自动识别 Android 不合理的内存分配

写在前面
Android开发中我们常常会遇到不合理的内存分配导致的问题,或是频繁GC,或是OOM。 按照常规的套路我们需要打开Android Studio录制内存分配或者dump内存,然后人工分析,逐个排查问题所在。 这些方法是官方提供的能力,可以帮助我们排查问题,但难免有些繁琐,效率比较低。
如果可以自动识别出不合理的Java(含Kotlin)对象分配,这样繁琐的工作将会变得简单。
本文介绍了一种在Art虚拟机上实时记录对象分配的实现方案,基于此方案就可以实现不合理对象分配的自动化的识别。
常规方案对比分析
| 方案 |
优势 |
不足 |
| Dump内存 |
可以自动化 |
无法反映出内存分配的过程 |
| 录制对象分配 |
可以看到每次内存分配的情况 |
需要手动启动,无法自动化 |
| 字节码插桩 |
可以自动化 |
无法记录不在业务代码内的内存分配 |
Dump内存和字节码插桩的方案都无法覆盖运行过程中内存分配的过程,无法满足自动识别的诉求。 而录制的方案目前主要的问题是,不能自动化,如果能实现录制内存分配的自动化,就可以完成我们想要做的事情。
让录制对象分配自动化
1 . 模仿
Android Studio是 开源 的,因此我们很容易在它的源码里找到一些功能的实现。 录制内存分配的代码在ToggleAllocationTrackingAction这个类里。 精简后的流程如下:

建立ADB连接、构造请求这些都是IDE做的事情,我们需要模拟IDE做这些事情吗? 不需要。 我们只需要关注DdmVmInternal是怎么做的即可,很幸运,Android系统源码的一段测试代码直接告诉了我们如何反射调用DdmVmInternal提供的能力,源码位置在<android src>/art/test/098-ddmc/src/Main.java,这里代码就不贴了。
2 . 转折
调用DdmVmInternal的方法,成功的在App里开启了内存分配的录制,也成功的拿到了每次内存分配的数据。 但如果以为事情就这样OK了,还早了一些。 万万没想到,这接口虽然易用,但用得并不爽,有三点:
-
最多只能65535条记录(size的类型是双字节无符号数)。
-
录制时对性能影响很小,但每次获取录制记录时特别慢(开发机实测JDWP封包5秒以上,解包处理10秒以上)。
-
每次获取到的记录可能有重复,要使用这个数据需要额外做合并去重的操作。
这些不爽的点似乎都很冗余,能不能直接一点呢?
3. 突破
DdmVmInternal的实现是放在native层的,顺藤摸瓜,我们找到了虚拟机里实现内存分配录制的源码,此处是Android5.1的源码,其他版本有差异,后面会讲到。
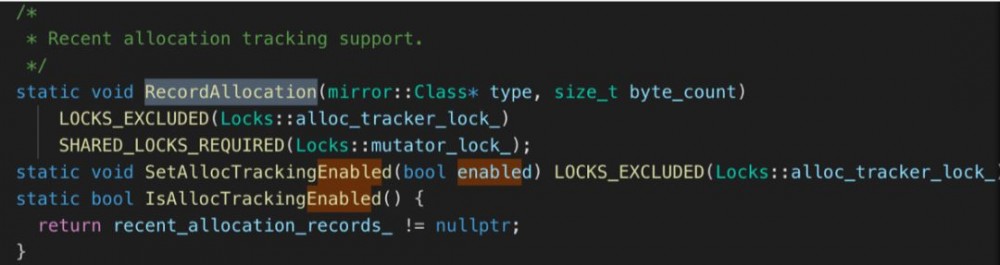
这里的 关键函数是RecordAllocation ,所有对象的内存分配都会经过这个函数,因此我们可以Hook这个函数来捕捉到内存分配的事件。
怎么hook ?
| 方案 |
优势 |
不足 |
| PLT Hook |
修改 PLT 表的跳转地址,风险低,易操作 |
使用场景有限,只能 Hook 一些被外部调用的函数 |
| Inline Hook |
汇编指令级别修改,几乎能修改所有逻辑 |
修改汇编指令涉及繁琐的指令修复工作,有一定门槛 |
显然,PLT Hook并不适合我们的场景,好在目前Inline Hook技术也已经比较成熟,看雪有不少大佬都分享了自己的框架,我们要使用Inline Hook无需再处理那些繁琐的指令修复
( 关于hook技术的细节在最后的参考文章里有列举,有兴趣的同学可以翻阅 )。
至此,我们已经可以捕获到所有的对象分配事件了,但这只是我们迈出的一小步。
让对象分配可被跟踪
为了让对象分配可被跟踪,我们至少需要三个信息: 这是什么对象 ; 分配了多大内存 ; 它是怎么分配的 。 这几个点看似清楚明了,但怎么做,还需要小费一番周折。
1 . 分配了多大内存
这个信息最容易获取,如果你还记得RecordAllocation函数的定义,你会发现byte_count已经作为参数传进来了。 没错,就是这么简单。
2 . 这是什么对象
你也许已经发现RecordAllocation还有一个参数是art::mirror::Class*,这是Java里Class在虚拟机里的镜像,我们知道Java里拿到Class,就能直接调用getName方法知道这个类是什么。 然鹅,在虚拟机的源码里,GetName函数有是有,但是是内联函数,我们没有办法拿到这个函数的地址。

