JDK源码那些事儿之ConcurrentLinkedDeque
非阻塞队列ConcurrentLinkedQueue我们已经了解过了,既然是Queue,那么是否有其双端队列实现呢?答案是肯定的,今天就继续说一说非阻塞双端队列实现ConcurrentLinkedDeque
前言
JDK版本号:1.8.0_171
ConcurrentLinkedDeque是一个基于链表实现的无界的线程安全的同时支持FIFO、LIFO非阻塞双端队列。操作上可类比ConcurrentLinkedQueue,利用CAS进行无锁操作,同时通过松弛度阈值设置来减少CAS操作,在理解这个类前可先去参考理解我之前对ConcurrentLinkedQueue的源码分析
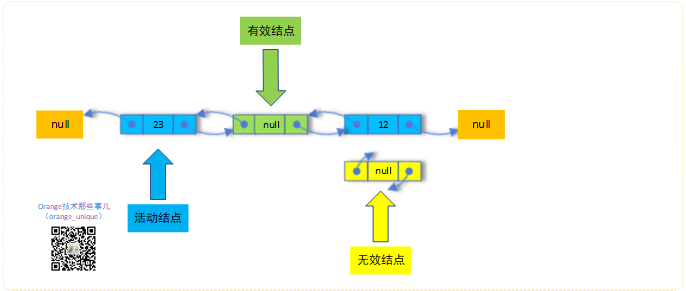
为了说明的方便,我们区分下,活动结点是item非null的结点,有效结点是保持着前后关系的结点,作者在注释中解释了将一个结点删除分为3个步骤:
- logical deletion:逻辑删除,item置为null,前后结点关联关系依旧保持,此时不为活动结点,为有效结点
- unlinking:有效结点可以通过前驱和后继指针到达其他活动节点,但是活动节点不可到达有效结点,保证迭代器的正常,并最终可被GC回收
- gc-unlinking:有效结点完全孤立,为无效结点,不可到达其他任何活动结点,其他结点也不可到达此结点
区分定义是便于源码分析时的说明,参考下图所示理解:
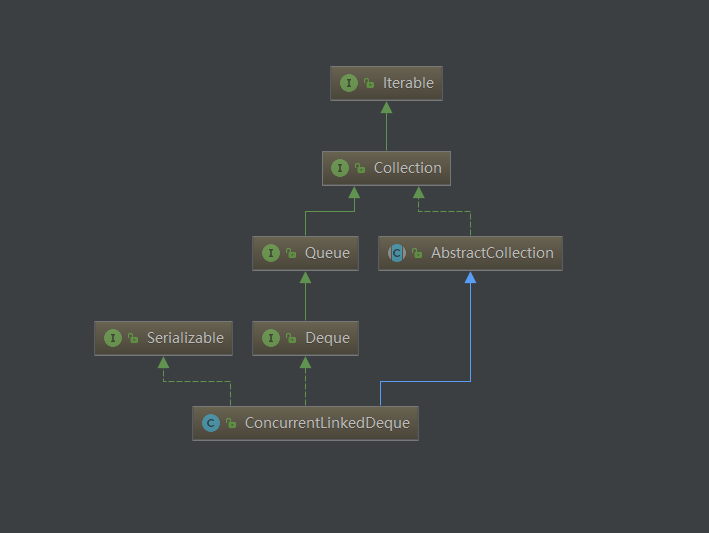
类定义
public class ConcurrentLinkedDeque<E>
extends AbstractCollection<E>
implements Deque<E>, java.io.Serializable
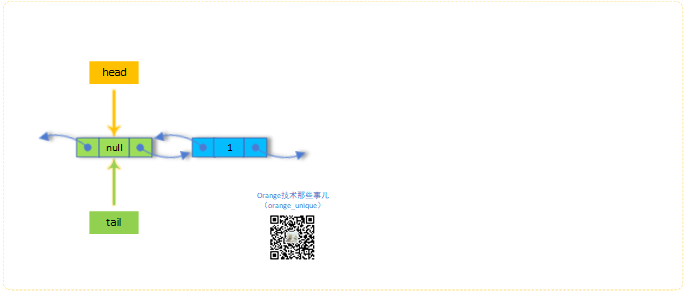
实现流程
为了方便理解,这里将ConcurrentLinkedDeque操作过程进行图示,让各位先有个了解,便于后面源码的分析
1.new实例化操作

2.offer("1")
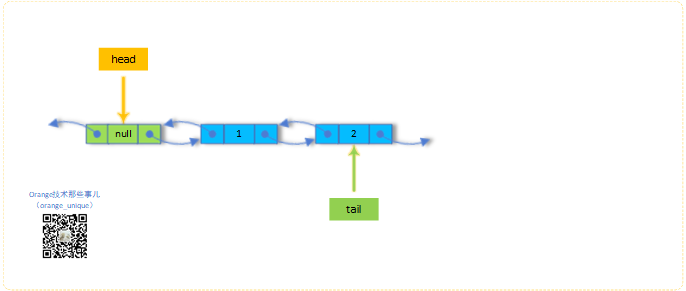
3.offer("2")
4.offerFirst("3")
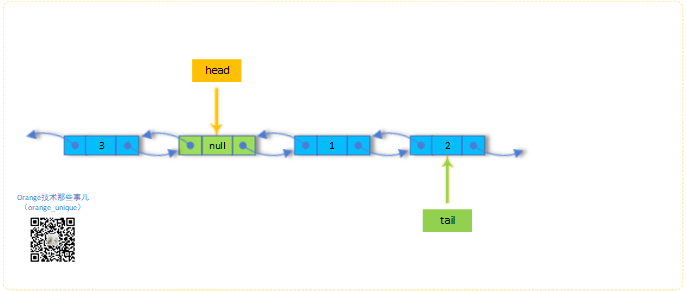
5.offerFirst("4")
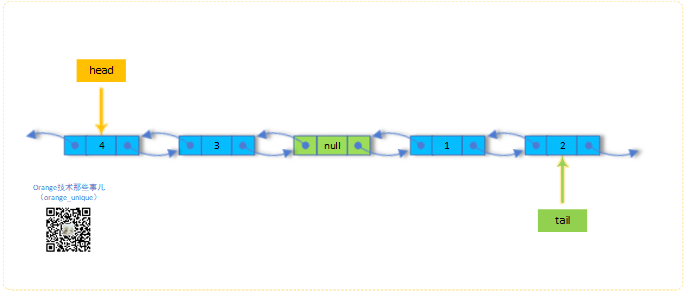
6.pollLast
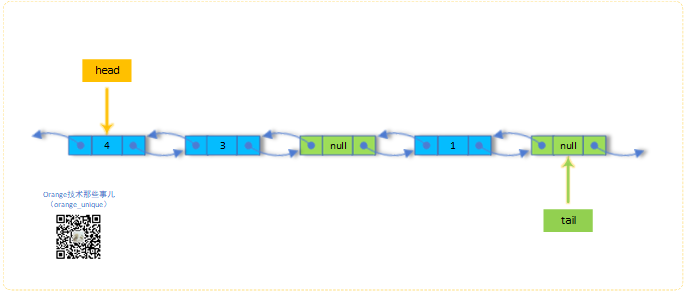
7.poll

8.poll
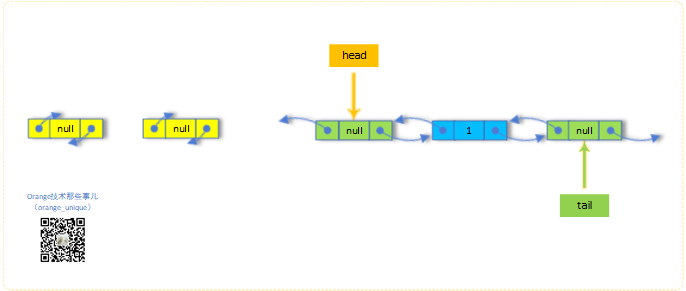
9.pollLast
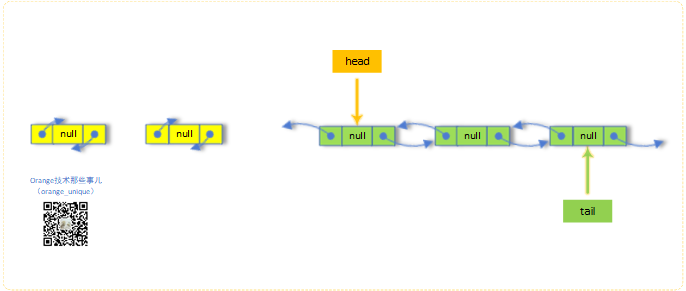
常量/变量
head结点(p.prev == null && p.next != p):
- first结点可以从head结点通过prev获取得到,时间复杂度O(1)
