HashMap里面的hashcode()详解
在聊 hashcode() 的作用之前,我们首先需要了解什么是散列表。散列表是一种数据结构,它的英文名称叫 Hash Table , 也是我们平常称的'哈希表',或者 'Hash表'。散列表是一种支持利用数组下标实现随机访问的数据结构,也可以理解成散列表是一种数组的扩展。
下面我举个例子解析一下,在某次校运动会有 100 名选手参加,为了便于记录他们每个选手的成绩,选手会依次被贴上属于自己的号码编号。假设他们的编号是 1 到 100 依次编号。现在我们需要通过编程的方式,怎样才可以快速地拿到指定编号选手的成绩呢?
通常我们会构建一个一维数组,然后把编号为 1 的选手信息放在下标为 0 的数组位置、把编号为 2 的选手信息放在下标为 1 的数组位置,以此类推,把编号为 100 的选手信息放在数组下标为 99 的位置里面。当我们现在想拿到编号为 x 的选手信息,我们只需要在数组下标为 y 的位置把选手的信息拿出来就可以的,这个取选手的信息的过程的时间复杂度为 O(1), 这样子的效率是不是很高?
扩展:为什么数组根据数组下标的随机访问可以做到时间复杂度为 O(1) 呢?
实际上,这个例子已经包含了散列思想了。在这个例子中,选手编码 x 和数组下标 y 可以组成的表达式:

其中,运动员选手的编号我们叫做键(key)或者关键字。我们用来标识一个选手。然后我们把参赛编号转化为数组下标的映射方法就叫做散列函数(或者 Hash函数、哈希函数),而散列函数计算得到的值就叫做散列值(或者 Hash 值、哈希值)。
由上面的例子,我们可以总结出这样的规律:散列表用的就是数组支持按照下标随机访问的时候,时间复杂度为 O(1) 的特性。我们通过散列表函数把元素的键值映射为下标,然后将数据存储在数组中对应下标的位置。当我们需要查询数组的元素的时候,同样需要把元素的键值通过散列函数映射成对应的数组下标,然后通过数组的下标找到对应的元素。
HashMap 如何实现查询 Value 的高效性
在聊 HashMap 如何实现查询 Value 的高效性之前,我们先复习一下在线性表里面查询一个指定的元素,假设这个线性表的长度为 1000,如果顺序查找,那么最差的时间复杂度为 O(1000),而采用二分查找,最差的时间复杂度也是需要 O(500)。
而在 HashMap 中,则是非常依赖于哈希码的有效性。在 HashMap 内部的结构,它可以看作是数组(Node<K,V>[] table)和链表结合组成的复合结构。并且放在 HashMap 中的数据和 HashMap 的内部结构中的数组是通过 hash() 相互关联的。
