浅析Spark Architecture:Shuffle(二)
在 浅析 Spark Architecture:Shuffle(一) | Thinking Realm 这篇文章中我主要向大家介绍了Spark Shuffle的运行原理和随着Spark升级导致Shuffle运行机制的变化。
而这篇文章主要介绍在Spark中哪些操作会触发Shuffle、Shuffle的bypassMergeThreshold运行机制和4个与Shuffle相关的参数。
何时会触发Spark Shuffle操作?
首先,从字面上来理解,Shuffle的意思就是“洗牌”,就是要把原来混乱的数据重新整理,而往往数据又不是分布在同一个地方的,在这个过程中必然会涉及到数据的移动,所以不难理解Shuffle是一个非常消耗资源的操作,通常可以通过数据分区来降低Shuffle带来的网络传输开销。
在Spark中, map 、 filter 、 union 操作不会触发Shuffle操作,因为这些操作都是针对单个数据本身的改变,数据与数据之间并不会发生关联或者交换操作。而诸如分区操作如 repartition 、coalesce 或者 groupByKey 、 sortByKey 等 ByKey 的操作一般会触发Shuffle,groupByKey会对数据做分组处理,而sortByKey需要比较数据与数据之间的先后顺序。
| 类型 | |
|---|---|
| repartition | repartition or coalesce |
| ByKey | groupByKey or sortByKey |
| join |
推荐两个链接:第一个说的是partitionBy和repartition之间的区别,第二个解释在Spark中哪些操作会引发Shuffle。
Spark shuffle – Case #1 – partitionBy and repartition – Tantus Data
mapreduce - When does shuffling occur in Apache Spark? - Stack Overflow
Spark(>1.2.0)Shuffle的bypassMergeThreshold运行机制
从Spark 1.2.0开始,Spark Shuffle默认的算法便变为了sort,可以通过 spark.shuffle.manager 选择相应的Shuffle算法。在上一篇文章中有提到过,Sort Shuffle的原理与Hadoop Shuffle有着相似的实现逻辑,Map端只会输出两个文件,分别是数据文件和记录结果数据的索引文件,由此,Reduce端就很容易根据索引文件找到记录结果的数据文件位置。
值得注意的是,最新版本的Spark在Sort Shuffle机制也并不完全只是Sort Based,在SortShuffleManager下有一个 spark.shuffle.sort.bypassMergeThreshold 参数比较有意思,它主要用于决定当Reduce端的任务不超过Threshold值的时候采用类似Hash Based的Shuffle机制,即直接将Map端的文件先分别写入单独的文件,但是它又跟Hash Based不完全相同,它在最后一步还是会将这些文件合并成为一个单独的文件。
举个例子比较好理解,如果说你要从A城市出发去B城市,现有两种选择:打车和坐火车,打车比较灵活适合中短距离,距离太远则不经济,火车价格低廉适合距离长距离。如果A城市和B城市之间的距离大约50公里以内,那么我建议你还是打车比较合理,毕竟打车比较灵活,可以决定自己的时间。而当距离超过100公里,那现在就有必要考虑坐火车了。
Hash Based Shuffle之于Sort Based Shuffle正如打车和 坐火车的关系,Hash Based适合数据量不是特别大的计算任务,此时它会比Sort Based更快;而数据量很大的情况下,Sort Based就更胜一筹,Hash Based会把大量的Map结果写入内存,会相当耗费资源,给GC造成了巨大的压力,得不偿失。下图描述了bypassMergeThreshold运行机制下SortShuffleManager选择类似Hash Based的Shuffle原理(图片来源: Spark性能优化指南——高级篇 - 美团技术团队 )。
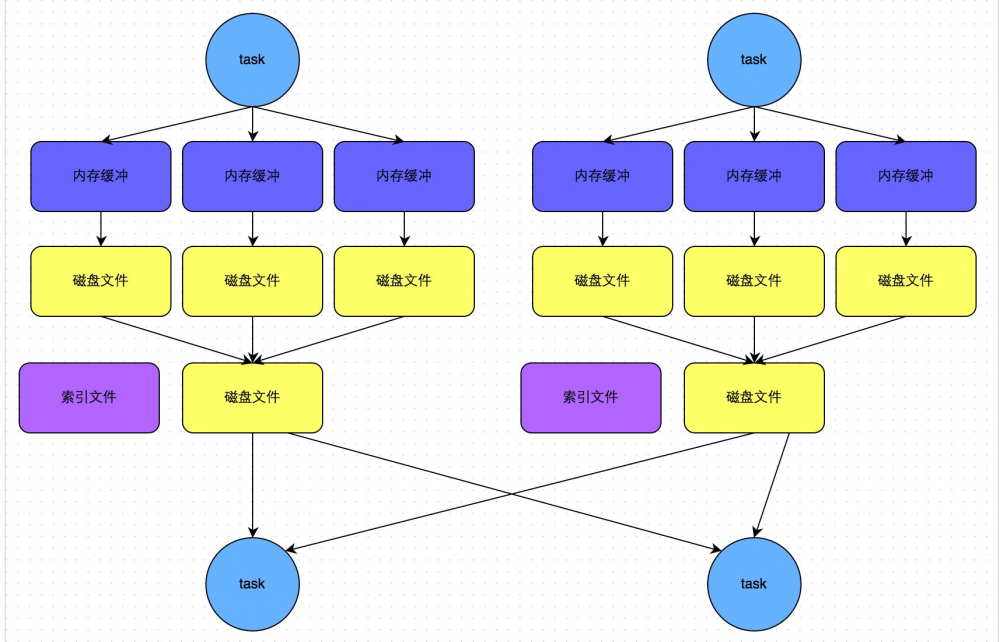
Spark Shuffle的 spark.shuffle.sort.bypassMergeThreshold 参数正是为了兼顾Hash Shuffle在小数据集上的优异表现而设置的, spark.shuffle.sort.bypassMergeThreshold 参数默认为200,当Map端的任务数量 小于200时 ,此时的Shuffle选择的是Hash Shuffle,也就是先将 大量的 中间数据文件 写入内存并且不排序 ,只是在最后每个Map task都会把中间的数据文件再汇总为一个数据文件给Reducer,这样一来大大提高运行的效率。
所以,我这里给出的建议是,如果集群的GC压力比较大,并且处理的是需要进行排序的Shuffle操作比如sortBy,可以适当地减小 bypassMergeThreshold 的值,选择Sort Based Shuffle。
正文到此结束
热门推荐










相关文章

近期评论
-
你这基本没有更新呀,最近文章显示还是2019年的文章。不符合要求哈
-
关键词:慕云博客 链接:https://www.lilun.me 描述:分享原创文字的个人博客
-
-
-
可以提供一下源码吗
-
不是商业站,鸡娃学习笔记
-
-
-
-
听他们说很厉害的样子
Loading...
![[HBLOG]公众号](http://www.liuhaihua.cn/img/qrcode_gzh.jpg)