- 所有活动结点(item != null)都可以从first结点通过succ获取得到
- head结点非null
- head结点的next不会指向自己
- head结点不可能处于gc-unlinking阶段,但是有可能处于unlinking阶段
- head结点的item可能为空也可能不为空
- head结点可能不能从first或者last或者tail结点获取得到
tail结点(p.next == null && p.prev != p):
- last结点可以从tail结点通过next获取得到,时间复杂度O(1)
- 所有活动结点(item != null)都可以从last结点通过pred获取得到
- tail结点非null
- tail结点不可能处于gc-unlinking阶段,但是有可能处于unlinking阶段
- tail结点的item可能为空也可能不为空
- tail结点可能不能从first或者last或者head结点获取得到
由于head结点和tail结点不是实时更新(同ConcurrentLinkedQueue),达到松弛度阈值才进行更新,减少CAS操作,有可能导致head结点在tail结点之后的现象
/**
* A node from which the first node on list (that is, the unique node p
* with p.prev == null && p.next != p) can be reached in O(1) time.
* Invariants:
* - the first node is always O(1) reachable from head via prev links
* - all live nodes are reachable from the first node via succ()
* - head != null
* - (tmp = head).next != tmp || tmp != head
* - head is never gc-unlinked (but may be unlinked)
* Non-invariants:
* - head.item may or may not be null
* - head may not be reachable from the first or last node, or from tail
*/
private transient volatile Node<E> head;
/**
* A node from which the last node on list (that is, the unique node p
* with p.next == null && p.prev != p) can be reached in O(1) time.
* Invariants:
* - the last node is always O(1) reachable from tail via next links
* - all live nodes are reachable from the last node via pred()
