深入浅出Disruptor
作者 | 高建

面向 CTRL C + V 的编码工具人。
说到队列,大家都很熟悉,像生活中不管是吃饭还是买东西基本上都会遇到排队,先排队的人先付款,不允许插队!先进先出,这就是典型的“队列”。
简单回顾 jdk 里的队列
1. 阻塞队列:
ArrayBlockingQueue: Object[] + count + lock.condition (notEmpty、notFull)。
-
入队:
-
不阻塞:add、offer 满了直接报错。
-
阻塞:put 满了:notFull.await()(当出队和删除元素时唤醒 put 操作)。
-
出队:
-
take():当空时,notEmpty.await()(当有元素入队时唤醒)。
-
poll():当空时直接返回 null。
LinkedBlockingQueue:Node 实现、加锁(读锁、写锁分离)、可选的有界队列。需要考虑实际使用中的内存问题,防止溢出。
应用:
Eexcutors 默认是使用 LinkedBlockingQueue,但是在实际应用中,更应该手动创建线程池使用有界队列,防止生产者生产过快,导致内存溢出。
2. 延迟队列:
DelayQueue : PriorityQueue (优先级队列) + Lock.condition (延迟等待) + leader (避免不必要的空等待)。
主要方法:
-
getDelay() 延迟时间。
-
compareTo() 通过该方法比较从 PriorityQueue 里取值。
-
入队:
-
add、put、offer:入队时会将换唤醒等待中的线程,进行一次出队处理。
-
出队:
-
如果队列里无数据,元素入队时会被唤醒。
-
有数据,会阻塞至时间满足。
-
take()阻塞:
-
poll():满足队列有数据并且 delay 时间不大于0会取出元素,否则立即返回 null 可能会抢占成为 leader。
还有优先级队列等就不一一细说,有兴趣的同学可以去看一下。
应用:
延时任务:设置任务延迟多久执行;需要设置过期值的处理,例如缓存过期。
实现方式:每次 getDealy() 方法提供一个缓存创建时间与当前时间的差值,出队时 compareTo() 方法取差值最小的。每次入队时都会重新取出队列里差值最小的值进行处理。
我们使用队列的,更多的是像生产者、消费者这种场景。这种场景大多数情况又对处理速度有着要求,所以我们会使用多线程技术。使用多线程就可能会出现并发,为了避免出错,我们会选择线程安全的队列。例如 ArrayBlockingQueue、LinkedBlockingQueue 或者是 ConcurrentLinkedQueue。前俩者是通过加锁取实现,后面一种是通过 cas 去实现线程安全。但是又要考虑到生产者过快可能造出的内存溢出的问题,所以看起来 ArrayBlockingQueue 是最符合要求的。但是恰恰加锁效率又会变慢,所以就引出了我们今天讨论的主题:Disruptor !
Disruptor
介绍
Martin Fowler 在自己网站上写了一篇 LMAX 架构的文章,在文章中他介绍了 LMAX 是一种新型零售金融交易平台,它能够以很低的延迟产生大量交易。这个系统是建立在 JVM 平台上,其核心是一个业务逻辑处理器,它能够在一个线程里每秒处理 600 万订单。使用事件源驱动方式,业务逻辑处理器的核心是 Disruptor 。
为什么说 Disruptor 的性能要更优于 ArrayBlockingQueue,有什么根据吗?先不探究原理,先看一段代码。
比较:ArrayBlockingQueue VS Disruptor
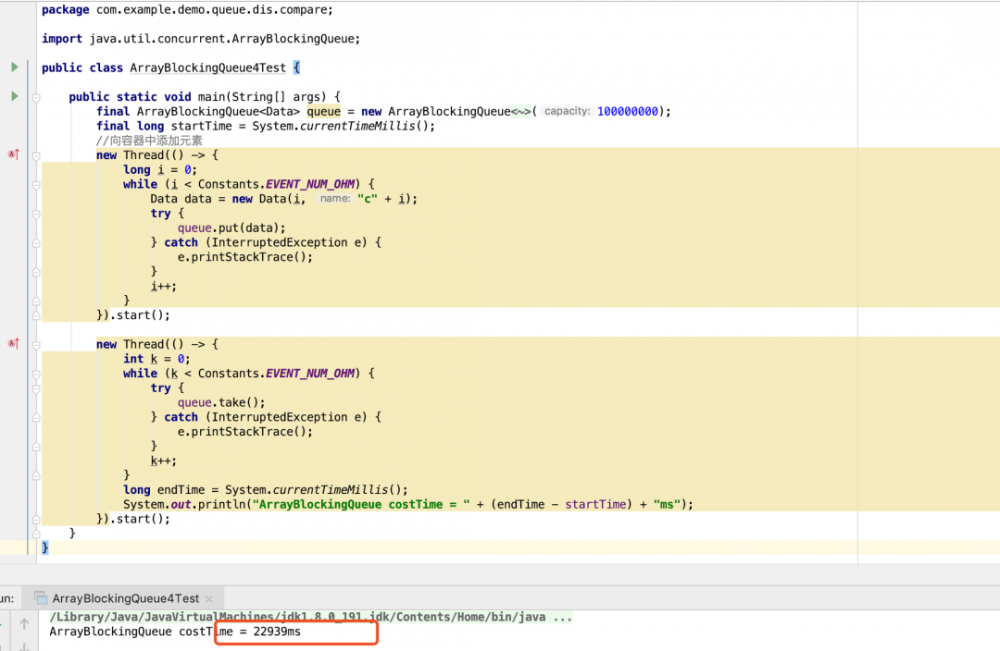
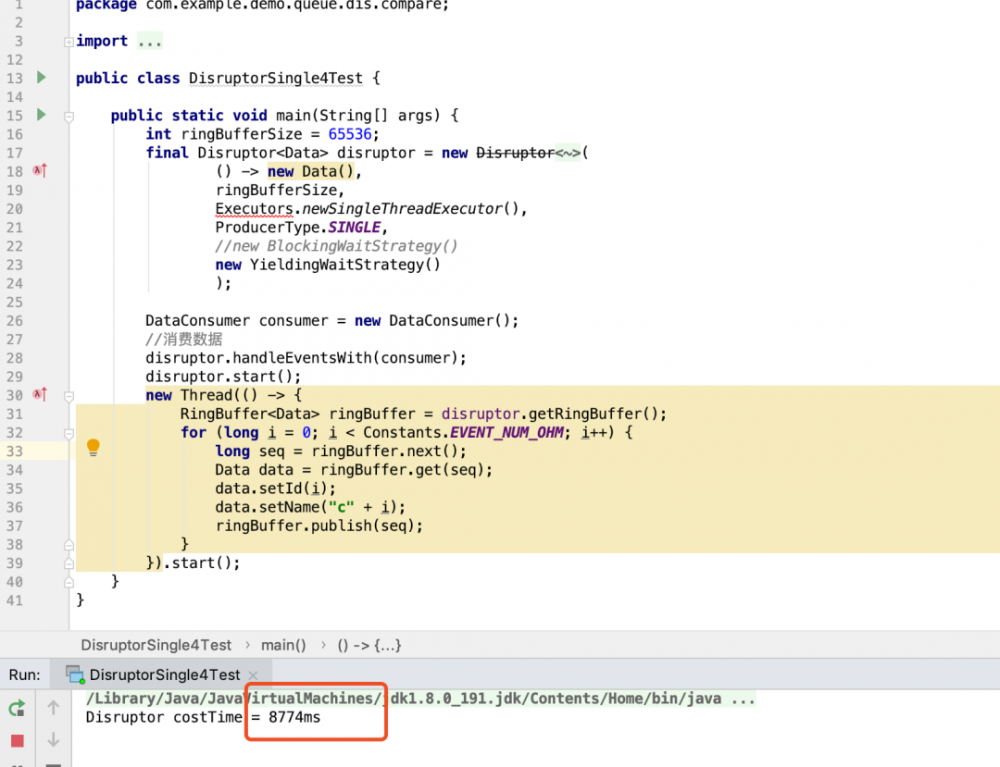
上面俩幅图分别是比较 100000000 条数据下,ArrayBlockingQueue 和 Disruptor 的存取效率。 同样我也比较了:
-
当数据为 10000000 条时,Disruptor 为 1101ms,ArrayBlockingQueue 为 2782ms;