这个咋整? 不要方,我们继续看源码,就在不远处,有一个叫个GetDescriptor的函数。

可以说是业界良心了,我们通过dlsym就可以拿到这个函数的地址,然后调用它,传入我们已经拿到的art::mirror::Class*和一个std::string,就可以拿到类名(实际上是类的描述)。
3 . 它是怎么分配的
要知道一个对象是怎么分配的,我们需要拿到它的调用栈,Ok,我们来看看虚拟机里面怎么做的。

这个能模仿实现吗? 多番查探,发现每个关键节点的实现都是内联函数。 咋办呢?
古人说“山重水复疑无路,柳暗花明又一村”。 既然源码层面不能给我们更多的启示了,那回头想想平时会怎么做。 是的,我们在写Java代码的时候,如果要获得当前的调用栈,一般就直接Thread.currentThread().getStackTrace()。既然这么容易,那我们直接在native层通过jni调用java的方法不就可以拿到调用栈了吗?事实也正是如此。于是,整个流程顺下来就是这样的。
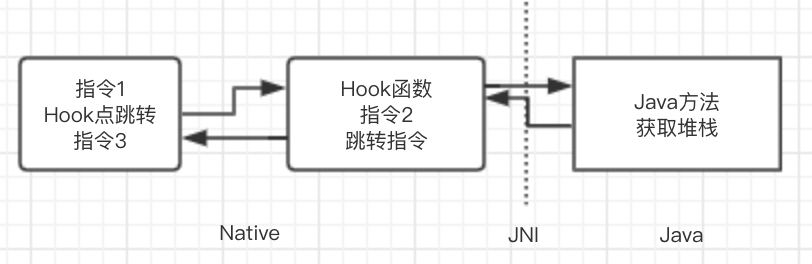
4. 发现不合理的对象分配
找到了合适的时机,又收集到了需要的数据,跟踪发现不合理的对象分配就很容易了。 我们可以发现某一次分配的大对象,也可以按照类名或者分类统计对象分配的频率等等,还可以做更多定制化的监控~
全版本支持
前面提到的方案已在Android5.x版本上验证OK,指定机型跑自动化是可以的,但目前主流的开发设备是Android7.x甚至更高的版本,如果要在开发阶段就能自动发现内存分配的问题,显然不够的。
是否可以把前面的方案直接应用在Android 6.x-9.x呢? 答案是没那么容易。 我们先来看下后续版本虚拟机里的一些改动。
| 系统版本 |
差异点 |
新增挑战点 |
| 6.x |
RecordAllocation函数新增一个参数Thread* |
无 |
| 7.x |
1. so权限收紧 2. RecordAllocation传入的mirro::Class*变成了mirror::Object** |
1. 应用无法通过dlsym查询函数地址 2. mirror::Object无法与mirror::Class对应 |
| 8.x-9.x |
RecordAllocation传入的mirror::Object**变成了ObjPtr<Object*>* |
无法直接访问到Object* |
对于我们的方案来讲,主要的挑战集中在Android7.x及以上版本,我们来看看这些问题如何各个击破。
1 . 绕过so访问权限问题
Android7.0开始,要想动态链接非NDK公开的so需要System或者Root权限,普通的app是做不到的。 如果尝试链接或者通过dlopen去打开,要么看到Permission Denied的错误提示,要么直接Crash。
既然直接的方案不行,那就想办法绕过去。
1.1 获得so基址
我们知道,Android是基于Linux的操作系统,Linux操作系统每个进程都有一个maps文件记录了所有模块在内存里起始地址,路径是/proc/<pid>/maps,这里pid就是进程的pid,访问自己进程用别名/proc/self/maps也可以。 这个文件很关键,我们看看它里面是什么。