* - tail != null
* - tail is never gc-unlinked (but may be unlinked)
* Non-invariants:
* - tail.item may or may not be null
* - tail may not be reachable from the first or last node, or from head
*/
private transient volatile Node<E> tail;
// 终止结点,在gc-unlinking阶段将无用结点链接到这两个结点上,自行处理减少内内存滞留风险
private static final Node<Object> PREV_TERMINATOR, NEXT_TERMINATOR;
// 删除结点执行unlinking/gc-unlinking的阈值,当逻辑删除结点达到阈值才触发,算是性能优化
private static final int HOPS = 2;
// CAS
private static final sun.misc.Unsafe UNSAFE;
private static final long headOffset;
private static final long tailOffset;
static {
PREV_TERMINATOR = new Node<Object>();
PREV_TERMINATOR.next = PREV_TERMINATOR;
NEXT_TERMINATOR = new Node<Object>();
NEXT_TERMINATOR.prev = NEXT_TERMINATOR;
try {
UNSAFE = sun.misc.Unsafe.getUnsafe();
Class<?> k = ConcurrentLinkedDeque.class;
headOffset = UNSAFE.objectFieldOffset
(k.getDeclaredField("head"));
tailOffset = UNSAFE.objectFieldOffset
(k.getDeclaredField("tail"));
} catch (Exception e) {
throw new Error(e);
}
}
内部类
Node实现与ConcurrentLinkedQueue不同之处也就在于多了变量prev指向结点的前驱
static final class Node<E> {
volatile Node<E> prev;
volatile E item;
volatile Node<E> next;
Node() { // default constructor for NEXT_TERMINATOR, PREV_TERMINATOR
}
/**
* Constructs a new node. Uses relaxed write because item can
* only be seen after publication via casNext or casPrev.
