图文并茂理解hashMap
阅读此文后你将掌握的知识点:
1, hashMap原理
2, 为什么长度必须是2的整数次幂
3, PUT的数据如何进行存储
4,java1.7的hashMap在高并发下会有什么问题
5,java1.8有哪些改进
注:文中如有理解描述不当的地方请多多指正。
使用的数据结构
数组 链表 红黑树(jdk > 1.7)
以数组为主, 链表 和 红黑树 为辅; 即HashMap底层是一个数组 , 然后数组的每一个元素是一个链表 或者 红黑树(1.8, 当链表长度大于8时, 链表会自动转换成红黑树)
已数组为主的优缺点:
优点:
- 查询插入的时间复杂度为O(1)
缺点:
- 数组占用的空间必须是一块连续的物理空间; 因此当分配的数组空间不够时会引发gc
原理
HashMap基于hashing原理,我们通过put()和get()方法储存和获取对象。
当我们将键值对传递给put()方法时,它调用键对象的hashCode()方法来计算hashcode,让后找到bucket位置来储存值对象。
当获取对象时,通过hash(key)找到存储的位置, 如果此位置存储的是一个链表, 则在使用equals返回对应的值;
HashMap使用链表来解决碰撞问题,当发生碰撞了,对象将会储存在链表的下一个节点中。 HashMap在每个链表节点中储存键值对对象。
当两个不同的键对象的hashcode相同时会发生什么? 它们会储存在同一个bucket位置的链表中。键对象的**equals()**方法用来找到键值对。
Base1.7
put
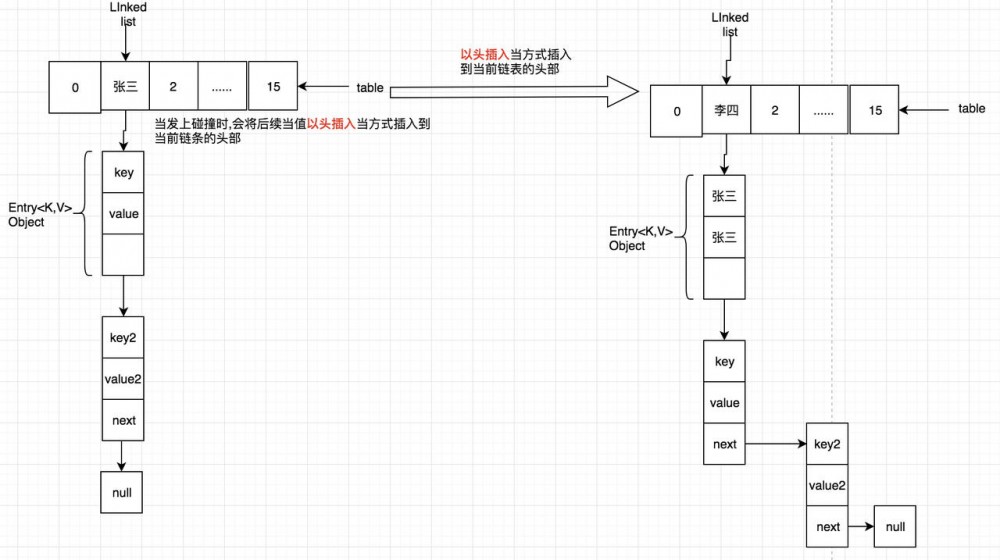
如果table中的某个位置已经是一个链表, 此时在重新插入一个元素, 得到的位置也是此位置,此时直接在头部插入;
存储索引的计算
第一种方式: hash(key) % length (对map长度取模)
第二种方式: hash(key) 进行位运算 == (length - 1) & hash(key)
通过查看查看 indexFor(hash, table.length) , 得到的结论是 第二种 ;
理由:
- 当数据量大的时候 位运算性能 远远高于 取模运算 (取模预算是加减乘除中效率最低的)
public V put(K key, V value) {
// HashMap允许存放null键和null值。
// 当key为null时,调用putForNullKey方法,将value放置在数组第一个位置。
if (key == null)
return putForNullKey(value);
// 根据key的keyCode重新计算hash值。
int hash = hash(key.hashCode());
// 搜索指定hash值在对应table中的索引。
int i = indexFor(hash, table.length);
// 如果 i 索引处的 Entry 不为 null,通过循环不断遍历 e 元素的下一个元素。
for (Entry<K,V> e = table[i]; e != null; e = e.next) {
Object k;
if (e.hash == hash && ((k = e.key) == key || key.equals(k))) {
V oldValue = e.value;
e.value = value;
e.recordAccess(this);
return oldValue;
}
}
// 如果i索引处的Entry为null,表明此处还没有Entry。
modCount++;
// 将key、value添加到i索引处。