-
当数据为 50000000 条时,Disruptor 为 5002ms,ArrayBlockingQueue 为 13770ms;
代码使用的都是单生产者、单消费者。当使用多线程的时候,Disruptor 还会更快。所以可以看出,Disruptor 在性能上是优于 ArrayBlockingQueue 的。
接下来我们来看一下 Disruptor 是如何做到 无阻塞、多生产、多消费 的。
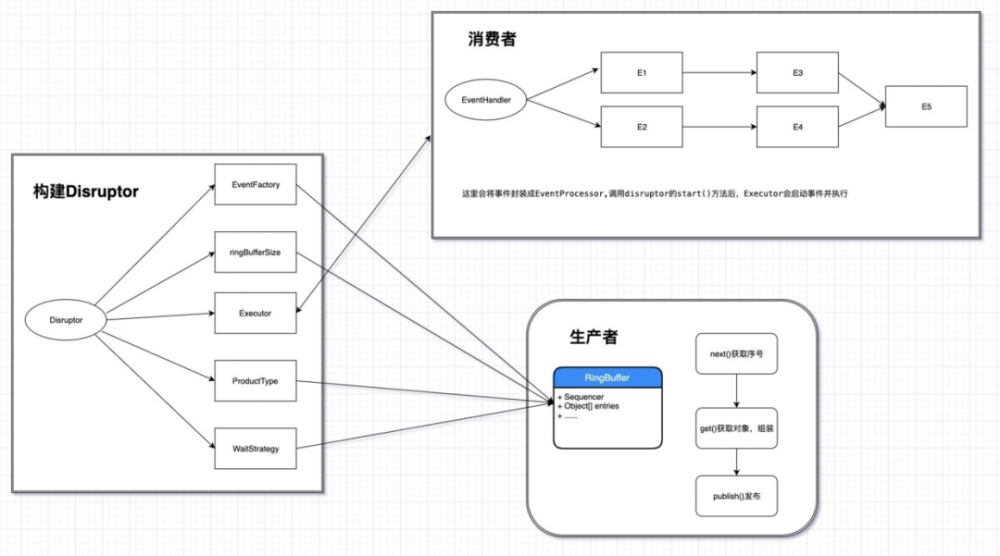
上图简单的画了一下构建 Disruptor 的各个参数以及 ringBuffer 的构造,下面简单的说一下。
-
EventFactory:创建事件(任务)的工厂类。(这里任务会创建好,保存在内存中,可以看做是一个空任务)。
-
ringBufferSize:容器的长度。( Disruptor 的核心容器是 ringBuffer,环转数组,有限长度)。
-
Executor:消费者线程池,执行任务的线程。(每一个消费者都需要从线程池里获得线程去消费任务)。
-
ProductType:生产者类型:单生产者、多生产者。
-
WaitStrategy:等待策略。(当队列里的数据都被消费完之后,消费者和生产者之间的等待策略)。
-
RingBuffer:存放数据的容器。
-
EventHandler:事件处理器。
Show me the code
下面简单看一下 Disruptor 的示例代码。
-
主类:定义Disruptor
public class TMainDisruptor {
public static void main(String[] args) throws InterruptedException {
//创建生产者工厂
TEventFactory eventFactory = new TEventFactory()。
int ringbuffersize = 1024 * 1024。
ExecutorService executorService = Executors.newFixedThreadPool(2)。
/**
* 实例化一个 Disruptor,Disruptor 本身并不做为生产者或是消费者,它更多像是一个包装器,将真正核心的生产者、消费者以及生产消费的动作以及容器串起来
*
* 1、消息工厂对象
* 2、容器的长度
* 3、线程池
* 4、生产者模式
* 5、等待策略
*/
Disruptor<OrderEvent> disruptor = new Disruptor(eventFactory, ringbuffersize, executorService, ProducerType.SINGLE,
new BlockingWaitStrategy())。
//这里定义了俩个相同事件
TEventHandler t1 = new TEventHandler()。
TEventHandler t2 = new TEventHandler()。
//跟消费者建立关系--监听
disruptor.handleEventsWith(t1)。
//顾名思义:执行完t1后执行t2。(对同一个任务线性执行)
disruptor.after(t1).handleEventsWith(t2)。
//启动
disruptor.start()。
//数据存储工具
RingBuffer ringBuffer = disruptor.getRingBuffer()。
//创建生产者
TEventProducer producer = new TEventProducer(ringBuffer)。
//投递数据
for(long i=0。i<10000。i++) {
producer.sendData(i)。
}
executorService.shutdown()。
disruptor.shutdown()。
}
}
-
实例工厂
public class TEventFactory implements EventFactory<OrderEvent> {
@Override
public OrderEvent newInstance() {
