高可用-雪崩效应应对策略
概念
在发生系统Bug、上流流量突增、依赖系统异常等情况时,最坏的情况是发生连锁反应,故障像滚雪球一样越滚越大,最终造成雪崩。
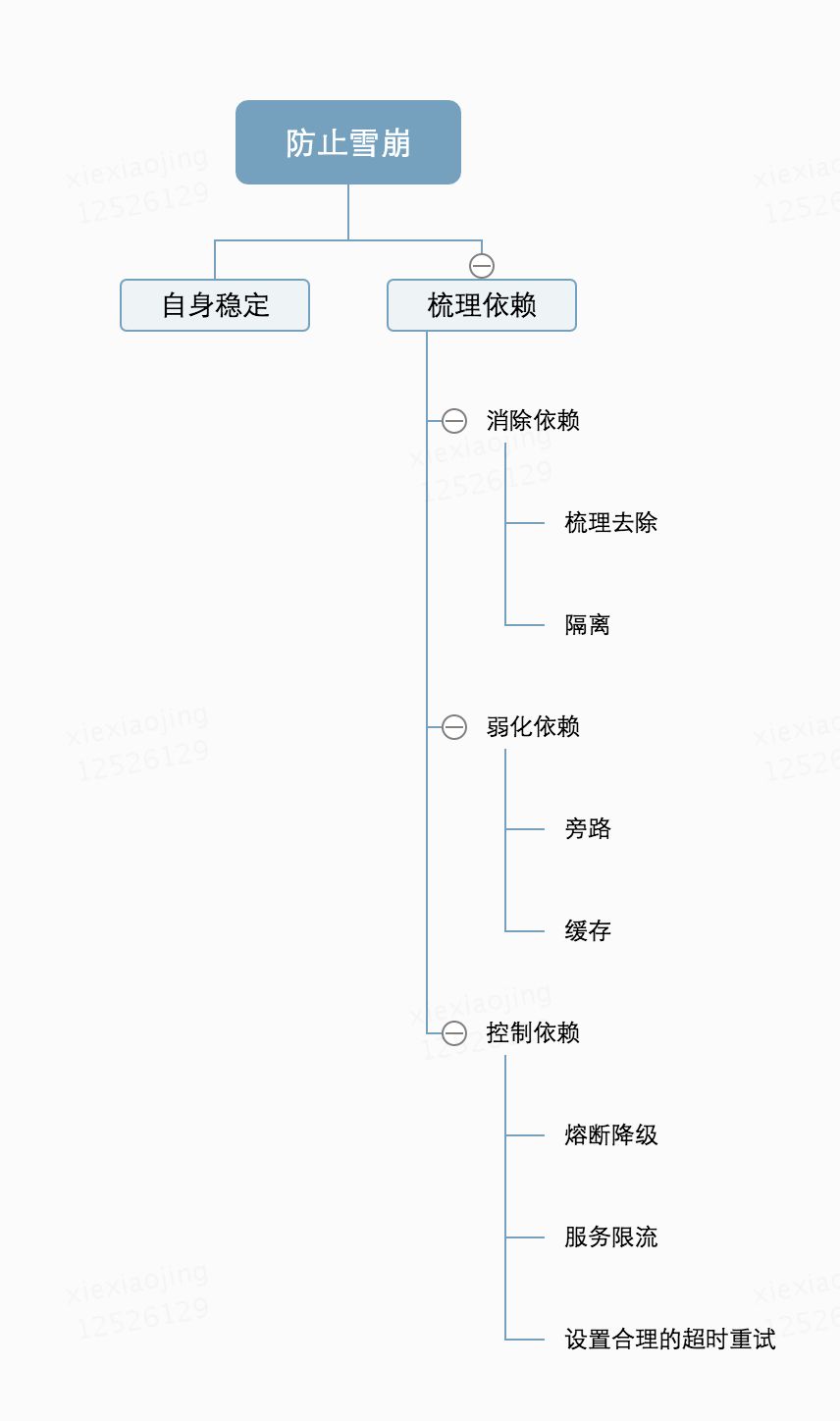
在雪崩问题中,有两个角色。一个是始作俑者,自身系统有问题引起别的系统问题,那就梳理解决问题,没什么说的。另一个是被殃及的池鱼。系统如果希望别的系统问题尽量减少对自身的影响,建议定期对自身系统的依赖做梳理,尽量自治。对依赖系统进行:消除依赖、弱化依赖和控制依赖。
-
消除依赖的主要手段有梳理去除、隔离。
-
弱化依赖的主要手段有旁路、缓存。
-
控制依赖的主要手段有熔断降级、服务限流、设置合理的超时重试。
应用
在控制依赖中,介绍熔断降级和服务限流的文章很多。hystrix作为这方面的业界标杆,里面内置了这些问题的解决方案。很多朋友问我怎么设置超时重试更为合理的问题,今天我着重说一下自己在这方面的实践。可能有自身的思维盲点,欢迎指出。
设置合理的超时重试
在传统的单机系统中,调用一个函数,要么返回成功,要么返回失败。这就是两态系统(2-state system)。在分布式系统中,由于系统是分布在不同机器上的。还可能有一种状态叫:超时。成功、失败和超时是分布式系统调用的三态。
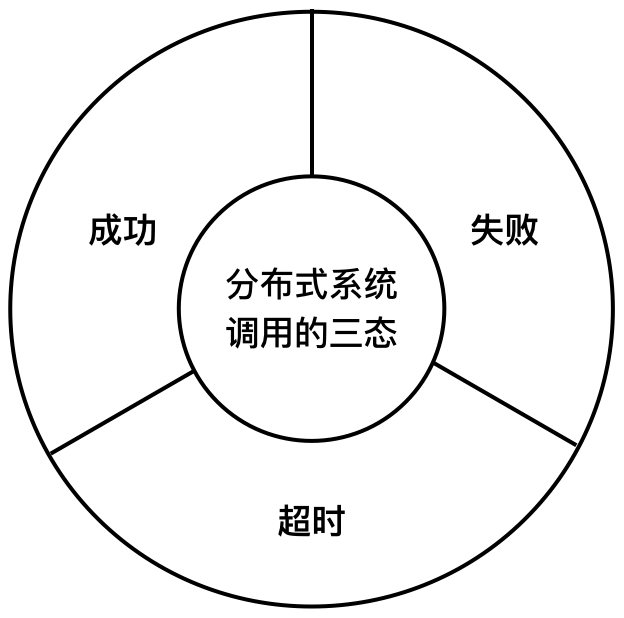
对于超时这种状态,长时间等待会影响用户体验,并发量大时还可能会因为线程池耗尽而不能响应其他请求。如果这个服务的调用方也是一个服务,那就有可能产生级联反应,导致其他服务不可用,最终产生雪崩效应。
但是如果直接将超时熔断,请求就会失败,所以对应核心调用,还需要进行重试。那么怎么设置超时和重试更为合理呢?
