字符串比较--小问题大智慧
String相等之谜
引言:在最近的Java学习中,遇到一些关于字符串的小问题,现在此做一些总结
Java中的“相等”
等号大比拼
-
==
众所周知,在 Java 中如果用
==比较两个对象,那就是比较两个对象是否在内存的同一个位置(地址是否相同)。 -
equals
在 Java 中,所有类的父类 Object 存在一个
equals方法,String类复写了这个方法,它实现了真正的字符串比较,代码如下:public boolean equals(Object anObject) { if (this == anObject) { return true; } if (anObject instanceof String) { String anotherString = (String)anObject; int n = value.length; if (n == anotherString.value.length) { char v1[] = value; char v2[] = anotherString.value; int i = 0; while (n-- != 0) { if (v1[i] != v2[i]) return false; i++; } return true; } } return false; } -
hashCode
通常情况下,当我们重写
equals方法时,我们需要重写hashCode方法 以保持一致性。默认的hashCode方法与地址有关。
热身--JVM内存结构
概览
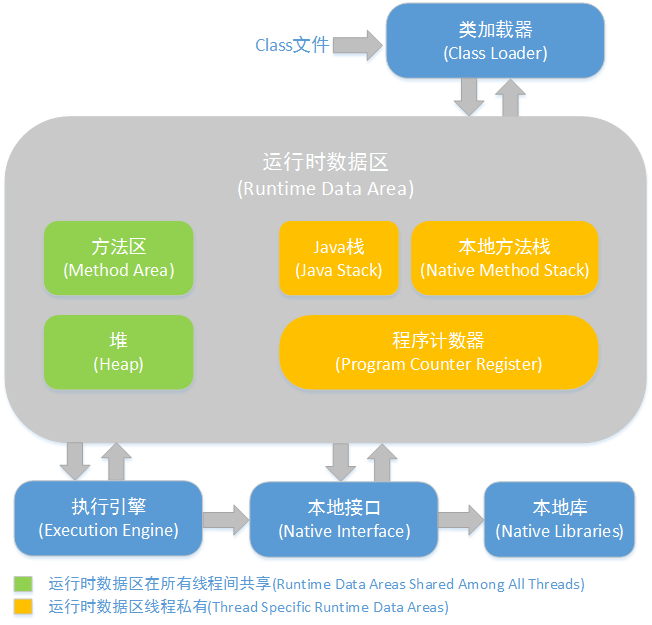
看到上图,我们简单介绍一下 Java Stack , Method Area 和 Heap 。这几个我们经常提到的内存区。
-
Java堆(Heap)
对于大多数应用来说,Java堆(Java Heap)是Java虚拟机所管理的内存中 最大 的一块。Java堆是被所有线程共享的一块内存区域,在虚拟机启动时创建。此内存区域的唯一目的就是存放对象实例, 几乎所有的对象实例都在这里分配内存。 (我们 new 出来的东西都放在这里)
-
方法区(Method Area)
方法区(Method Area)与Java堆一样,是各个线程共享的内存区域, 它用于存储已被虚拟机加载的类信息、常量、静态变量、即时编译器编译后的代码等数据 。虽然Java虚拟机规范把方法区描述为堆的一个逻辑部分,但是它却有一个别名叫做Non-Heap(非堆),目的应该是与Java堆区分开来。
-
JVM栈(JVM Stacks)
与程序计数器一样,Java虚拟机栈(Java Virtual Machine Stacks)也是线程私有的, 它的生命周期与线程相同 。 虚拟机栈描述的是Java方法执行的内存模型 :每个方法被执行的时候都会同时创建一个栈帧(Stack Frame)用于存储局部变量表、操作栈、动态链接、方法出口等信息。 每一个方法被调用直至执行完成的过程,就对应着一个栈帧在虚拟机栈中从入栈到出栈的过程 。
局部变量表存放了编译期可知的各种基本数据类型(boolean、byte、char、short、int、float、long、double)、对象引用(reference类型,它不等同于对象本身,根据不同的虚拟机实现,它可能是一个指向对象起始地址的引用指针,也可能指向一个代表对象的句柄或者其他与此对象相关的位置)和returnAddress 类型(指向了一条字节码指令的地址)。
其中64位长度的long和double类型的数据会占用2个局部变量空间(Slot),其余的数据类型只占用1个。局部变量表所需的内存空间在编译期间完成分配,当进入一个方法时,这个方法需要在帧中分配多大的局部变量空间是完全确定的,在方法运行期间不会改变局部变量表的大小。
在Java虚拟机规范中,对这个区域规定了两种异常状况:如果线程请求的栈深度大于虚拟机所允许的深度,将抛出 StackOverflowError 异常;如果虚拟机栈可以动态扩展(当前大部分的Java虚拟机都可动态扩展,只不过Java虚拟机规范中也允许固定长度的虚拟机栈),当扩展时无法申请到足够的内存时会抛出 OutOfMemoryError 异常。
讲完了 内存的概念, 我们就可以引入下一个问题了,码来!