//实例化数据(建好空数据,等后面取的时候可以直接用)
return new OrderEvent()。
}
}
-
对象
@Data
public class OrderEvent {
private Long id。
private String price。
private String finalPrice。
}
-
消费者执行事件:任务执行体
public class TEventHandler implements EventHandler<OrderEvent> {
/**
* 事件驱动监听--消费者消费的主体
*/
@Override
public void onEvent(OrderEvent event, long sequence, boolean endOfBatch) throws Exception {
//简单打印一下当前事件ID和执行线程的名称
System.out.println(event.getId() + " " +Thread.currentThread().getName())。
}
}
-
生产者
@Data
@AllArgsConstructor
public class TEventProducer {
private RingBuffer<OrderEvent> ringBuffer。
public void sendData(long id) {
//获取下一个可用序号
long sequence = ringBuffer.next()。
try {
//获取一个空对象(没有填充值)
OrderEvent orderEvent = ringBuffer.get(sequence)。
//赋值
orderEvent.setId(id)。
}finally {
//提交
ringBuffer.publish(sequence)。
}
}
}
以上代码就是一个简单的 Disruptor 的 demo 示例。运行代码就可以看到 handler 打印数据。demo 跑起来后,就可以进行程序员最爱的 debug 大法了。
启动过程分析之消费者
在 TMainDisruptor 类的 main 方法里,定义完 Disruptor 并关联好任务处理事件后,就调用了 disruptor.start() 方法,可以看出在调用了 start() 方法后,消费者线程就已经开启。
-
start() -- 开启 Disruptor,运行事件处理器。
public RingBuffer<T> start()
{
checkOnlyStartedOnce()。
//在前面 handleEventsWith() 方法里添加的 handler 对象会加入到 consumerRepository 里,这里遍历 consumerRepository 开启消费者线程
for (final ConsumerInfo consumerInfo : consumerRepository)
{
//从线程池中获取一个线程来开启消费事件处理器。(消费者开启监听,一旦有生产者投递,即可消费)
//这里开启的线程对象为 BatchEventProcessor 的实例
consumerInfo.start(executor)。
}
return ringBuffer。
}
-
handleEventsWith()--> createEventProcessors() -- 调用的核心方法,作用是创建事件处理器。
@SafeVarargs
public final EventHandlerGroup<T> handleEventsWith(final EventHandler<? super T>... handlers)
{
return createEventProcessors(new Sequence[0], handlers)。
}
EventHandlerGroup<T> createEventProcessors(
final Sequence[] barrierSequences,
final EventHandler<? super T>[] eventHandlers)
{
...