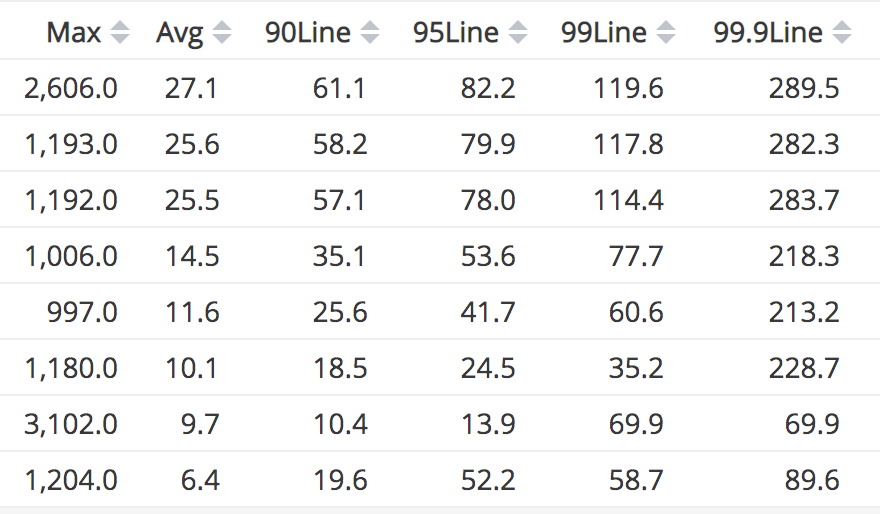
上面是随便选取了8个接口的调用一个月的耗时情况,基本代表了我们服务接口的一般情况:平均耗时(Avg列)和百分之99.9的请求耗时(99.9Line列)之间相差近10倍,百分之99.9的请求耗时和最大耗时(Max列)之间相差也是数倍。而这个耗时的差别和接口本身入参差异引起的复杂度无关,有可能当时JVM在进行GC。事实上,总体耗时情况是符合正态分布的,正态分布就面临着「长尾效应」。这时候与其等待到最后正常返回不如丢弃请求重试更快的得到响应。我们选择对于核心接口的超时策略是不低于百分之99.9的请求耗时作为超时时间。重试默认重试三次,对于不承诺SLA的下游服务,适当增加重试次数。 工具方面,使用java的项目可以考虑使用 guava-retrying重试工具库。 在一个工程中,使用次数多的话,可以考虑实现一个切面,用注解的方式使用。
上面提到超时时间是 不低于百分之99.9的请求耗时作为超时时间, 重试默认重试三次,对于不承诺SLA的下游服务,适当增加重试次数。能不能有个确切的计算方法能够达到最短的平均响应时间呢?答案是否定的。
我曾经专门花了三个小时的时间在头脑中就这种方法做了推演:证明了请求响应时长的随机性和独立性,就是说符合独立同分布的中心极限定理,也就是论证了它确实是符合正态分布的。但是这一规律的论证并没有给实现带来多大的益处。
比如系统压力较低的时候,实际上一个请求调用下流时,如果同时异步发送两个请求,取最先返回的结果,丢弃后返回的结果,那么99%的请求可以在TP90的时间内返回。如果同时异步发送三个请求, 取最先返回的结果,丢弃后返回的结果,那么99.9%的请求可以在TP90的时间内返回。这样理论上可以通过增大并发请求数来减少响应时间。听起来很美好。但是这个方案有个前提:系统压力低、请求的返回值小不会因为三倍的请求而阻塞带宽和IO、相同的请求需要打到不同的服务器上,不然都在同一个服务器上,这个服务器在进行GC的话,都会耗时很长。三倍的外部调用,产生三倍的数据,这三倍的数据都涉及垃圾回收,会增大gc的时间,不管是minor gc还是full gc都需要stop the world,增加系统响应时长。关键问题是:如果每次都以最短耗时返回了,原本应该的TP90的耗时就变成了Min(TP90one,TP90two,TP90three)的耗时,在以后的统计中真正的TP90怎么得出?……推演下去的结论是通过算法或者AI求最优解时不收敛。
总结
如果整篇文章你只能记住一件事,那么请记住: 消除依赖、弱化依赖和控制依赖
正文到此结束
热门推荐










相关文章






Loading...
![[HBLOG]公众号](http://www.liuhaihua.cn/img/qrcode_gzh.jpg)

