq(10));
booleanBuilder.and(user.name.contains("小"));
List<User> mostlist = jpaQueryFactory.selectFrom(user).where(booleanBuilder).fetch();
String mostlistStr = JSON.toJSONString(mostlist);
System.out.println("单表查询多条件处理的结果:"+mostlistStr);
复制代码
3.11 分页查询的处理:
QUser user = QUser.user;
QueryResults<User> userQueryResults =
jpaQueryFactory.selectFrom(user).offset(0).limit(2).fetchResults();
String userQueryResultsStr = JSON.toJSONString(userQueryResults);
System.out.println("单表分页的结果集:"+userQueryResultsStr);
复制代码
正文到此结束
- 本文标签: maven cat API XML http id tab tar 管理 json entity IO web IDE Select src plugin 2019 java js UI parse build ORM stream spring https 配置 CTO 分页 bean ArrayList git map 时间 插件 Persistence HashMap struct sql 代码 list JPA springboot servlet 安全 GitHub value maven构建 Spring Boot
- 版权声明: 本文为互联网转载文章,出处已在文章中说明(部分除外)。如果侵权,请联系本站长删除,谢谢。
- 本文海报: 生成海报一 生成海报二
热门推荐










相关文章

近期评论
-
你这基本没有更新呀,最近文章显示还是2019年的文章。不符合要求哈
-
关键词:慕云博客 链接:https://www.lilun.me 描述:分享原创文字的个人博客
-
-
-
可以提供一下源码吗
-
不是商业站,鸡娃学习笔记
-
-
-
-
听他们说很厉害的样子
Loading...
![[HBLOG]公众号](http://www.liuhaihua.cn/img/qrcode_gzh.jpg)