final Sequence[] processorSequences = new Sequence[eventHandlers.length]。
//创建 sequence 序号栅栏
final SequenceBarrier barrier = ringBuffer.newBarrier(barrierSequences)。
for (int i = 0, eventHandlersLength = eventHandlers.length。i < eventHandlersLength。i++)
{
final EventHandler<? super T> eventHandler = eventHandlers[i]。
final BatchEventProcessor<T> batchEventProcessor = new BatchEventProcessor<>(ringBuffer, barrier, eventHandler)。
...
//这里将消费者加入到 consumerRepository 中---ConsumerRepository
consumerRepository.add(batchEventProcessor, eventHandler, barrier)。
processorSequences[i] = batchEventProcessor.getSequence()。
}
...
}
在看上面的 handleEventsWith() 方法中,可以看到构建了一个 BatchEventProcessor(继承了 Runnable 接口)对象,start()方法启动的同样也是这个对象的实例。这个对象继承自 EventProcessor ,EventProcessor 是 Disruptor 里非常核心的一个接口,它的实现类的作用是轮询接收 RingBuffer 提供的事件,并在没有可处理事件是实现等待策略。这个接口的实现类必须要关联一个线程去执行,通常我们不需要自己去实现它。这里主要说一下它的默认实现类 BatchEventProcessor 类。
BatchEventProcessor:主要事件循环,处理 Disruptor 中的 event,拥有消费者的 Sequence。它的核心主要主要包含以下:
-
核心私有成员变量
-
Sequence sequence :维护当前消费者消费的 ID。
-
SequenceBarrier sequenceBarrier :序号屏障,协调消费者的消费 ID,主要作用是获取消费者的可用序号,并提供等待策略的执行。
-
EventHandler<? super T> eventHandler :消费者的消费逻辑(也就是我们实现的业务逻辑)。
-
DataProvider
dataProvider :获取消费对象。RingBuffer 实现了此接口,主要是提供业务对象(例如上面代码中的 OrderEvent )。 -
核心方法
-
processEvents():由于 BatchEventProcessor 继承自 Runnable 接口,所以在前面启动它后,run() 方法会执行,而 run() 方法内部则会调用此方法。
private void processEvents()
{
T event = null。
////获取当前消费者维护的序号中并+1,即下一个消费序号
long nextSequence = sequence.get() + 1L。
while (true)
{
try
{
//获取可执行的最大的任务 ID,如果没有,waitFor() 方法内会进行等待
final long availableSequence = sequenceBarrier.waitFor(nextSequence)。
if (batchStartAware != null && availableSequence >= nextSequence)
{
batchStartAware.onBatchStart(availableSequence - nextSequence + 1)。
}
//不断获取对应位置的任务进行消费 直到上面查询到的 availableSequence 消费完
while (nextSequence <= availableSequence)
{
event = dataProvider.get(nextSequence)。
eventHandler.onEvent(event, nextSequence, nextSequence == availableSequence)。
nextSequence++。
}
sequence.set(availableSequence)。
}
...
