你的微服务还差个容错机制

容错是每个微服务的基本特征。原因很简单:系统达到一定数量后,每天都会发生故障。造成故障的原因也是各种各样。
这就是为什么我们需要从更高的角度了解服务故障的导致因素,然后必须做出有效的决策。如果没有这些决定,就不可能达到我们所期望的容错水平。
了解系统总可用性
模型创建
实际上,我们并不需要具有真实网络的成熟应用程序来进行建模,所以借助软件 simulation ,我创建了对各种情况的模拟。
使用它,执行速度将大大提高,并且构建起来要简单得多。它使我们能够看到将系统扩展到100个节点的效果,这在实际场景中很难实现。
团队有义务维护服务的可用性
我之前所在的团队,必须要为在3种不同环境(DEV,INT,ROD)中运行的所有软件提供维护。
那时,我感到我们在任何一天都在修复服务中的问题,根本没有时间去做其他事情,例如:编码和完成我们前面的里程碑计划。这是因为,软件基础架构存在许多缺陷:没有运行状况检查,没有自动重启,我们只使用了SSH和bash终端。
有一天,我统计了下不同应用程序和组件,发现我们有将近100个组件需要存活!因此我们需要这100个组件,能够拥有99%的可用性。
那么系统的总可用性是多少?假如有一个开发人员管理这100个组件,那就会将开发人员的可用性降低到仅36%。这也就是为什么,我们在取得任何进展方面都很困难。
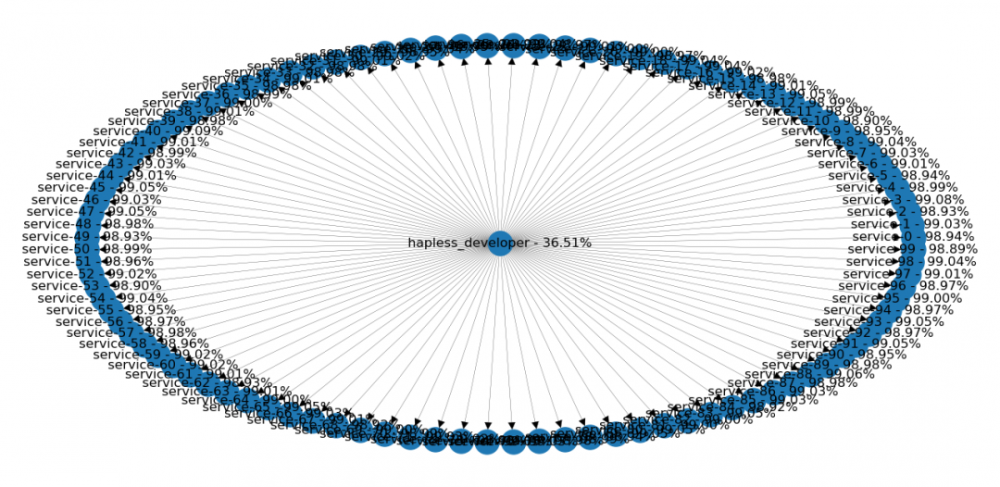
开发人员管理100个组件
串行和并行的服务关系
我们将首先看两个简单的示例,以了解每个组件之间的依赖关系将如何影响整个系统的可用性。
串行(应用程序和数据库)
在串行连接中,两个组件都需要是可用的。服务和数据库,就是这种配置的一个很好的例子。在下面的示例中,两个组件都具有95%的可用性。由于依赖关系,服务的可用性降低到90%。串行连接的总可用性始终低于其组件的最低可用性。
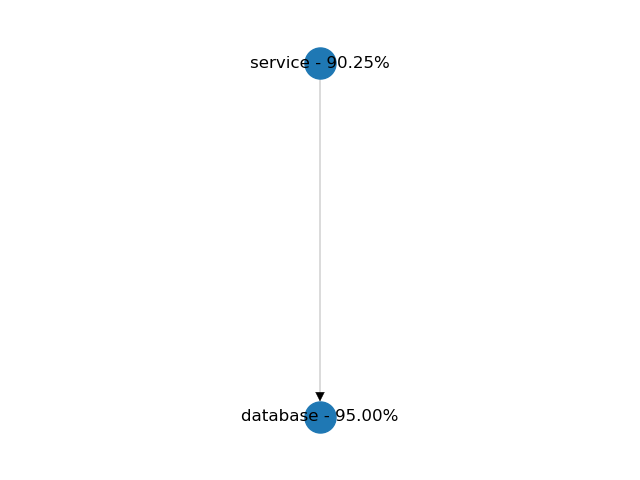
服务和数据库的可用性
并行(集群)
在并行连接中,只需要一个组件就可以提供服务。
在实际情况下,将客户端负载均衡与重试结合起来很接近这种设置。如下示例,在这里,每个组件有50%的可用性。模拟完成后,我们的总可用性应为75%。并行连接的总可用性始终高于其组件的可用性。请注意,在Python模型中,我们仅允许相同服务组件的并行连接。

2个服务并行的可用性
服务拆分:网格和星形
首先需要了解服务拆分原则。
假如我们只有10个服务。每个新添加的组件都将依赖于所有先前存在的组件。这就增加了许多抽象层,但更重要的是,许多集成点让人担心!