*/
Node(E item) {
UNSAFE.putObject(this, itemOffset, item);
}
boolean casItem(E cmp, E val) {
return UNSAFE.compareAndSwapObject(this, itemOffset, cmp, val);
}
void lazySetNext(Node<E> val) {
UNSAFE.putOrderedObject(this, nextOffset, val);
}
boolean casNext(Node<E> cmp, Node<E> val) {
return UNSAFE.compareAndSwapObject(this, nextOffset, cmp, val);
}
void lazySetPrev(Node<E> val) {
UNSAFE.putOrderedObject(this, prevOffset, val);
}
boolean casPrev(Node<E> cmp, Node<E> val) {
return UNSAFE.compareAndSwapObject(this, prevOffset, cmp, val);
}
// Unsafe mechanics
private static final sun.misc.Unsafe UNSAFE;
private static final long prevOffset;
private static final long itemOffset;
private static final long nextOffset;
static {
try {
UNSAFE = sun.misc.Unsafe.getUnsafe();
Class<?> k = Node.class;
prevOffset = UNSAFE.objectFieldOffset
(k.getDeclaredField("prev"));
itemOffset = UNSAFE.objectFieldOffset
(k.getDeclaredField("item"));
nextOffset = UNSAFE.objectFieldOffset
(k.getDeclaredField("next"));
} catch (Exception e) {
throw new Error(e);
}
}
}
构造方法
无参构造方法创建了空结点同时头尾结点指向这个空结点,集合参数构造时先将所有集合结点构成链表,最后通过initHeadTail更新链表head,tail即可
public ConcurrentLinkedDeque() {
head = tail = new Node<E>(null);
}
public ConcurrentLinkedDeque(Collection<? extends E> c) {
// Copy c into a private chain of Nodes
Node<E> h = null, t = null;
for (E e : c) {
checkNotNull(e);
Node<E> newNode = new Node<E>(e);
if (h == null)
h = t = newNode;
else {
t.lazySetNext(newNode);
newNode.lazySetPrev(t);
t = newNode;
}
}
initHeadTail(h, t);
}
/**
* Initializes head and tail, ensuring invariants hold.
*/
private void initHeadTail(Node<E> h, Node<E> t) {
if (h == t) {
if (h == null)
h = t = new Node<E>(null);
else {
// Avoid edge case of a single Node with non-null item.
Node<E> newNode = new Node<E>(null);
t.lazySetNext(newNode);
newNode.lazySetPrev(t);
t = newNode;
}
}
head = h;
tail = t;
}
重要方法
linkFirst/linkLast
被addFirst和offerFirst所使用,将元素e添加到队列头部,即从头部入队操作。linkLast被addLast和offerLast所使用,offer,add同样最终调用此方法完成操作,将元素e添加到队列尾部,即从尾部入队操作,没什么好说的,类比linkFirst源码理解
private void linkFirst(E e) {
checkNotNull(e);
final Node<E> newNode = new Node<E>(e);
restartFromHead:
for (;;)
for (Node<E> h = head, p = h, q;;) {
// 前驱节点不为null,前驱的前驱节点不为null
if ((q = p.prev) != null &&
(q = (p = q).prev) != null)
// head应该被更新了(已经超过了松弛度阈值)判断是否已经更新了则p更新为head
// 未更新则直接更新为前驱的前驱结点
p = (h != (h = head)) ? h : q;
// p已经出队,没办法从p再继续判断了,无法到达其他结点,需要重新开始循环
else if (p.next == p) // PREV_TERMINATOR
continue restartFromHead;
else {
// p为第一个结点,更新新结点next指向p
newNode.lazySetNext(p); // CAS piggyback
// 尝试更新p的前驱指向新结点,更新失败则重新循环更新
if (p.casPrev(null, newNode)) {
// Successful CAS is the linearization point
// for e to become an element of this deque,
// and for newNode to become "live".