我们还是拿上面运动会的例子说明,假设一个 hash() 的表达式为 x-1, 变换成数学公式里面的 y = f(x), 其中 f(x) = x - 1(其中 x 表示的是选手的编号,y 表示的是数组的下标)。当我们知道某个选手的编号为 1,那么我们只需要通过该对应的 hash() 函数转换,即 1 - 1 = 0,那么得到的 0 便是数组的下标,那么我们就可以很快地得到编号为 1 的选手成绩信息。同样地,如果我们需要储存编号为 50 的选手成绩信息,那么我们只需要把 50 代进 hash() 里面,即 50 - 1 = 49,得到的 49 就是编号为 50 的选手可以储存的位置,效果如下图:

当然,在实际的 HashMap 中,hash() 可不是如上面的 f(x) = x - 1 一样简单。如下图(Java OpenJdk 11):
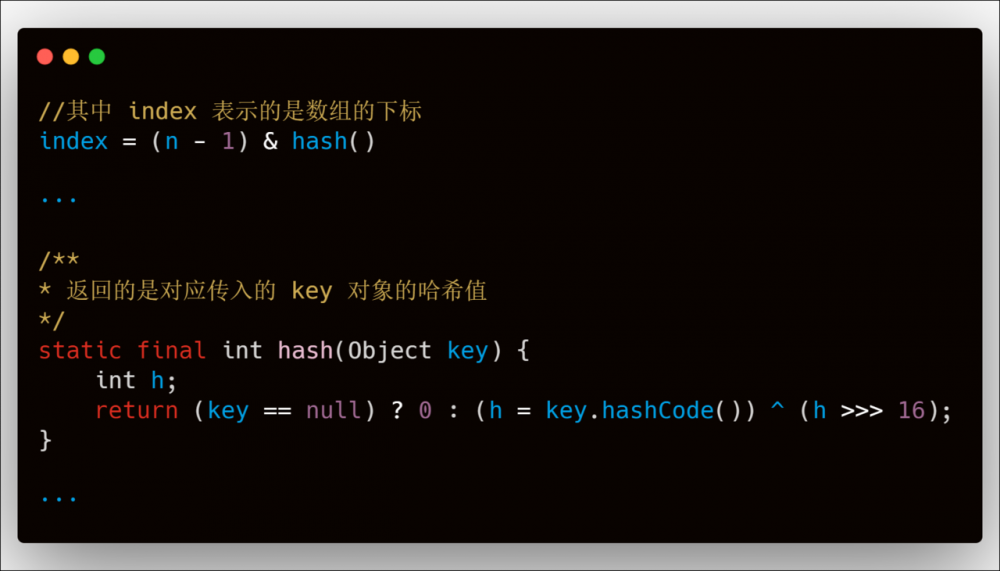
由上图观察可知,HashMap 里面的散列表数组下标的确定,有桶数组的长度 n 以及 hash() 函数确定。在 HashMap 中,但我们需要存储一对键值对的时候,我们需要把对应的键值装进 hash(Object key) 里面,转换成对应的哈希值以后,在通过与桶数组长度的运算,得到对应的桶数组下标,然后把对应的 Value 值存储在指定的数组下标的位置。同样地,如果我们根据键值得到 HashMap 中对应的 Value,那么我们需要进行存储的逆运算即可。
哈希碰撞
在实现 HashMap 的存和取操作之前,我们需要解决 HashMap 的哈希碰撞。我们知道,哈希算法是无法做到零冲突的,也就是说哈希算法存在哈希碰撞。这里基于组合数学里面的一个非常基础的理论,鸽巢原理(也叫抽屉原理)。这个原理描述的是如果有 10 个鸽巢,有 11 个鸽子,那么肯定有一个鸽巢中的鸽子数量是多于 1 个,换而言之,肯定存在着有 2 个鸽子在同一个鸽巢里面。
为了解决哈希碰撞,人们提出了两种主要的解决方法,开发寻址法和链表法。而 HashMap 主要采用了链表法解决哈希冲突。HashMap 解决哈希冲突的模型如下图:
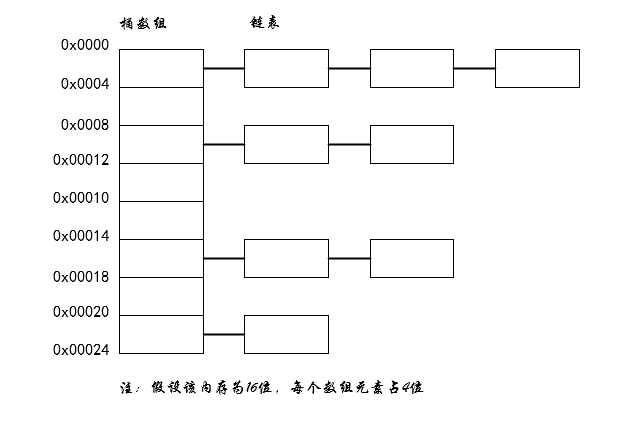
HashMap 的默认初始的桶数组大小为 16,而当产生哈希碰撞的时候,则把发生碰撞的值添加到链表中。在 JDK1.8 中,当链表的长度大于 8 的时候,链表就会转换为红黑树,利用红黑树快速增删查改的特性,从而优化提高 HashMap 的效率。同时,当链表的长度再次少于 8 的时候,红黑树又会转化为链表,因为红黑树需要维护平衡,在链表的个数比较少的时候,对 HashMap 提高的效率并不明显。
在重写 hashcode() 的时候,为什么需要重写 equals()?