这些类型的系统的依赖关系图,通常看起来像一个完整的网格。在Python模型中,当我添加了几个具有99%可用性的服务,后来每个新添加的服务将取决于所有现有节点,但到最后一个所有连接的中间节点可用性却低于1%!
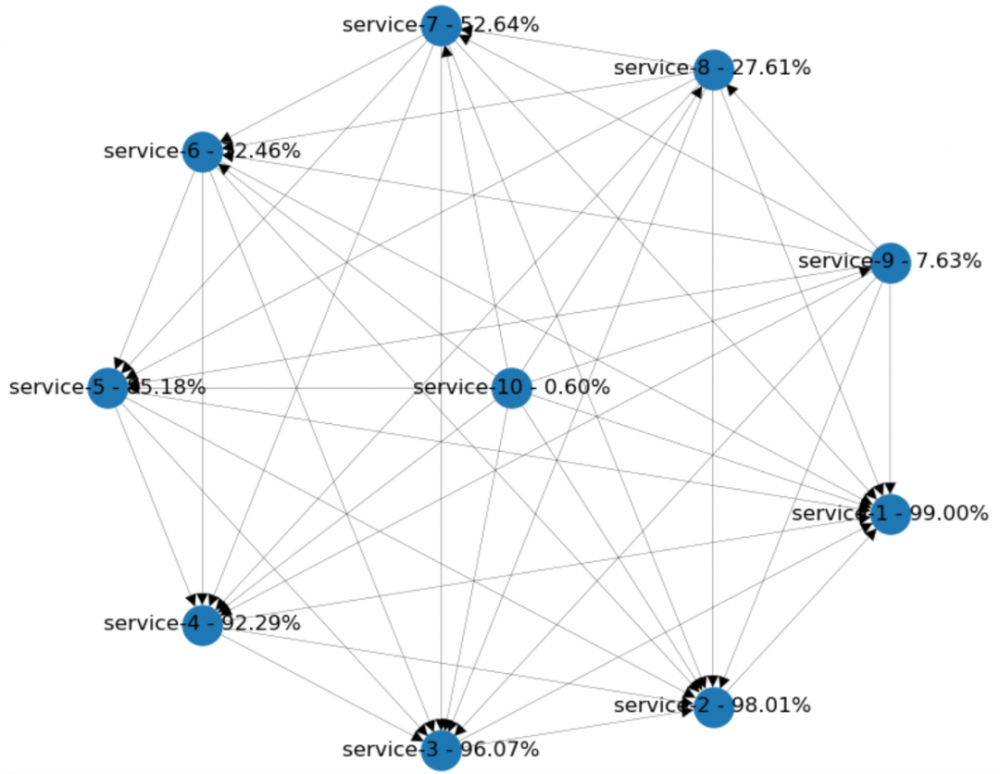
服务网格模型
我们如何改善整体状况?在现有功能的基础上重构也不错,但用网络调用封装每个依赖关系太危险了。我们的目标应该是减少集成点的数量并创建更大的服务。
在这种情况下,去掉集成调用,合并服务和重新实现某些功能会有所帮助。
向星形拓扑转变
现在,让我们看看另一个拓扑。假定系统中的每个组件都通过“代理”进行通信。这会有效地提高我们的可用性吗?