// 新结点入队成功,头结点已经更新了(此时的新结点距离h已经 >= 2个结点距离),尝试更新head
if (p != h) // hop two nodes at a time
casHead(h, newNode); // Failure is OK.
return;
}
// Lost CAS race to another thread; re-read prev
}
}
}
unlink
被pollFirst,pollLast,removeFirstOccurrence,removeLastOccurrence和迭代器的remove所使用,移除非空结点,出队操作和删除时使用,主要处理处于队列中间的结点
void unlink(Node<E> x) {
// assert x != null;
// assert x.item == null;
// assert x != PREV_TERMINATOR;
// assert x != NEXT_TERMINATOR;
final Node<E> prev = x.prev;
final Node<E> next = x.next;
// 前驱为null表示x为头结点
if (prev == null) {
unlinkFirst(x, next);
// 后继为null表示x为尾结点
} else if (next == null) {
unlinkLast(x, prev);
// 非头尾结点表示x处于中间位置需要特殊处理
} else {
Node<E> activePred, activeSucc;
boolean isFirst, isLast;
// 记录逻辑删除结点数
int hops = 1;
// Find active predecessor
// 找到有效的前驱结点
for (Node<E> p = prev; ; ++hops) {
// 有效前驱结点设置
if (p.item != null) {
activePred = p;
isFirst = false;
break;
}
Node<E> q = p.prev;
// p是第一个结点
if (q == null) {
// p已经出队
if (p.next == p)
return;
// p的item为null,next还未更新,变量设置
activePred = p;
isFirst = true;
break;
}
// p == p.prev表示p已经出队
else if (p == q)
return;
// 继续循环向前查找
else
p = q;
}
// Find active successor
// 找到有效的后继结点
for (Node<E> p = next; ; ++hops) {
// 有效后继结点设置
if (p.item != null) {
activeSucc = p;
isLast = false;
break;
}
Node<E> q = p.next;
// p是最后一个结点
if (q == null) {
// p已经出队
if (p.prev == p)
return;
// p的item为null,prev还未更新,变量设置
activeSucc = p;
isLast = true;
break;
}
// p == p.next表示p已经出队
else if (p == q)
return;
// 继续循环向后查找
else
p = q;
}
// TODO: better HOP heuristics
// 达到逻辑删除结点阈值或者是内部删除结点则需要进行额外处理unlink/gc-unlink
if (hops < HOPS
// always squeeze out interior deleted nodes
&& (isFirst | isLast))
return;
// Squeeze out deleted nodes between activePred and
// activeSucc, including x.
// 移除有效前驱和后继结点之间的有效结点,包括x,使得前驱和后继互连
skipDeletedSuccessors(activePred);
skipDeletedPredecessors(activeSucc);
// Try to gc-unlink, if possible
// 有效前驱和后继是队头或队尾,尝试gc-unlink
if ((isFirst | isLast) &&
// Recheck expected state of predecessor and successor
// 检查前驱后继状态,确保未改变
(activePred.next == activeSucc) &&
(activeSucc.prev == activePred) &&
(isFirst ? activePred.prev == null : activePred.item != null) &&
(isLast ? activeSucc.next == null : activeSucc.item != null)) {
// 更新head和tail 确保x不可达
updateHead(); // Ensure x is not reachable from head
updateTail(); // Ensure x is not reachable from tail
// Finally, actually gc-unlink
// 最后更新x,使得从x到活动节点不可达
x.lazySetPrev(isFirst ? prevTerminator() : x);
x.lazySetNext(isLast ? nextTerminator() : x);
}
}
}
unlinkFirst/unlinkLast
unlink中调用,从队列头将第一个非空结点出队。unlinkLast从队列尾将第一个非空结点出队,代码实现与unlinkFirst类似,可参考理解
private void unlinkFirst(Node<E> first, Node<E> next) {
// assert first != null;
// assert next != null;
// assert first.item == null;
for (Node<E> o = null, p = next, q;;) {
// p为活动节点或p为最后一个节点
if (p.item != null || (q = p.next) == null) {
// 如果第一次循环就执行到此则不需要进行操作直接返回,p本来就是first的后继
// p的前驱不能指向自己,first的后继更新成p
if (o != null && p.prev != p && first.casNext(next, p)) {
// unlink阶段
skipDeletedPredecessors(p);
// 检查first和p,确保没被更新修改才进行gc-unlink操作
if (first.prev == null &&
(p.next == null || p.item != null) &&
p.prev == first) {
updateHead(); // Ensure o is not reachable from head
updateTail(); // Ensure o is not reachable from tail
// Finally, actually gc-unlink
o.lazySetNext(o);
o.lazySetPrev(prevTerminator());
}
}
return;
}
// p == p.next
// p非活动结点同时p后继已经指向自己则直接返回
else if (p == q)
return;
// p非活动结点,p还有后继结点,重新赋值循环处理,注意这里o才被赋值
else {
o = p;
p = q;
}
}
}
updateHead/updateTail
更新head结点,确保在调用此方法之前unlinked的任何结点在该方法返回之后都不能从head访问,不保证消除松弛度,仅仅是head将指向处于活动状态的结点。updateTail更新tail结点,同updateHead,基本操作一致,只是方向不同而已
private final void updateHead() {
// Either head already points to an active node, or we keep
// trying to cas it to the first node until it does.