}
}
以上代码片段中消费者事件处理器的核心代码,sequenceBarrier.waitFor(nextSequence) 方法内部,会比较当前消费者序号与可用序号的大小,当可用序号(availableSequence)大于当前消费者序号(nextSequence),再获取到当前可用的最大的事件序号 ID(waitFot()方法内部调用 sequencer.getHighestPublishedSequence(sequence, availableSequence)),进行循环消费。可用序号是维护在 ProcessingSequenceBarrier 里的,ProcessingSequenceBarrier 是通过 ringBuffer.newBarrier() 创建出来的。请看下图:
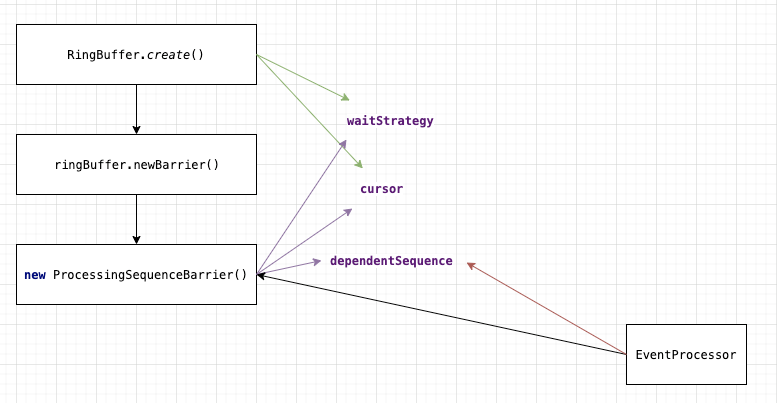
由图可以看出,在获得可用序号时,SequenceBarrier 在 EventProcessor 和 RingBuffer 中充当协调的角色。多消费事件和单消费事件在 dependentSequence 上的处理有一些不同,可以看下 ProcessingSequenceBarrier 的 dependentSequence 的赋值以及 get() 方法 (Util.getMinimumSequence(sequences)) 这里细节就不再展开说明了。
启动过程分析之生产者
在上面生产者的代码中,可以看到我们首先调用了 ringBuffer.next() 方法,获取可用序号,再获取到该序号下事先通过 factory 创建好的空事件对象,在我们对空事件对象进行赋值后,再调用 publish 方法将事件发布,则消费者就可以获取进行消费了。
生产者这里的核心代码如下,这里我截取的是多生产者模式下的代码:
@Override
public long next(int n)
{
if (n < 1 || n > bufferSize)
{
throw new IllegalArgumentException("n must be > 0 and < bufferSize")。
}
long current。
long next。
do
{
//cursor 为生产者维护的 sequence 序列,获取到当前可投递的的下标,即当前投递到该位置
current = cursor.get()。
//再+n获取下一个下表,即下一次投递的位置。
next = current + n。
long wrapPoint = next - bufferSize。
//目的:也是实现快读的读写。gatingSequenceCache 独占缓存行
long cachedGatingSequence = gatingSequenceCache.get()。
if (wrapPoint > cachedGatingSequence || cachedGatingSequence > current)
{
//获取消费者最小序号
long gatingSequence = Util.getMinimumSequence(gatingSequences, current)。
if (wrapPoint > gatingSequence)
{
//如果不符合,则阻塞线程 1ns(park()不会有死锁的问题)
LockSupport.parkNanos(1)。// TODO, should we spin based on the wait strategy?
continue。
}
gatingSequenceCache.set(gatingSequence)。
}
//多个生产者时要保证线程安全(这里更新的 cursor 同时也是等待策略里的 waitFor() 方法的 cursor 参数,因此这里更新成功后,则等待策略会通过,表示有新的任务进来,就会消费)
else if (cursor.compareAndSet(current, next))
{
break。
}
}
while (true)。
return next。
}
这里主要讲一下 cursor 对象和 Util.getMinimumSequence(gatingSequences, current) 方法。
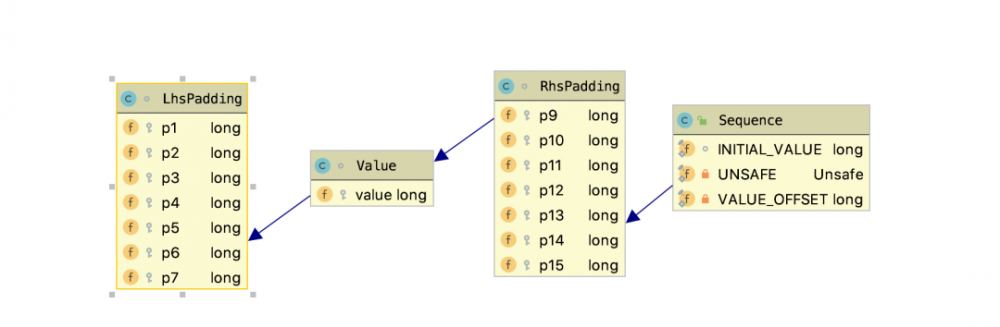
cursor 对象是生产者维护的一个生产者序号,标示当前生产者已经生产到哪一个位置以及下一个位置。它是 Sequence 类的一个实例化对象。下图是 Sequence 类的类图。从图里可以看出,Sequence 继承以及间接继承了 RhsPadding 和 LhsPadding 类,而这俩个类都各定义了 7 个 long 类型的成员变量。而 Sequence 的 get() 方法返回的也是一个 long 类型的值 value。这个是 Disruptor 的 核心设计之一--填充缓存行,消除伪共享 。
在 64 位的计算机中,单个缓存行一般占 64 个字节,当 cpu 从换存里取数据时,会将该相关数据的其它数据取出来填满一个缓存行,这时如果其它数据更新,则缓存行缓存的该数据也会失效,当下次需要使用该数据时又需要重新从内存中提取数据。ArrayBlockingQueue 获取数据时,很容易碰到伪共享导致缓存行失效,而 Disruptor 这里当在 vaule 的左右各填充 7 个 long 类型的数据时,每次取都能确保该数据独占缓存行,也不会有其他的数据更新导致该数据失效。避免了伪共享的问题( jdk 的并发包下也有一些消除伪共享的设计)。
在讲 Util.getMinimumSequence(gatingSequences, current) 方法之前我们先说一下 RingBuffer。
RingBuffer :它是一个首尾相接的环状的容器,用来在多线程中传递数据。第一张图里面创建 Disruptor 的多个参数其实都是用来创建 RingBuffer 的,比如生产者类型(单 or 多)、实例化工厂、容器长度、等待策略等。结构简单如下图:

单生产者单消费者模式下很好理解,每次都从 ringBuffer 中直接获取下一个可用序号。那么如果是多生产者多消费怎么办呢?