有了上面的基础知识作为铺垫,有助于我们更好地理解在重写 hashcode() 的时候,为什么需要重写 equals() 方法。
在使用 HashMap 的时候,我们需要调用 HashMap 的 public 方法 put(K key, V value) , 把键值对传进到 HashMap 的实例里面( 在这篇文章里面约定,把传进 HashMap 的键值对,分别称为"键值"、Value值 )。如下图:
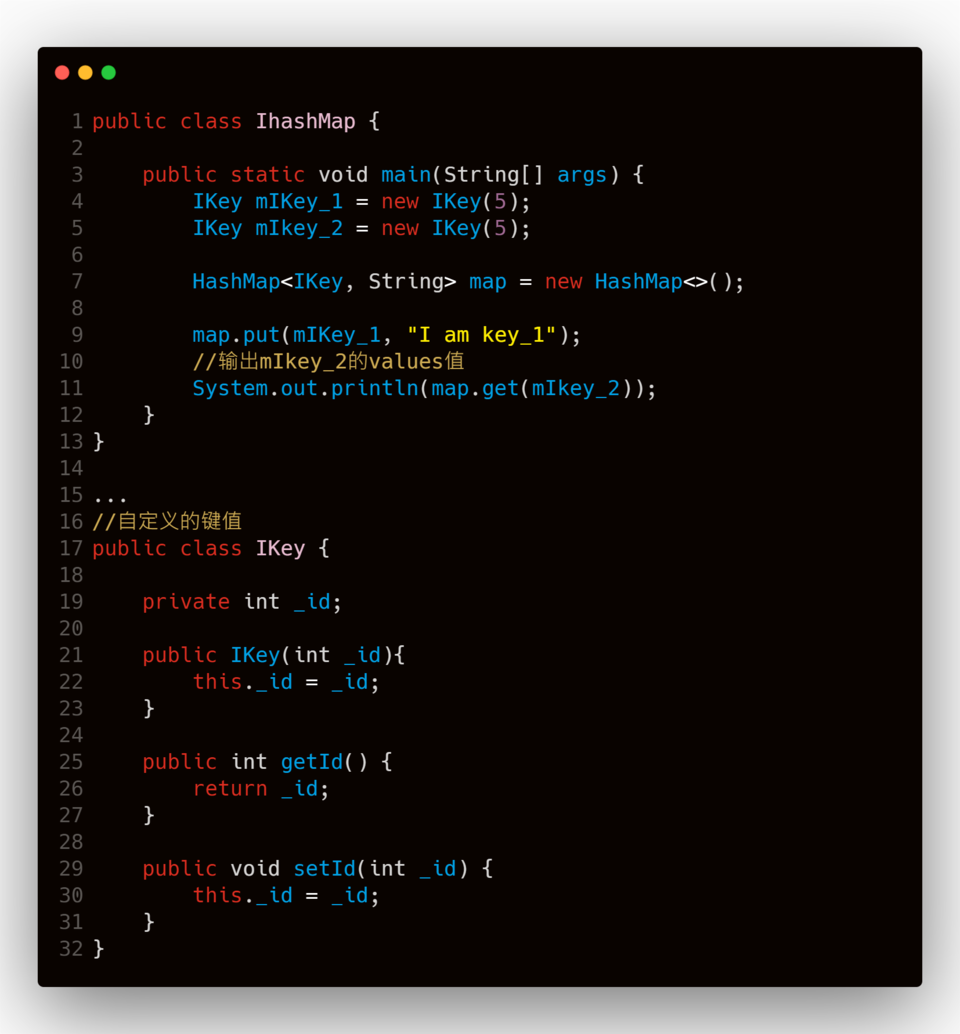
如上面的代码,我们自定义了键值 IKey 类, 类 IKey 很简单,如上图代码 17 行起。并在第 4 和 第 5 行分别创建了 IKey 的对象 mIkey_1 、 mIkey_2 ,并通过 HashMap 的实例调用 put() 函数把 mIkey_1 作为键值传进,然后通过调用 get() 函数打印键值为 mIkey_2 的 Value 值。按照我们的需求,通过调用 get() 函数打印键值为 mIkey_2 的 Value 值应该是 I am Key_1 所对应的键值对的 Value,因为我们传进 Ikey 里面的 id 值同都是 5,那么我们通过 mIkey_2 获取到的 Value 值也应该和传进的 mIkey_1 相同。然而经过控制台打印的结果却截然出乎我们的预料,控制台打印出的为 null ,这是为什么呢?