// head要么指向一个活动结点要么尝试指向第一个结点直到成功
Node<E> h, p, q;
restartFromHead:
// head指向非活动结点同时head非第一个结点
while ((h = head).item == null && (p = h.prev) != null) {
for (;;) {
// head前驱的前驱为空或head前驱的前驱的前驱为空
// 即head前有1个或2个结点
if ((q = p.prev) == null ||
(q = (p = q).prev) == null) {
// It is possible that p is PREV_TERMINATOR,
// but if so, the CAS is guaranteed to fail.
// 将head更新指向为第一个结点
if (casHead(h, p))
return;
else
// 未成功更新说明已经被其他线程更新了,重新循环判断
continue restartFromHead;
}
// h前有超过2个的结点,表明当前h指向的结点已经与第一个结点距离超过2,同时h已经不指向head了,重新循环
else if (h != head)
continue restartFromHead;
// h前有超过2个的结点,同时h还指向head,则更新p为q再次判断,相当于p向前跳了1或2个结点位置
else
p = q;
}
}
}
skipDeletedPredecessors/skipDeletedSuccessors
这里有个java语法需要注意:continue lable和break lable的作用,可下列参考代码理解:
System.out.println("continue lable start ");
aaa:
for (int i = 0; i < 3; i++) {
for (int j = 0; j < 3; j++) {
System.out.println(j);
if(j == 1){
continue aaa;
}
}
}
System.out.println("continue lable end ");
System.out.println("break lable start ");
bbb:
for (int i = 0; i < 3; i++) {
for (int j = 0; j < 3; j++) {
System.out.println(j);
if(j == 1){
break bbb;
}
}
}
System.out.println("break lable end ");
skipDeletedPredecessors实现将刚刚找到的后继结点的前驱指向结点p,即完成它们的互联,这一步就是所谓的unlinking,使队列的活动结点无法访问被删除的结点。skipDeletedSuccessors代码逻辑同skipDeletedPredecessors,可参考理解
private void skipDeletedPredecessors(Node<E> x) {
whileActive:
do {
Node<E> prev = x.prev;
// assert prev != null;
// assert x != NEXT_TERMINATOR;
// assert x != PREV_TERMINATOR;
Node<E> p = prev;
findActive:
for (;;) {
// p的item非空,说明p为活动结点,退出循环进行关联更新操作
if (p.item != null)
break findActive;
// p的item为空,再继续向前查找其前驱
Node<E> q = p.prev;
// p的前驱结点为空
// 若p结点处于gc-unlinking状态,即通过p已经无法到达其他活动结点,则需重头开始继续循环判断
// 上面条件不满足,则表示p结点处于unlinking状态,还可以到达其他活动结点,可以继续被使用
// 表明找到了有效结点,退出循环
if (q == null) {
if (p.next == p)
continue whileActive;
break findActive;
}
// p的前驱结点非空,p.prev == p
// 相等则表明p已经此刻的p结点处于gc-unlinking状态,即通过p已经无法到达其他有效结点
// 无法再向前遍历,只能重头开始循环判断
else if (p == q)
continue whileActive;
// 到此表示p的item为空,p的前驱非空且不处于gc-unlinking状态
// 循环向前继续判断前驱结点
else
p = q;
}
// found active CAS target
// 找到活动或有效的前驱节点,前驱CAS更新成功返回否则继续循环判断更新
if (prev == p || x.casPrev(prev, p))
return;
} while (x.item != null || x.next == null);
}
succ/pred
找到结点的前驱或者后继,假如当前结点已经无效结点时,则返回第一个结点或最后一个结点
/**
* Returns the successor of p, or the first node if p.next has been
* linked to self, which will only be true if traversing with a
* stale pointer that is now off the list.