libart.so是虚拟机的so,可以看到这里它的起始地址是0xeaf18000。
函数的地址就是基址+偏移,现在基址已有,就差偏移了,偏移怎么拿? 因为每个ROM的so多少都有差别,这个偏移肯定不能是hardcode的,我们要想办法查到函数的偏移。 一般来说有两种办法,第一种是无脑搜函数特征。
1.2 搜索函数地址 之 函数特征
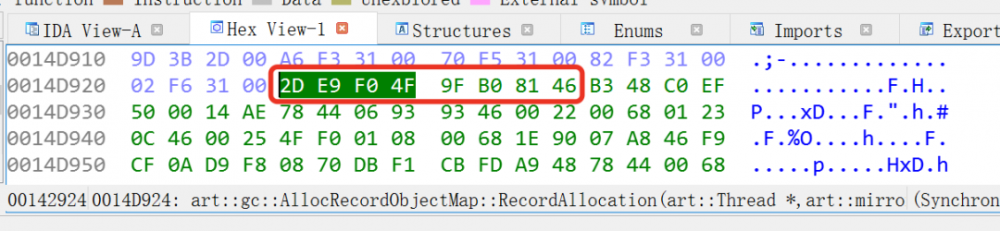
这图IDA打开一个Android7.1的libart.so查到的RecordAllocation函数的二进制。 这个二进制的前8个或16个字节就可以用来作为这个函数的特征,我们在libart.so的内存区域内匹配这个特征就可以定位到这个函数了。
这个方法有个明显的缺点,因为ROM厂家很有可能会修改虚拟机的代码,或者修改编译参数,这种通过函数特征去定位函数的办法最多只能作为特殊机型的兼容逻辑。 我们应该用一种更通用的方法,那就是直接解析ELF
1.3 搜索函数地址 之 解析ELF
so是一种ELF格式的文件,在Android系统里由linker加载到内存。 关于ELF的格式,网上很容易找到,各种结构贴出来很长,这里不赘述。 虽然Android限制了我们dlopen打开NDK非公开的so,但本质上,这些so对我们的进程来说是有可读权限的,所以解析ELF格式来查找函数的偏移是可行的,按照ELF的格式去解析就可以了,代码没有特别值得拎出来说的,但在实现的时候仍然有一些细节。
如果只是参考ELF的结构,我们能想到的直观的办法就是: 遍历字符串表,找到目标函数名的偏移; 然后遍历符号表,找到目标函数的偏移地址。 这样的做法没毛病,但效率不够高,因为是遍历,所以复杂度为O(n)。
事实上,如果看过linker的源码,我们会发现,还有一个更高效的O(1)的查询办法。 so里有一个section名字是.hash(有的是.gnu_hash,只是hash函数不同,但基本逻辑是一样的),它里面存储的其实是函数符号的索引。 我们参考linker的实现,把函数名(符号名)做一个hash,就可以在这个hash setion里面找到目标函数在符号表的索引,进而拿到函数的偏移地址。
解析ELF这种方案更通用,也是我最终采用的主要的方案 。
2 . 突如其来的SIGILL
解决了获取函数地址的问题,运行时发现Hook了搜索出来的函数就Crash了,系统抛了一个SIGILL的信号结束了我的进程。 SIGILL表示Illegal Instruction ,这很有可能是我们的函数地址有问题。
不过基址是系统加载so时记录的,这个应该不会有错; 搜索出来的函数偏移和用IDA查看的函数偏移也是一致的。 问题到底在哪?
此时,我想到虽然NDK限制了对非公开so的权限,但我自己的so,就可以用dlsym来查找函数地址。 于是写了一个demo,发现一个“不可思议”的事实: dlsym查到的函数地址 比 我搜索出来的函数地址 刚好大了1。
刚好大1,这绝非巧合。
这有点触及到知识盲区了,翻阅了不少讲解ARM汇编的文章,终于找到了答案。 原来ARM汇编编译时有ARM指令和THUMB指令两种,ARM指令为4字节,支持按条件执行; 而THUMB指令为2字节,不支持按条件执行。 由于大部分场景都无需按条件执行,所以编译成THUMB指令,so更加紧凑。 由于4字节和2字节都是偶数,地址的最低位实际上是用不上的,ARM设计时就巧妙的将地址的最低位置1来表示要按照THUMB指令来解析了。
这就是刚好大1的原因。 我们看到IDA反编译出来的RecordAllocation函数也可以清楚的看到,确实一条指令是2个字节,所以我们在实现的时候,要把搜索出来的地址做加1的修正。

