Spring -- Cache原理
Spring Cache并不是一种缓存的实现方式,而是缓存使用的一种方式,其基于Annotation形式提供缓存存取,过期失效等各种能力,这样设计的理由大概是缓存和业务逻辑本身是没有关系的,不需要耦合到一起,因此使用Annotation修饰方法,使得方法中只需要关心具体的业务逻辑,并不需要去关心缓存逻辑。
Spring Cache相关实现逻辑都在Spring Context的 org.springframework.cache
包中,有兴趣可以直接翻阅源代码学习。
使用
注册缓存管理器
Spring Cache提供的缓存管理主要分为 CacheManager
用于管理多个缓存,以及 Cache
用户具体缓存存放实现,结构如下图所示。
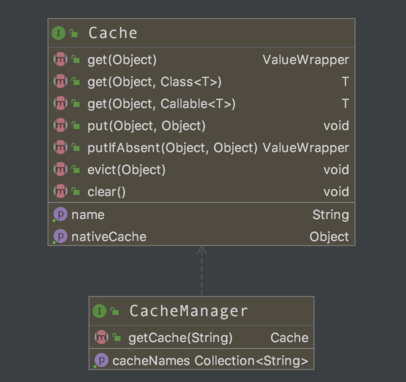
关于 CacheManager
的配置主要有基于Spring Boot的自动配置类 CacheAutoConfiguration
,用户可以自定义 CacheManagerCustomizer
往缓存管理器中实例化具体缓存类,如下图所示,该配置会自动选择缓存的实现,然后在实例化前调用对应的 CacheManagerCustomizer
执行用户业务逻辑。
@Component
public class SimpleCacheCustomizer implements CacheManagerCustomizer<ConcurrentMapCacheManager> {
@Override
public void customize(ConcurrentMapCacheManager cacheManager) {
cacheManager.setCacheNames(Lists.newArrayList("quding","mrdear"));
}
}
自动配置在我看来相当黑盒,实际开发中可能由于jar间接引用等问题,导致缓存初始化错误,因此比较建议手动配置。Spring有一套缓存实现推荐,基于内存的Caffeine,基于文件Ecache,分布式缓存Redis等等,可以根据自己的业务需求选择实例化对应缓存管理器类。
// 实例化一个基于内存的缓存管理器, 其内部有users,addresses两个Cache对象。
@Bean
public CacheManager cacheManager() {
return new ConcurrentMapCacheManager("users","addresses");
}
// 实例化一个基于Caffeine的缓存管理器,其内部有users,addresses两个Cache对象。
@Bean
public CacheManager cacheManager() {
return new CaffeineCacheManager("users","addresses");
}
CacheManager
并没有提供定制 Cache
的方法,因此如果需要定制,则需要考虑继承,复写相关方法,以 CaffeineCacheManager
为例,假设我需要users缓存使用LRU淘汰策略,那么我就需要复写其 org.springframework.cache.caffeine.CaffeineCacheManager#createNativeCaffeineCache
方法,实现自定义缓存创建。
不是很理解,为什么Spring没有对此开放接口,业务中所有缓存不可能都使用同一套策略。
使用缓存
Spring Cache提供了四个Annotation方便开发人员使用缓存,而不建议直接访问 CacheManager
自己做定制,具体如下表格所示:
| 注解 | 描述 |
|---|---|
| Cacheable | 存在则从缓存取,不存在则执行方法,结果放入到缓存 |
| CacheEvict | 将方法操作对象缓存删除 |
| CachePut | 无论方法是否存在都会将执行结果放入到缓存中 |
| Caching | 以上三种的组合 |
以 Cacheable
的使用为例,如下代码所示,该注解实现了缓存id大于1的所有用户实例,其背后原理是什么呢?
/**
* 结果放入缓存users中
* 使用缓存管理器为(bean名) cacheManager
* 缓存key为 参数id
* id小于2的不缓存
*/
@Cacheable(cacheNames = "users", cacheManager = "cacheManager", key = "#id", unless = "#id < 2")
public User findById(Long id) {
logger.info("query user={} from db ", id);
return new User(id);
}
实现原理
Spring注册缓存管理器后,会对需要缓存方法对应的类进行AOP处理,核心逻辑为自定了一个 MethodInterceptor
拦截器 org.springframework.cache.interceptor.CacheInterceptor
,该拦截器会将方法调用转到 CacheAspectSupport.execute()
中,如下代码所示。
其中 invoker
为对应的方法执行器, CacheOperationSource
为存储缓存操作的工厂,比如上述 @Cacheable(cacheNames = "users", cacheManager = "cacheManager", key = "#id", unless = "#id < 2")
就可以理解为一个针对findById的缓存操作,一个方法可以被多个注解修饰,因此这里是可以拿到多个的。
@Nullable
protected Object execute(CacheOperationInvoker invoker, Object target, Method method, Object[] args) {
// Check whether aspect is enabled (to cope with cases where the AJ is pulled in automatically)
if (this.initialized) {
Class<?> targetClass = getTargetClass(target);
// 存储所有缓存操作的池子,一个注解可以理解为一次缓存操作
CacheOperationSource cacheOperationSource = getCacheOperationSource();
if (cacheOperationSource != null) {
// 根据 方法 + 类 定位对应的缓存操作
Collection<CacheOperation> operations = cacheOperationSource.getCacheOperations(method, targetClass);
if (!CollectionUtils.isEmpty(operations)) {
// 下一步调用
return execute(invoker, method,
new CacheOperationContexts(operations, method, args, target, targetClass));
}
}
}
return invoker.invoke();
}
方法调用与缓存获取主要实现逻辑如下所示,代码中都已经标识好了注释,其中值得关注的是 Cacheable
, CachePut
操作的区别, Cacheable
会优先去缓存里面获取,缓存获取到了,且当前没有对应的 CachePut
操作,则不会再次调用方法。 CachePut
则只要存在,就一定会再次调用方法处理。
@Nullable
private Object execute(final CacheOperationInvoker invoker, Method method, CacheOperationContexts contexts) {
....