*/
final Node<E> succ(Node<E> p) {
// TODO: should we skip deleted nodes here?
Node<E> q = p.next;
return (p == q) ? first() : q;
}
/**
* Returns the predecessor of p, or the last node if p.prev has been
* linked to self, which will only be true if traversing with a
* stale pointer that is now off the list.
*/
final Node<E> pred(Node<E> p) {
Node<E> q = p.prev;
return (p == q) ? last() : q;
}
first/last
返回第一个结点,有可能是逻辑删除结点,last操作类似
/**
* Returns the first node, the unique node p for which:
* p.prev == null && p.next != p
* The returned node may or may not be logically deleted.
* Guarantees that head is set to the returned node.
*/
Node<E> first() {
restartFromHead:
for (;;)
for (Node<E> h = head, p = h, q;;) {
// p的前驱和前驱的前驱都非空
// 表示p结点之前有2个以上的活动结点
if ((q = p.prev) != null &&
(q = (p = q).prev) != null)
// Check for head updates every other hop.
// If p == q, we are sure to follow head instead.
// 可能head已经被更新了则判断下更新h同时更新p
// 或者head还未更新则直接将p指向q
p = (h != (h = head)) ? h : q;
// p的前驱为空或者前驱的前驱为空
// p == h 表明p的前驱为空(第一个条件里判断),p就是第一个结点
// p == h 不满足则p的前驱非空,前驱的前驱为空,则p的前驱为第一个结点,此时尝试更新head并返回第一个结点
else if (p == h
// It is possible that p is PREV_TERMINATOR,
// but if so, the CAS is guaranteed to fail.
|| casHead(h, p))
return p;
// 第二个条件中尝试更新head失败,则说明其他线程更新了head,重新开始循环处理
else
continue restartFromHead;
}
}
peekFirst/peekLast
通过first()/last()方法返回第一个或最后一个结点的值
public E peekFirst() {
for (Node<E> p = first(); p != null; p = succ(p)) {
E item = p.item;
if (item != null)
return item;
}
return null;
}
public E peekLast() {
for (Node<E> p = last(); p != null; p = pred(p)) {
E item = p.item;
if (item != null)
return item;
}
return null;
}
pollFirst/pollLast
removeFirst/removeLast同pollFirst/pollLast操作,最终调用unlink,可参考上面源码分析
public E pollFirst() {
for (Node<E> p = first(); p != null; p = succ(p)) {
E item = p.item;
if (item != null && p.casItem(item, null)) {
unlink(p);
return item;
}
}
return null;
}
public E pollLast() {
for (Node<E> p = last(); p != null; p = pred(p)) {
E item = p.item;
if (item != null && p.casItem(item, null)) {
unlink(p);
return item;
}
}
return null;
}
其他操作都是基于上面的方法进行实现的,就不再一一列举了,可自行参考源码理解
迭代器
迭代器和之前队列讲解的迭代器ConcurrentLinkedQueue类似,不过由于其双向链表的实现,迭代器可分为升序迭代器(Itr)和倒序迭代器(DescendingItr),通过AbstractItr封装公共操作方法,Itr和DescendingItr分别实现对应不同的方法,一个从头节点开始向后进行遍历,一个从尾节点向后进行遍历,这部分和之前讲解过的LinkedBlockingDeque是类似的
public Iterator<E> iterator() {
return new Itr();
}
public Iterator<E> descendingIterator() {
return new DescendingItr();
}
主要区别方法在于两个,通过这两个方法来完成不同方向的遍历
private class Itr extends AbstractItr {
Node<E> startNode() { return first(); }
Node<E> nextNode(Node<E> p) { return succ(p); }
}
/** Descending iterator */
private class DescendingItr extends AbstractItr {
Node<E> startNode() { return last(); }
Node<E> nextNode(Node<E> p) { return pred(p); }
}
抽象类AbstractItr涉及到的方法比较简单,用到了前面所讲解过的方法,可参考之前的分析
private abstract class AbstractItr implements Iterator<E> {
/**
* Next node to return item for.