addEntry(hash, key, value, i);
return null;
}
void addEntry(int hash, K key, V value, int bucketIndex) {
// 获取指定 bucketIndex 索引处的 Entry
Entry<K,V> e = table[bucketIndex];
// 将新创建的 Entry 放入 bucketIndex 索引处,并让新的 Entry 指向原来的 Entry
table[bucketIndex] = new Entry<K,V>(hash, key, value, e);
// 如果 Map 中的 key-value 对的数量超过了极限
if (size++ >= threshold)
// 把 table 对象的长度扩充到原来的2倍。
resize(2 * table.length);
}
static int indexFor(int h, int length) {
return h & (length-1);
}
复制代码
为什么Map长度总是2的整数次幂
如果在初始化的时候传入的不是2的整数次幂, 在源码实现中会自动进行强转
int capacity = 1;
while (capacity < initialCapacity)
capacity <<= 1;
复制代码
原因:
因为在计算元素存储的位置的时候用的hash(key) & (table.length-1), 所以一定要保证第二个运算数的二进制是后面的数字一定要是连续的数字, 这样才能降低hash碰撞的概率, 数据分布就会相对的均匀,查询的时候效率相对较高 ,
十进制:2 4 8 16 32 -1 = 1 3 7 15 31
二进制:10 100 1000 10000 100000 -1 = 01 011 0111 01111 011111
假设, map长度不是2的整数次幂, 发生的效果假设length=15 , 在计算存储位置的时候
hash(key) & (length-1) = hash(key) &(1110)
这样计算之后, 最后一位永远都是0, 最后导致在存储的时候会有一个位置浪费, 造成hash碰撞概率提高
例子
假设数组长度分别为15和16,优化后的hash码分别为8和9,那么&运算后的结果如下:
h & (table.length-1) hash table.length-1 8 & (15-1): 0100 & 1110 = 0100 9 & (15-1): 0101 & 1110 = 0100 8 & (16-1): 0100 & 1111 = 0100 9 & (16-1): 0101 & 1111 = 0101 复制代码
Table.length-1 = (15-1) = 1110 分别与 8 和 9 的二进制进行 & 操作, 得到的二进制的数最有一位肯定是0;
而0001,0011,0101,1001,1011,0111,1101这几个位置永远都不能存放元素了,空间浪费相当大,更糟的是这种情况中,数组可以使用的位置比数组长度小了很多,这意味着进一步增加了碰撞的几率,减慢了查询的效率;
Table.length-1 = (16-1) = 1111 分别与 8 和 9 的二进制进行 & 操作,得到的数据是不同的;2n-1得到的二进制数的每个位上的值都为1,这使得在低位上&时,得到的和原hash的低位相同,加之hash(int h)方法对key的hashCode的进一步优化,加入了高位计算,就使得只有相同的hash值的两个值才会被放到数组中的同一个位置上形成链表.