因为我们在自定义 HashMap 的时候,没有重写 hashcode() 函数,导致我们通过 mIkey_2 键值去获取 mIkey_1 传进的 Value 值的时候,直接调用了 Objct 类里面的 hashcode() 函数,我们知道 Object 类里面的 hashcode() 返回的是关于 IKey 对象实例内存地址(有可能为内存地址的哈希值,不同的 JDK 版本略有不同,这里暂不做考究,感兴趣的读者可自行翻阅 Object 的源码阅读,为了便于理解,我在这篇文章中认为 Object 类里面的 hashcode() 方法返回的是对象的内存地址)。
显然地, IKey 的对象两个实例 mIkey_1 、 mIkey_2 在虚拟机内存中的地址是不同的,那么 HashMap 通过 mIkey_2 去查询 mIkey_1 的 Value 值的时候,因为不存在 mIkey_2 的内存地址的 key 值,于是控制台返回的结果为 null 。
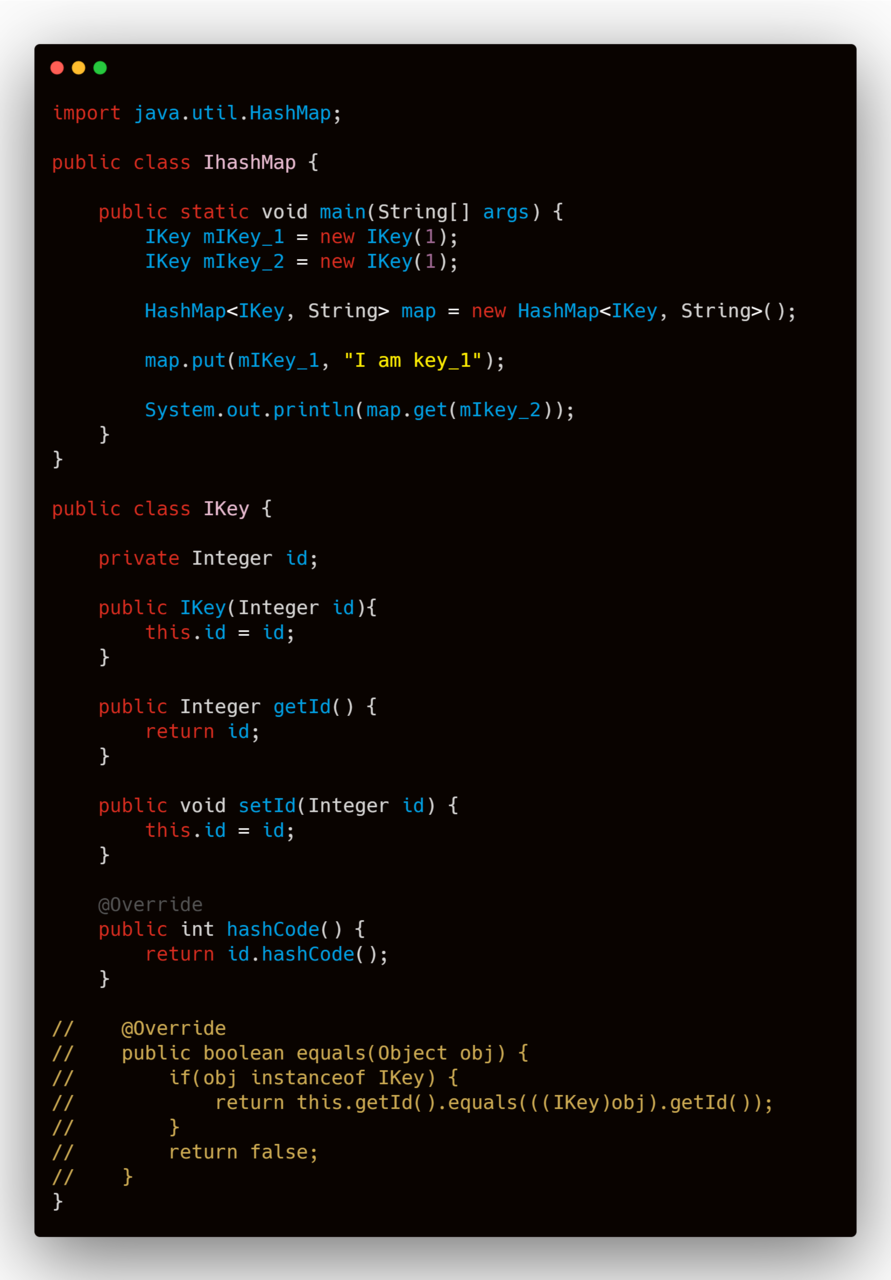
如上图,我们在自定义的键值 IKey 中重写了 hashcode() 方法,但我们此时运行 IhashMap 中的 main 方法,那么这时候控制台打印的会是 "I am key_1" 吗?
答案是否定的,在控制台打印输出的同样是 null 。因为在 HashMap 中调用 get() 函数时,首先会通过 mIkey_2 的哈希值计算出 mIkey_2 在桶数组的位置下标,如果该位置下标的数组元素存在,再次判断该元素的哈希值是否与 mIkey_2 的哈希是否相同。