*/
private Node<E> nextNode;
/**
* nextItem holds on to item fields because once we claim
* that an element exists in hasNext(), we must return it in
* the following next() call even if it was in the process of
* being removed when hasNext() was called.
*/
private E nextItem;
/**
* Node returned by most recent call to next. Needed by remove.
* Reset to null if this element is deleted by a call to remove.
*/
private Node<E> lastRet;
abstract Node<E> startNode();
abstract Node<E> nextNode(Node<E> p);
AbstractItr() {
advance();
}
/**
* Sets nextNode and nextItem to next valid node, or to null
* if no such.
*/
private void advance() {
lastRet = nextNode;
Node<E> p = (nextNode == null) ? startNode() : nextNode(nextNode);
for (;; p = nextNode(p)) {
if (p == null) {
// p might be active end or TERMINATOR node; both are OK
nextNode = null;
nextItem = null;
break;
}
E item = p.item;
if (item != null) {
nextNode = p;
nextItem = item;
break;
}
}
}
public boolean hasNext() {
return nextItem != null;
}
public E next() {
E item = nextItem;
if (item == null) throw new NoSuchElementException();
advance();
return item;
}
public void remove() {
Node<E> l = lastRet;
if (l == null) throw new IllegalStateException();
l.item = null;
unlink(l);
lastRet = null;
}
}
高性能队列-Disruptor
至此,队列部分已基本分析完毕,除了jdk本身的队列,还有一些比较有名的队列实现,比如Disruptor,可以参考美团的这篇文章进行一些深入了解,对于队列进行了一些底层的分析总结,比较有帮助
https://tech.meituan.com/2016...
总结
源码已经分析完毕,我们以pollFirst出队操作为例进行一个总结说明:
- 通过first()获取到队列头部的第一个结点
- 如果为活动结点(item非空),则将活动结点item置空,即执行logical deletion(逻辑删除)操作
- 继续执行unlinking阶段
- 继续执行gc-unlinking阶段
在unlinking阶段根据结点位置进行不同情况的处理:
1.如果出队的结点是队列的第一个结点p,则执行unlinkFirst,其过程如下:
- 找到p之后的第一个有效结点,直到最后一个结点为止,p的后继结点指向这个找到的结点
- skipDeletedPredecessors完成unlinking阶段,使队列的活动结点无法访问被删除的结点
- 进行gc-unlinking阶段,通过updateHead、updateTail使被删除的结点无法从head/tail可达,最后让被删除结点后继指向自己,前驱指向终结结点
2.如果出队的结点是队列的最后一个结点p,则执行unlinkLast,其过程与第1种情况类似,只是方向不同
3.如果出队的结点时队列的中间位置,则执行unlink中的一个分支代码:
- 先找到删除结点x的有效前驱和有效后继,统计中间已经处于逻辑删除的结点个数
- 如果统计个数已经超过阈值个数或者是内部结点删除,有效前驱和后继互连,即活动结点不能访问逻辑删除结点了(unlinking阶段)
- 有效前驱和后继是队头或队尾,尝试进行gc-unlink,通过updateHead、updateTail使被删除的结点无法从head/tail可达,最后让被删除结点指向自己或者执行终结结点
整体处理流程已经分析完毕,其他操作相对来说比较简单了,需要多理解
ConcurrentLinkedDeque是ConcurrentLinkedQueue的双端队列实现,在删除中涉及到了3个阶段,并且由于其无锁CAS操作和减少CAS次数的操作,导致其实现的复杂性,需要多写些例子理解下
以上内容如有问题欢迎指出,笔者验证后将及时修正,谢谢
正文到此结束
热门推荐










相关文章






Loading...
![[HBLOG]公众号](http://www.liuhaihua.cn/img/qrcode_gzh.jpg)