负载因子
作用: 负载因子loadFactor衡量的是一个散列表(hashMap)的空间的使用程度 (如果length=8, 当存储的数据达到 8 * 0.75 = 6 时, 开始进行扩容操作), 在 addEntry() 方法中进行判断; 负载因子越大表示散列表的装填程度越高,反之愈小。
resize(2 * table.length); 复制代码
超过后自定进行扩容 长度是原来的2倍; 因为扩容后需要重新对历史数据进行rehash 以及 数据迁移操作, 因此频繁的扩容会造成性能问题;
对于使用链表法的散列表来说,查找一个元素的平均时间是O(1+a),因此如果负载因子越大,对空间的利用更充分,然而后果是查找效率的降低;如果负载因子太小,那么散列表的数据将过于稀疏,对空间造成严重浪费。
因此 就是 以空间换时间 (即浪费一些存储空间换取高速的查询)
get
public V get(Object key) {
if (key == null)
return getForNullKey();
int hash = hash(key.hashCode());
for (Entry<K,V> e = table[indexFor(hash, table.length)];
e != null;
e = e.next) {
Object k;
if (e.hash == hash && ((k = e.key) == key || key.equals(k)))
return e.value;
}
return null;
}
复制代码
首先计算key的hashCode,找到数组中对应位置的某一元素,然后通过key的equals方法在对应位置的链表中找到需要的元素。
高并发下的问题
会造成死锁
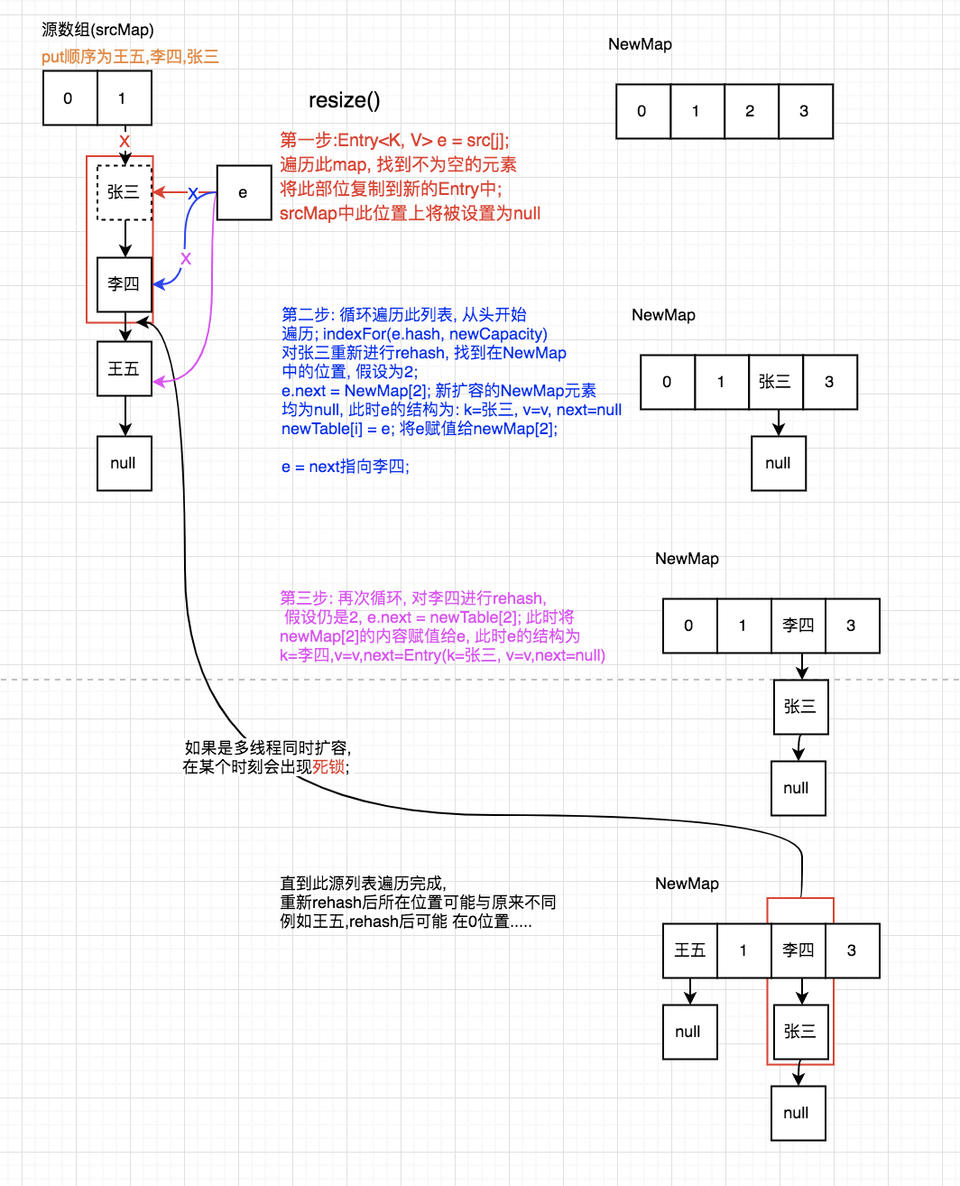
造成死锁的原因:当重新调整HashMap大小的时候,确实存在条件竞争,因为如果两个线程都发现HashMap需要重新调整大小了,它们会同时试着调整大小。在调整大小的过程中,存储在链表中的元素的次序会反过来,因为移动到新的bucket位置的时候,HashMap并不会将元素放在链表的尾部,而是放在头部,这是为了避免尾部遍历(tail traversing)。如果条件竞争发生了,那么就死循环了。
扩容
void resize(int newCapacity) { //传入新的容量
Entry[] oldTable = table; //引用扩容前的Entry数组
int oldCapacity = oldTable.length;
if (oldCapacity == MAXIMUM_CAPACITY) { //扩容前的数组大小如果已经达到最大(2^30)了
threshold = Integer.MAX_VALUE; //修改阈值为int的最大值(2^31-1),这样以后就不会扩容了
return;
}
Entry[] newTable = new Entry[newCapacity]; //初始化一个新的Entry数组
transfer(newTable); //!!将数据转移到新的Entry数组里
table = newTable; //HashMap的table属性引用新的Entry数组
threshold = (int) (newCapacity * loadFactor);//修改阈值
}
void transfer(Entry[] newTable) {
Entry[] src = table; //src引用了旧的Entry数组
int newCapacity = newTable.length;
for (int j = 0; j < src.length; j++) { //遍历旧的Entry数组
Entry<K, V> e = src[j]; //取得旧Entry数组的每个元素
if (e != null) {
src[j] = null;//释放旧Entry数组的对象引用(for循环后,旧的Entry数组不再引用任何对象)
do {
Entry<K, V> next = e.next;
int i = indexFor(e.hash, newCapacity); //!!重新计算每个元素在数组中的位置
/**
在此处就体现出了头部插入;
*/
e.next = newTable[i]; //标记[1]
newTable[i] = e; //将元素放在数组上
e = next; //访问下一个Entry链上的元素
} while (e != null);
}
}
}
static int indexFor(int h, int length) {
return h & (length - 1);
}
复制代码
Base1.8
优化点:
- 增加了 红黑树, 当链表长度>=8时 会默认将链表改成红黑树
- 优化扩容机制 (源Map上链表的值 在扩容的时候不需要rehash, 新的索引 只有两种情况:1,原索引; 3,原索引+ oldMAP.length
- hash 值计算
重要代码段讲解
如何优化了hash值
static final int hash(Object key) {