我们前面提到,哈希算法无法做到零冲突。也就是说即使两个不同的 IKey 对象实例也可能存在着相同的哈希值。因此,在前面两个条件都成立的前提下,还需要调用 IKey 的 equals() 方法,判断里面的 id 是否相同。如果 id 的值相同,那么才可以通过 mIkey_2 为键值找到通过 mIkey_1 传进的键值。但是我们没有重写到 equals() 方法,故 HashMap 调用的是 Object 类的 equals() 方法。
我们知道,Object 类中的 equals() 方法比较的是两个对象的内存地址。显然, mIkey_1 和 mIkey_2 的内存地址是不同的,因此我们在重写 hashcode() 方法了,但是没有重写到 equals() 的情况下,通过 mIkey_2 为键值去查询 mIkey_1 的 Value 值,仍然为 null 。
再看上图,当我们把 IKey 中已经注释的 equals() 注释掉,那么我们在控制台得到的结果,就是我们想要的 I am Key_1 。
后言
到了这里,可能你会想问,为什么平常我在 HashMap 中使用 Integer、String 等作为键值的时候,不需要重写 hashcode() 和 equals() 方法呢? 这是因为 Java 工程师已经帮我们重写并且实现好了这两个方法。有兴趣的读者可以自行翻阅它们的源码查看。
正文到此结束
热门推荐










相关文章






Loading...
![[HBLOG]公众号](http://www.liuhaihua.cn/img/qrcode_gzh.jpg)

