Java反序列化漏洞原理解析(案例未完善后续补充)
序列化与反序列化
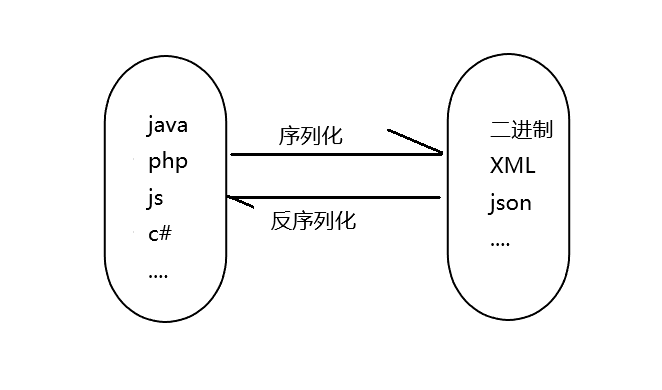
序列化用途:方便于对象在网络中的传输和存储
java的反序列化
序列化就是将对象转换为流,利于储存和传输的格式
反序列化与序列化相反,将流转换为对象
例如:json序列化、XML序列化、二进制序列化、SOAP序列化
-
序列化:
java.io.ObjectOutputStream类中的writeObject()该方法把对象序列化,将字节序列写到一个目标输出流中(.ser扩展名)
-
反序列化:
java.io.ObjectInputStream类中的readObject()从输入流中读取字节序列,再将其反序列化为对象
实现Serializable和Externalizable接口的类的对象才能被序列化。
漏洞危害
导致代码执行、文件操作、执行数据库操作等不可控后果
漏洞原理
如果Java应用对用户输入,即不可信数据做了反序列化处理,那么攻击者可以通过构造恶意输入,让反序列化产生非预期的对象,非预期的对象在产生过程中就有可能带来任意代码执行。
漏洞发现
存在于 WebLogic、WebSphere、JBoss、Jenkins、OpenNMS 等等
- HTTP请求中的参数,cookies以及Parameters。
- RMI协议,被广泛使用的RMI协议完全基于序列化
- JMX 同样用于处理序列化对象
- 自定义协议 用来接收与发送原始的java对象
漏洞挖掘
-
确定反序列化输入点
首先应找出readObject方法调用,在找到之后进行下一步的注入操作。一般可以通过以下方法进行查找:
-
源码审计:寻找可以利用的“靶点”,即确定调用反序列化函数readObject的调用地点。
-
对该应用进行网络行为抓包,寻找序列化数据,如wireshark,tcpdump等
黑盒流量分析(可能面试)
在Java反序列化传送的包中,一般有两种传送方式,在TCP报文中,一般二进制流方式传输,在HTTP报文中,则大多以base64传输。因而在流量中有一些特征:
(1)TCP:必有aced0005,这个16进制流基本上也意味者java反序列化的开始;
(2)HTTP:必有rO0AB,其实这就是aced0005的base64编码的结果;
以上意味着存在Java反序列化,可尝试构造payload进行攻击。
黑盒java的RMI
RMI是java的一种远程对象(类)调用的服务端,默认于
1099端口,基予socket通信,该通信实现远程调用完全基于序列化以及反序列化。白盒代码审计
(1)观察实现了Serializable接口的类是否存在问题。
(2)观察重写了readObject方法的函数逻辑是否存在问题。
-
-
再考察应用的Class Path中是否包含Apache Commons Collections库
-
生成反序列化的payload
-
提交我们的payload数据
漏洞防御
-
类的白名单校验机制:
实际上原理很简单,就是对所有传入的反序列化对象,在反序列化过程开始前,对类型名称做一个检查,不符合白名单的类不进行反序列化操作。很显然,这个白名单肯定是不存在Runtime的。
-
禁止JVM执行外部命令Runtime.exec
这个措施可以通过扩展 SecurityManager 可以实现。
正文到此结束
热门推荐










相关文章






Loading...
![[HBLOG]公众号](http://www.liuhaihua.cn/img/qrcode_gzh.jpg)