int h;
/**
h >>> 16 将h的二进制数向右移动16位, 意味着舍弃低16位, 然后将高16位补0
例如 有两个数字 h1 , h2 ; 对应的二进制分别如下
h1 = 1011 0101 0010 1010 0101 1101 1100 1111
h2 = 1010 1001 0101 0101 0101 1101 1100 1111
我们发现这两个数字的hashcode后16位是相同的, 如果直接用次数进行与length-1进行&运算,得到的索引位置必然相同, 这样就会发生hash碰撞;
^ : 相同为0 不同为1
因此在1.8进行了改进 使用下面的方式; 仍用上面的例子
h1 = 1011 0101 0010 1010 0101 1101 1100 1111
h>>>16 = 0000 0000 0000 0000 1011 0101 0010 1010 ^
--------------------------------------------------
h1 1011 0101 0010 1010 1110 1000 1110 0101
h2 = 1010 1001 0101 0101 0101 1101 1100 1111
h>>>16 = 0000 0000 0000 0000 1010 1001 0101 0101 ^
--------------------------------------------------
h2 1010 1001 0101 0101 1111 0100 1001 1010
经过异或运算后,h1 h2的低位不在相等 ,因此在与length-1进行&运算后, 索引的位置将不在相同, 因此降低了ha sh碰撞的概率
*/
return (key == null) ? 0 : (h = key.hashCode()) ^ (h >>> 16);
}
复制代码
Put
final V putVal(int hash, K key, V value, boolean onlyIfAbsent,
boolean evict) {
Node<K,V>[] tab; Node<K,V> p; int n, i;
if ((tab = table) == null || (n = tab.length) == 0)
n = (tab = resize()).length;
if ((p = tab[i = (n - 1) & hash]) == null)
tab[i] = newNode(hash, key, value, null);
else {
Node<K,V> e; K k;
if (p.hash == hash &&
((k = p.key) == key || (key != null && key.equals(k))))
e = p;
else if (p instanceof TreeNode)
e = ((TreeNode<K,V>)p).putTreeVal(this, tab, hash, key, value);
else {
for (int binCount = 0; ; ++binCount) {
if ((e = p.next) == null) {
p.next = newNode(hash, key, value, null);
// TREEIFY_THRESHOLD 默认值 8, 当大于等于时,转换成tree
if (binCount >= TREEIFY_THRESHOLD - 1) // -1 for 1st
treeifyBin(tab, hash);
break;
}
if (e.hash == hash &&
((k = e.key) == key || (key != null && key.equals(k))))
break;
p = e;
}
}
if (e != null) { // existing mapping for key
V oldValue = e.value;
if (!onlyIfAbsent || oldValue == null)
e.value = value;
afterNodeAccess(e);
return oldValue;
}
}
++modCount;
// 与1.7相比 条件进行了简化
if (++size > threshold)
resize();
afterNodeInsertion(evict);
return null;
}
复制代码
resize
final Node<K,V>[] resize() {
Node<K,V>[] oldTab = table;
int oldCap = (oldTab == null) ? 0 : oldTab.length;
int oldThr = threshold;
int newCap, newThr = 0;
if (oldCap > 0) {
if (oldCap >= MAXIMUM_CAPACITY) {
threshold = Integer.MAX_VALUE;
return oldTab;
}