多生产多消费模型
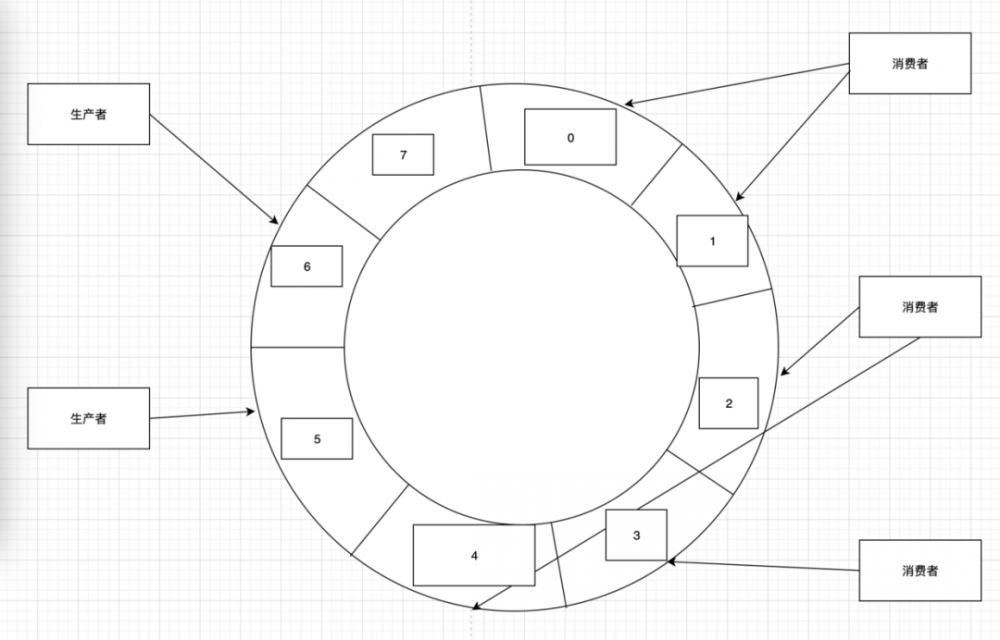
简单分析,多个生产者同时向 ringbuffer 投递数据,假设此时俩个生产者将 ringbuffer 已经填满,因为 sequence 的序号是自增+1(若不满足获取条件则循环挂起当前线程),所以生产的时候能保证线程安全,只需要一个 sequence 即可。当多消费者来消费的时候,因为消费速度不同,例如消费者 1 来消费 0、1,消费者 2 消费 2、4,消费者 3 消费 3。当消费者消费完 0 后,消费者 2 消费完 2 后,消费者 3 消费完 3 后,生产者再往队列投递数据时,其他位置还未被消费,会投递到第 0 个位置, 此时再想投递数据时,虽然消费 2 的第二个位置空缺、消费者 3 的第三个位置空缺,消费者还在消费 1 时,无法继续投递。因为是通过比较消费者自身维护的 sequence 的最小的序号,来进行比较。
所以这里 Util.getMinimumSequence(gatingSequences, current) 方法也就无需再多说,它就是为了获取到多个消费者的最小序号,判断当前 ringBuffer 中的剩余可用序号是否大于消费者最小序号,是的话,则不能投递,需要阻塞当前线程(LockSupport.parkNanos(1))。注意:这里没有用到锁。
上面说到 ringBuffer 有定义长度,说明是一个有界的队列,那么可能会出现以下俩种情况:当消费者消费速度大于生产者生产者速度,生产者还未来得及往队列写入,或者生产者生产速度大于消费者消费速度,此时怎么办呢?而且上面也多次提到没有满足条件的消费事件时,消费者会等待,接下来说一下消费者的等待策略。
常用的WaitStrategy等待策略(消费者等待)
-
BlockingWaitStrategy 使用了锁,低效的策略。
-
SleepingWaitStrategy 对生产者线程的影响最小,适合用于异步日志类似的场景。(不加锁空等)
-
YieldingWaitStrategy 性能最好,适合用于低延迟的系统,在要求极高性能且之间处理线数小于 cpu 逻辑核心数的场景中,推荐使用。(无锁策略。主要是使用了 Thread.yield() 多线程交替执行)
这里着重介绍一下 YieldingWaitStrategy 策略,因为这个是性能最高的,当我们的业务场景需要极速处理生产消费时,选它准没错! 上面提到 BatchEventProcessor 的 processEvents 方法里调用了 waitFor() 方法,waitFor() 方法是 WaitStrategy 接口的定义的方法,所有的等待策略的实现类都实现了它。看下 YieldingWaitStrategy 的实现方法:
@Override
public long waitFor(
final long sequence, Sequence cursor, final Sequence dependentSequence, final SequenceBarrier barrier)
throws AlertException, InterruptedException
{
long availableSequence。
int counter = SPIN_TRIES。//100
while ((availableSequence = dependentSequence.get()) < sequence)
{
counter = applyWaitMethod(barrier, counter)。
}
return availableSequence。
}
private int applyWaitMethod(final SequenceBarrier barrier, int counter)
throws AlertException
{
barrier.checkAlert()。
if (0 == counter)
{
Thread.yield()。
}
else
{
--counter。
}
return counter。
}
