不加班的秘诀:如何利用AOE快速集成NCNN!
AOE工程实践-NCNN组件
NCNN是腾讯开源的一个为手机端极致优化的高性能神经网络前向计算框架。在AOE开源工程里,我们提供了NCNN组件,下面我们以SqueezeNet物体识别这个Sample为例,来讲一讲NCNN组件的设计和用法。
直接集成NCNN缺点
为SqueezeNet接入NCNN,把相关的模型文件,NCNN的头文件和库,JNI调用,前处理和后处理相关业务逻辑等。把这些内容都放在SqueezeNet Sample工程里。这样简单直接的集成方法,问题也很明显,和业务耦合比较多,不具有通用性,前处理后处理都和SqueezeNcnn这个Sample有关,不能很方便地提供给其他业务组件使用。深入思考一下,如果我们把AI业务,作为一个一个单独的AI组件提供给业务的同学使用,会发生这样的情况:

每个组件都要依赖和包含NCNN的库,而且每个组件的开发同学,都要去熟悉NCNN的接口,写C的调用代码,写JNI。所以我们很自然地会想到要提取一个NCNN的组件出来,例如这样:
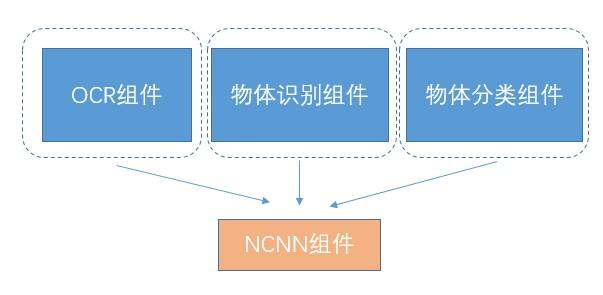
AOE SDK里的NCNN组件
在AOE开源SDK里,我们提供了NCNN组件,下面我们从4个方面来讲一讲NCNN组件:
* NCNN组件的设计
* 对SqueezeNet Sample的改造
* 应用如何接入NCNN组件
* 对NCNN组件的一些思考
NCNN组件的设计
NCNN组件的设计理念是组件里不包含具体的业务逻辑,只包含对NCNN接口的封装和调用。具体的业务逻辑,由业务方在外部实现。在接口定义和设计上,我们参考了TF Lite的源码和接口设计。目前提供的对外调用接口,主要有以下几个:
`// 加载模型和param
void loadModelAndParam(...)
// 初始化是否成功
boolean isLoadModelSuccess()
// 输入rgba数据
void inputRgba(...)
// 进行推理
void run(...)
// 多输入多输出推理
void runForMultipleInputsOutputs(...)
// 得到推理结果
Tensor getOutputTensor(...)
// 关闭和清理内存
void close()`
新的代码结构如下:
`├── AndroidManifest.xml
├── cpp
│ └── ncnn
│ ├── c_api_internal.h
│ ├── include
│ ├── interpreter.cpp
│ ├── Interpreter.h
│ ├── jni_util.cpp
│ ├── jni_utils.h
│ ├── nativeinterpreterwrapper_jni.cpp
│ ├── nativeinterpreterwrapper_jni.h
│ ├── tensor_jni.cpp
│ └── tensor_jni.h
├── java
│ └── com
│ └── didi
│ └── aoe
│ └── runtime
│ └── ncnn
│ ├── Interpreter.java
│ ├── NativeInterpreterWrapper.java
│ └── Tensor.java
└── jniLibs
├── arm64-v8a
│ └── libncnn.a
└── armeabi-v7a
└── libncnn.a`
* Interpreter,提供给外部调用,提供模型加载,推理这些方法。
* NativeInterpreterWrapper是具体的实现类,里面对native进行调用。
* Tensor,主要是一些数据和native层的交互。
AOE NCNN组件有以下几个特点:
* 支持多输入多输出。
* 使用ByteBuffer来提升效率。
* 使用Object作为输入和输出(实际支持了ByteBuffer和多维数组)。
下面我们来说说具体是如何做的。
如何支持多输入多输出
为了支持多输入和多输出,我们在Native层创建了一个Tensor对象的列表,每个Tensor对象里保存了相关的输入和输出数据。Native层的Tensor对象,通过tensor_jni提供给java层调用,java层维护这个指向native层tensor的“指针”地址。这样在有多输入和多输出的时候,只要拿到这个列表里的对应的Tensor,就可以就行数据的操作了。
ByteBuffer的使用
ByteBuffer,字节缓存区处理子节的,比传统的数组的效率要高。
DirectByteBuffer,使用的是堆外内存,省去了数据到内核的拷贝,因此效率比用ByteBuffer要高。
当然ByteBuffer的使用方法不是我们要说的重点,我们说说使用了ByteBuffer以后,给我们带来的好处:
1,接口里的字节操作更加便捷,例如里面的putInt,getInt,putFloat,getFloat,flip等一系列接口,可以很方便的对数据进行操作。
2,和native层做交互,使用DirectByteBuffer,提升了效率。我们可以简单理解为java层和native层可以直接对一块“共享”内存进行操作,减少了中间的字节的拷贝过程。
如何使用Object作为输入和输出
目前我们只支持了ByteBuffer和MultiDimensionalArray。在实际的操作过程中,如果是ByteBuffer,我们会判断是否是direct buffer,来进行不同的读写操作。如果是MultiDimensionalArray,我们会根据不同的数据类型(例如int, float等),维度等,来对数据进行读写操作。
对SqueezeNet Sample的改造
集成AOE NCNN组件以后,让SqueezeNet依赖NCNN Module,SqueezeNet Sample里面只包含了模型文件,前处理和后处理相关的业务逻辑,前处理和后处理可以用java,也可以用c来实现,由具体的业务实现来决定。新的代码结构变得非常简洁,目录如下:
`├── AndroidManifest.xml
├── assets
│ └── squeeze
│ ├── model.config
│ ├── squeezenet_v1.1.bin
│ ├── squeezenet_v1.1.id.h
│ ├── squeezenet_v1.1.param.bin
│ └── synset_words.txt
└── java
└── com
└── didi
└── aoe
└── features
└── squeeze
└── SqueezeInterpreter.java
`
其他的AI业务组件对NCNN组件的调用,都可以参考SqueezeNet这个Sample。
应用如何接入NCNN组件
对NCNN组件的接入,有两种方式
直接接入
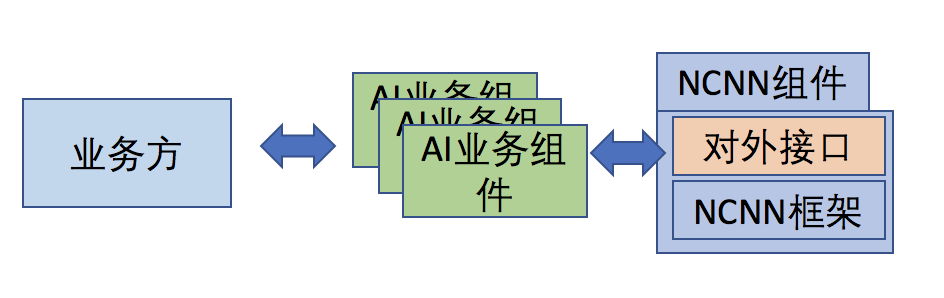
通过AOE SDK接入
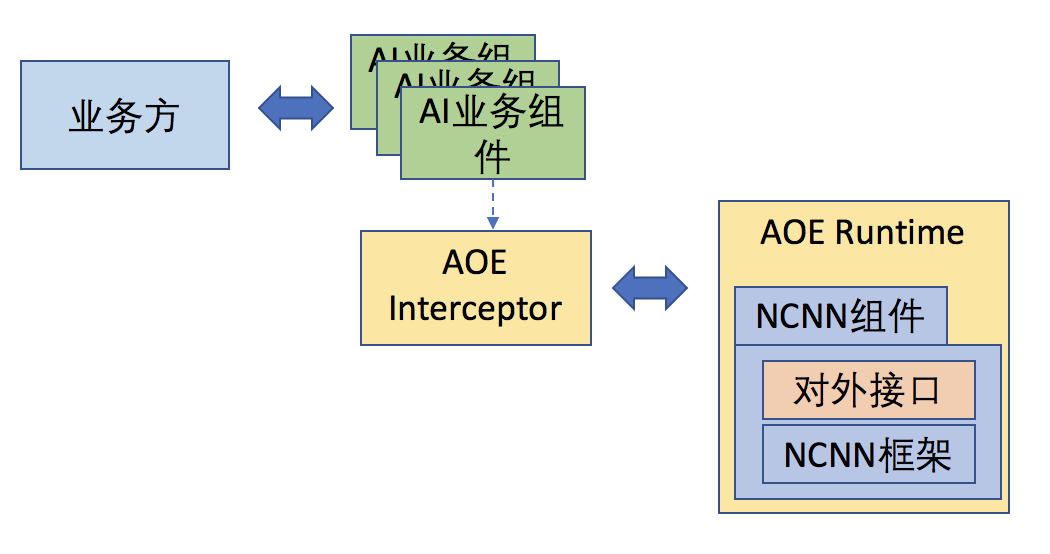
两种接入方式比较:

通过比较,我们更建议是通过AOE SDK来对我们的NCNN组件进行接入。
对NCNN组件的总结和思考
通过对NCNN组件的封装,现在业务集成NCNN更加快捷方便了。之前我们一个新的业务集成NCNN,可能需要半天到一天的时间。使用AOE NCNN组件以后,可能只需要1-2小时的时间。
当然NCNN组件目前还存在很多不完善的地方,我们对NCNN还需要去加深学习和理解。后面会通过不断的学习,持续的对NCNN组件进行改造和优化。
欢迎大家来使用和提建议
AoE (AI on Edge,终端智能,边缘计算) 是一个终端侧AI集成运行时环境 (IRE),帮助开发者提升效率。 https://github.com/didi/aoe
欢迎star~
欢迎添加小助手微信进入AOE开源交流群

正文到此结束
热门推荐










相关文章

近期评论
-
你这基本没有更新呀,最近文章显示还是2019年的文章。不符合要求哈
-
关键词:慕云博客 链接:https://www.lilun.me 描述:分享原创文字的个人博客
-
-
-
可以提供一下源码吗
-
不是商业站,鸡娃学习笔记
-
-
-
-
听他们说很厉害的样子
Loading...
![[HBLOG]公众号](http://www.liuhaihua.cn/img/qrcode_gzh.jpg)