else if ((newCap = oldCap << 1) < MAXIMUM_CAPACITY &&
oldCap >= DEFAULT_INITIAL_CAPACITY)
newThr = oldThr << 1; // double threshold
}
else if (oldThr > 0) // initial capacity was placed in threshold
newCap = oldThr;
else { // zero initial threshold signifies using defaults
newCap = DEFAULT_INITIAL_CAPACITY;
newThr = (int)(DEFAULT_LOAD_FACTOR * DEFAULT_INITIAL_CAPACITY);
}
if (newThr == 0) {
float ft = (float)newCap * loadFactor;
newThr = (newCap < MAXIMUM_CAPACITY && ft < (float)MAXIMUM_CAPACITY ?
(int)ft : Integer.MAX_VALUE);
}
threshold = newThr;
@SuppressWarnings({"rawtypes","unchecked"})
Node<K,V>[] newTab = (Node<K,V>[])new Node[newCap];
table = newTab;
if (oldTab != null) {
for (int j = 0; j < oldCap; ++j) {
Node<K,V> e;
if ((e = oldTab[j]) != null) {
oldTab[j] = null;
if (e.next == null)
newTab[e.hash & (newCap - 1)] = e;
else if (e instanceof TreeNode)
((TreeNode<K,V>)e).split(this, newTab, j, oldCap);
else { // preserve order
Node<K,V> loHead = null, loTail = null;
Node<K,V> hiHead = null, hiTail = null;
Node<K,V> next;
do {
next = e.next;
/**
& 运算: 同1为1 ,否则为0
oldCap == tabel.length 一定是2的整数次幂, 因此二进制数一定是1开头,后面全部都是0,
因此在使用e.hash & oldCap的时候肯定只有两种结果, 一种是0 一种非0
例如:
已上面hash()为例子h2 为例, length=16
h2 = 1010 1001 0101 0101 1111 0100 1001 1010
length = 0000 0000 0000 0000 0000 0000 0001 0000 &
---------------------------------------------------
0000 0000 0000 0000 0000 0000 0001 0000
因此h2此数据在map进行扩容会进入到hiTail; 因此索引的位置为j+oldCap
*/
if ((e.hash & oldCap) == 0) {
if (loTail == null)
loHead = e;
else
loTail.next = e;
loTail = e;
}
else {
if (hiTail == null)
hiHead = e;
else
hiTail.next = e;
hiTail = e;
}
} while ((e = next) != null);
if (loTail != null) {
loTail.next = null;
newTab[j] = loHead;
}
if (hiTail != null) {
hiTail.next = null;
newTab[j + oldCap] = hiHead;
}
}
}
}
}
return newTab;
}
复制代码
HashMap不是线程安全的, 如果在多线程下请使用concurrentHashMap
参考资料:
www.jianshu.com/p/eacb686a3…
crossoverjie.top/2018/07/23/… (包含一些面试常见问题)
blog.csdn.net/qq_41097354… (包含一些面试常见问题)
正文到此结束
热门推荐










相关文章

近期评论
-
你这基本没有更新呀,最近文章显示还是2019年的文章。不符合要求哈
-
关键词:慕云博客 链接:https://www.lilun.me 描述:分享原创文字的个人博客
-
-
-
可以提供一下源码吗
-
不是商业站,鸡娃学习笔记
-
-
-
-
听他们说很厉害的样子
Loading...
![[HBLOG]公众号](http://www.liuhaihua.cn/img/qrcode_gzh.jpg)