public static void main(String[] args) { String t1 = "abc"; String t2 = new String("abc"); System.out.println(t1==t2); }我们看到
t1和t2的值都是 "abc",直觉上来看结果 应该返回true,但是运行以后 返回的是false,这是为什么呢?(因为他们的地址不同)。那么他们分别在哪呢?这里我们就要引入常量池的概念了。
常量池
Java中的常量池,通常指的是运行时常量池,它是方法区的一部分,一个JVM实例只有一个运行常量池,各线程间共享该运行常量池。
Java常量池简介:Java常量池中保存了一份在 编译期间 就已确定的数据。它里面包括 final常量 的值(包括成员常量、局部常量和引用常量)、以及 对象字面量 的值。
在编译期间,每当给常量赋值它就会去检测常量池中是否存在该值,若存在直接返回该值的地址给常量,若不存在则先在常量池中创建该值,再返回该值的地址给常量。因此常量池中不可能出现相等的数据。
- final常量
一切经final关键字修饰的变量均为常量,final常量必须在定义时就赋初值,否则编译不通过。
- 对象字面量
对象字面量是指直接以一常量给对象赋值,而不是在堆空间new出一个对象实例。
常见的两种对象字面量: 基本类型 的包装类对象字面量、 String 对象字面量。
String Pool
字符串常量池(String Pool)保存着所有字符串字面量(literal strings),这些字面量在编译时期就确定。不仅如此,还可以使用 String 的 intern() 方法在运行过程中将字符串添加到 String Pool 中。
当一个字符串调用 intern() 方法时,如果 String Pool 中已经存在一个字符串和该字符串值相等(使用 equals() 方法进行确定),那么就会返回 String Pool 中字符串的引用;否则,就会在 String Pool 中添加一个新的字符串,并返回这个新字符串的引用。
String s1 = new String("aaa");
String s2 = new String("aaa");
System.out.println(s1 == s2); // false,s1和s2的地址不同所以返回了false
String s3 = s1.intern();
String s4 = s1.intern();
System.out.println(s3 == s4); // true, s3和s4都指向了StringPool中的"aaa"是同一个对象所以返回了 true
PS:在 Java 7 之前,String Pool 被放在运行时常量池中,它属于永久代。而在 Java 7,String Pool 被移到堆中。这是因为永久代的空间有限,在大量使用字符串的场景下会导致 OutOfMemoryError 错误。
常量折叠
接下来让我们再看一个问题:
public static void main(String[] args) {
String a = "hello2";
final String b = "hello";
String d = "hello";
String c = b + 2;
String e = d + 2;
System.out.println((a == c));
System.out.println((a == e));
}
结果返回了:
true false
为什么呢?这就要引入 常量折叠 的概念。
常量折叠的概念
编译器优化 编译期常量
对于 String s1 = "1" + "2";
编译器会给你优化成 String s1 = "12";
在生成的字节码中,根本看不到 "1" "2" 这两个东西。
我们通过idea进行验证下
1、源码文件
public static void main(String[] args) {
String s1 = "1"+"2";
}
2、运行后,idea有个out文件夹,找到上面文件的class文件
public static void main(String[] args) {
String s1 = "12";
}
确实如上面所说,编译器会给你进行优化
常量折叠发生的条件
-
必须是 编译期常量之间 进行运算才会进行常量折叠。
-
编译期常量就是
“编译的时候就可以确定其值的常量”,
- 首先:字面量是
编译期常量。(数字字面量,字符串字面量等) - 其次:编译期常量进行
简单运算的结果也是编译期常量,如1+2,"a"+"b"。 - 最后:被编译器常量
赋值的 final 的基本类型和字符串变量也是编译期常量。
- 首先:字面量是
举个栗子
1.第一个栗子
public static void main(String[] args) {
String s1="a"+"bc";
String s2="ab"+"c";
System.out.println(s1 == s2);
}
相信大家都知道了,输出为 true
并且只创建了一个 "abc" 字符串对象,且位于字符串常量池中。
2、第二个栗子
public static void main(String[] args) {
String a = "a";
String bc = "bc";
String s1 = "a" + "bc";
String s2 = a + bc;
System.out.println(s1 == s2);
}
这个结果呢? false
s1 是字符串字面量相加,但是 s2 却是两个非 final 的变量相加,所以不会进行常量折叠。
而是根据 String 类特有的 + 运算符重载,变成类似这样的代码 (jdk1.8)
String s2 = new StringBuilder(a).append(b).toString();
这里 toString() 会生成新的String变量,显然用 == 运算符比较是会返回 false。
总结,只要牢记 常量折叠主要指的是 编译期常量 加减乘除的运算过程会被折叠 。
总结
综上所述,在使用 String的比较时,我们最好使用 equals() 方法,而 == 是内存上的比较。不过正是它的引入,才致使我们分析学习了,jvm的内存模型,常量池,常量折叠等编译器层面的知识。因祸得福,希望本节课能巩固我们的底层知识,下期再会了!
正文到此结束
热门推荐










相关文章

近期评论
-
你这基本没有更新呀,最近文章显示还是2019年的文章。不符合要求哈
-
关键词:慕云博客 链接:https://www.lilun.me 描述:分享原创文字的个人博客
-
-
-
可以提供一下源码吗
-
不是商业站,鸡娃学习笔记
-
-
-
-
听他们说很厉害的样子
Loading...
![[HBLOG]公众号](http://www.liuhaihua.cn/img/qrcode_gzh.jpg)