3 . 通过art::mirror::Object获取类名
关于mirror::Object无法获取类名的问题,主要是因为它里面所有跟mirror::Class相关的函数全部是内联函数,我们在实现的时候很难突破。 还是那句话,既然往里走不行,那就试着走出来。 我们可以拿到调用栈,那是否可以通过解析调用栈来获取当前分配的是什么对象呢?
答案是否定的。 一方面是因为解析调用栈涉及字符串匹配操作,频繁的字符串匹配操作,对性能的损耗是不太能接受的; 另一方面是因为解析堆栈无法覆盖所有的对象分配(并非所有的对象分配都会经过<init>方法,例如 byte[])。
mirror::Object是Java里Object在虚拟机的镜像,那我们是否有办法通过mirror::Object拿到Java的Object的引用呢? 通过搜索以mirror::Object作为参数的函数,我找到了突破口。

这是JNI的一个函数,可以把mirror::Object转成jobject,而jobject就是Java里Object在JNI层的表示。 到了这一步,要获取类名就非常简单了,obj.getClass().getName()即可。
关于Android8.x及以上系统,把mirror::Object**改成ObjPtr<Object*>*的处理,就比较简单了,ObjPtr类定义比较简单,我们照着源码里的ObjPtr实现一个结构一样的class,就可以访问到里面包裹的mirror::Object*了。
业务实践
我们的业务已经开始尝试用NewMonkey做自动化测试,检测到不合理的分配内存的场景,就记录并上报。
正文到此结束
热门推荐










相关文章

近期评论
-
你这基本没有更新呀,最近文章显示还是2019年的文章。不符合要求哈
-
关键词:慕云博客 链接:https://www.lilun.me 描述:分享原创文字的个人博客
-
-
-
可以提供一下源码吗
-
不是商业站,鸡娃学习笔记
-
-
-
-
听他们说很厉害的样子
Loading...
![[HBLOG]公众号](http://www.liuhaihua.cn/img/qrcode_gzh.jpg)