上面也提到过,当 availableSequence 小于 sequence 时,会等待,直到 availableSequence 不小于 sequence,waitFor() 方法才会返回告知消费者有可以消费的消费序号。这里主要是 applyWaitMethod 方法,它会首先进行一个 100 次的循环,不断去尝试当前返回条件是否满足,当 counter 减为 0 时,不断的挂起当前线程。yield() 方法是使当前线程交出执行权,再加入到竞争行列中,所以你可以测试,当你消费者没有可消费的数据时,会不停的在这里执行,直到有可用的消费事件。注意:这里也没有用到锁。这句话有点熟悉。。。因为在前面讲到多生产者多消费模型时,我提到生产者的等待也没有用到锁。所以这是 Disruptor 快的另外一个原因,多生产多消费场景下,无锁。但是有同学肯定可以想到,这里当没有可用消费事件的时候消费者线程还在不停竞争 cpu 在执行、不断的转,所以这也是 Disruptor 做为一款工业级产品时,对cpu的极致压榨以换取性能,包括前面的填充缓存行,用更多的缓存空间去换取更快的效率。
当然 Disruptor 也提供了 BlockingWaitStrategy 的锁等待通知以及 SleepingWaitStrategy 的空等策略以及一些其它的策略,来供我们在不同的业务场景选取不同的策略搭配使用。所以它也并不是无脑的干你的 cpu,你可以选~~~
Show me the code
以下是多生产多消费的部分代码:
public class TMainWorker {
public static void main(String[] args) throws InterruptedException {
System.out.println("begin")。
RingBuffer ringBuffer = RingBuffer.create(ProducerType.MULTI, new TEventFactory(), 1024*1024,
new YieldingWaitStrategy())。
SequenceBarrier sequenceBarrier = ringBuffer.newBarrier()。
//多消费者
TWorkHanler[] workHanlers = new TWorkHanler[5]。
for(int i=0。i<5。i++) {
workHanlers[i] = new TWorkHanler("h" + i, new AtomicInteger(0))。
}
WorkerPool workerPool = new WorkerPool(ringBuffer, sequenceBarrier, new TexceptionHandler(), workHanlers)。
//获得消费池里的工作 sequence 的序号,遍历他们,找到最小的供使用。
ringBuffer.addGatingSequences(workerPool.getWorkerSequences())。
//创建消费者工厂
ExecutorService executorService = new ThreadPoolExecutor(3, 3,
0L, TimeUnit.MILLISECONDS,
new LinkedBlockingQueue<>())。
workerPool.start(executorService)。
CountDownLatch countDownLatch = new CountDownLatch(1)。
for(int i=0。i<3。i++) {
new Thread(()-> {
TEventProducer producer = new TEventProducer(ringBuffer)。
try {
countDownLatch.await()。
} catch (InterruptedException e) {
e.printStackTrace()。
}
for(int a=0。a<10000。a++) {
producer.sendData(a)。
}
}).start()。
}
countDownLatch.countDown()。
}
至此,Disruptor 的基本核心概念已经介绍完毕!接下来介绍一下 Disruptor 的好玩的地方。
Disruptor多边形操作
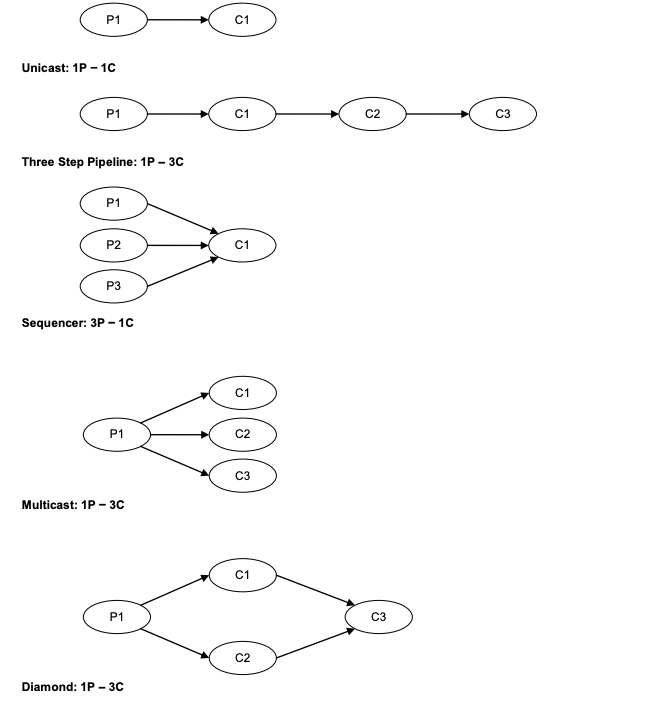