// 从命令中,取出过期指令,优先处理
processCacheEvicts(contexts.get(CacheEvictOperation.class), true,
CacheOperationExpressionEvaluator.NO_RESULT);
// 获取对应的缓存
Cache.ValueWrapper cacheHit = findCachedItem(contexts.get(CacheableOperation.class));
// 缓存不存在,则从context中获取 PUT命令
List<CachePutRequest> cachePutRequests = new LinkedList<>();
if (cacheHit == null) {
collectPutRequests(contexts.get(CacheableOperation.class),
CacheOperationExpressionEvaluator.NO_RESULT, cachePutRequests);
}
Object cacheValue;
Object returnValue;
// 缓存命令,且不存在PUT
if (cacheHit != null && !hasCachePut(contexts)) {
// If there are no put requests, just use the cache hit
cacheValue = cacheHit.get();
returnValue = wrapCacheValue(method, cacheValue);
}
else {
// Invoke the method if we don't have a cache hit
// 存在PUT指令则会执行真实调用
returnValue = invokeOperation(invoker);
cacheValue = unwrapReturnValue(returnValue);
}
// 根据结果,从context中获取需要执行的put命令
collectPutRequests(contexts.get(CachePutOperation.class), cacheValue, cachePutRequests);
// 执行PUT操作
for (CachePutRequest cachePutRequest : cachePutRequests) {
cachePutRequest.apply(cacheValue);
}
// 根据结果处理过期命令
processCacheEvicts(contexts.get(CacheEvictOperation.class), false, cacheValue);
return returnValue;
}
缓存key生成策略
Spring默认使用SpEL作为key生成的表达式语言,同时还额外提供了 org.springframework.cache.interceptor.KeyGenerator
接口,让用户实现自己的生成策略,可以说是非常灵活了。这里推荐使用 自定义方案
,否则每次都要额外创建EL上下文,然后解析,虽然是轻量操作,但该操作会很频繁。
/**
* Compute the key for the given caching operation.
*/
@Nullable
protected Object generateKey(@Nullable Object result) {
// 当没指定key,则使用SpEL生成该key
if (StringUtils.hasText(this.metadata.operation.getKey())) {
EvaluationContext evaluationContext = createEvaluationContext(result);
return evaluator.key(this.metadata.operation.getKey(), this.metadata.methodKey, evaluationContext);
}
// 使用自定义key生成策略
return this.metadata.keyGenerator.generate(this.target, this.metadata.method, this.args);
}
// EL上下文创建,可以看到其能获取到的信息,基本是参数中所有的值了
private EvaluationContext createEvaluationContext(@Nullable Object result) {
return evaluator.createEvaluationContext(this.caches, this.metadata.method, this.args,
this.target, this.metadata.targetClass, this.metadata.targetMethod, result, beanFactory);
}
总结
Spring Cache可以说是一套在Spring中使用缓存的标准规范,其最大的优势是解耦了缓存逻辑以及业务逻辑,并提供了统一缓存管理能力。
其背后的原理也比较容易理解,另外在设计上给我们提供了Annotation -> Operate -> Context -> Request的一种抽象解决问题模式,值得学习。
- 版权声明: 感谢您的阅读,本文由屈定's Blog版权所有。如若转载,请注明出处。
- 文章标题:Spring -- Cache原理
- 文章链接: https://mrdear.cn/2019/09/28/framework/spring/Spring--cache/
Spring -- 定时任务调度的发展
正文到此结束
热门推荐










相关文章

近期评论
-
你这基本没有更新呀,最近文章显示还是2019年的文章。不符合要求哈
-
关键词:慕云博客 链接:https://www.lilun.me 描述:分享原创文字的个人博客
-
-
-
可以提供一下源码吗
-
不是商业站,鸡娃学习笔记
-
-
-
-
听他们说很厉害的样子
Loading...
![[HBLOG]公众号](http://www.liuhaihua.cn/img/qrcode_gzh.jpg)