上图是 Disruptor 的官方文档列出的 Disruptor 可以做的一些操作示例。
简单看一下如何实现文中第一张图里的多边形操作?
disruptor.handleEventsWith(E1, E2)。 disruptor.after(E1).handleEventsWith(E3)。 disruptor.after(E2).handleEventsWith(E4)。 disruptor.after(E3, E4).handleEventsWith(E5)。
借助 Disruptor 里的强大语义,可以组合出各种多边形(骚)操作。
public EventHandlerGroup<T> handleEventsWith(final EventProcessor... processors)
{
...
}
@SafeVarargs
@SuppressWarnings("varargs")
public final EventHandlerGroup<T> handleEventsWithWorkerPool(final WorkHandler<T>... workHandlers)
{
...
}
public EventHandlerGroup<T> after(final EventProcessor... processors)
{
...
}
上面的方法入参都是...,你懂的吧!
应用:
-
Apache Storm、Camel、Log4j2
Log4j2 example:
使用了实现 EventTranslator 的提交机制(文中并未介绍。。。有兴趣的同学可以了解学习以下。。。)。
可参考美团文章:https://tech.meituan.com/2016/11/18/disruptor.html 中指出:美团在公司内部统一推行日志接入规范,要求必须使用 Log4j2,使普通单机 QPS 的上限不再只停留在几千,极高地提升了服务性能。
补充
一些学习链接:
-
http://lmax-exchange.github.io/disruptor/files/Disruptor-1.0.pdf (这篇我也没看。。。)
-
https://ifeve.com/disruptor/
-
https://github.com/LMAX-Exchange/disruptor (disruptor的源码并不多)
全文完
以下文章您可能也会感兴趣:
-
中文房间之争:浅论到底什么是智能
-
从零搭建一个基于 lstio 的服务网格
-
容器管理利器:Web Terminal 简介
-
简单说说spring的循环依赖
-
Mysql redo log 漫游
-
RabbitMQ 如何保证消息可靠性
-
OpenResty 不完全指南
-
如何进行系统分析与设计
-
ConcurrentHashMap 的 size 方法原理分析
-
从 ThreadLocal 的实现看散列算法

正文到此结束
- 本文标签: 实例 provider ACE Service 模型 QPS spring mina cat UI 空间 遍历 final 删除 处理器 rabbitmq 缓存 rmi db 产品 金融 时间 Disruptor 锁 http Atom id CountDownLatch mysql node 线程 map 代码 HTML 参数 src queue MQ JVM 源码 tar sql GitHub 程序员 快的 example producer IO ConcurrentHashMap 启动过程 安全 多线程 美团 ThreadPoolExecutor FAQ executor HashMap 并发 测试 https apr 管理 App REST OpenResty 线程池 cache 原理分析 类图 web git 房间 IDE 智能 value consumer 文章 ORM bug log4j2 apache struct 网站 数据 CTO
- 版权声明: 本文为互联网转载文章,出处已在文章中说明(部分除外)。如果侵权,请联系本站长删除,谢谢。
- 本文海报: 生成海报一 生成海报二
热门推荐










相关文章






Loading...
![[HBLOG]公众号](http://www.liuhaihua.cn/img/qrcode_gzh.jpg)