在下图中,每个服务的可用性为95%。它们中的每一个都只有一个依赖性:中间的代理集群。我们正在使用两个具有95%可用性的单独代理。你可以看到,可用性总体上有所提高。集群将代理的可用性提高了高达99.75%,并且每种服务的可用性降低很少。
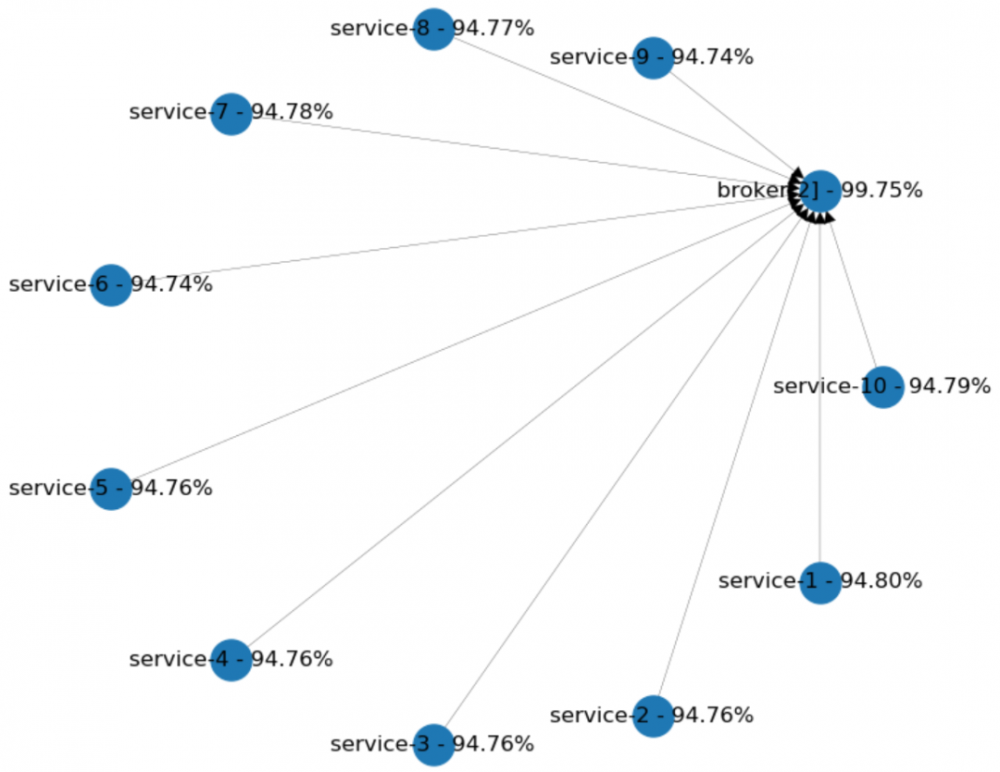
这些例子告诉我们什么?面对依赖复杂的服务,则最好使用消息队列(如:Kafka,RabbitMQ)作为通信渠道。
避免单点故障
仔细评估所选技术的配置可以帮助你避免很多麻烦。这听起来并不那么简单,并且通常需要专门的人员来为你正确配置集群。
如果你使用的是云提供商,请检查托管服务的可用性。例如,AWS还提供SQS,SNS 和托管Kafka集群。
对代理进行分区
即使你对所选的技术有信心,还是建议将集群划分到不同的分区中。当你需要更新配置时,它将为你提供帮助。例如,你可以先更新单个分区的配置,然后在出现问题时可以迅速回退。
常见的微服务模式及其对可用性的影响
CRUD服务和集合
通常,团队使用简单的CRUD服务来封装特定的数据类型。在这些情况下,上一层的业务逻辑通常需要调用多个CRUD服务,来完成数据的聚合中。通过合并业务逻辑,可以减少集成点的数量。但是,让我们看一个不太简单的场景,在这种情况下,每个单独服务的可用性单独达到95% 。
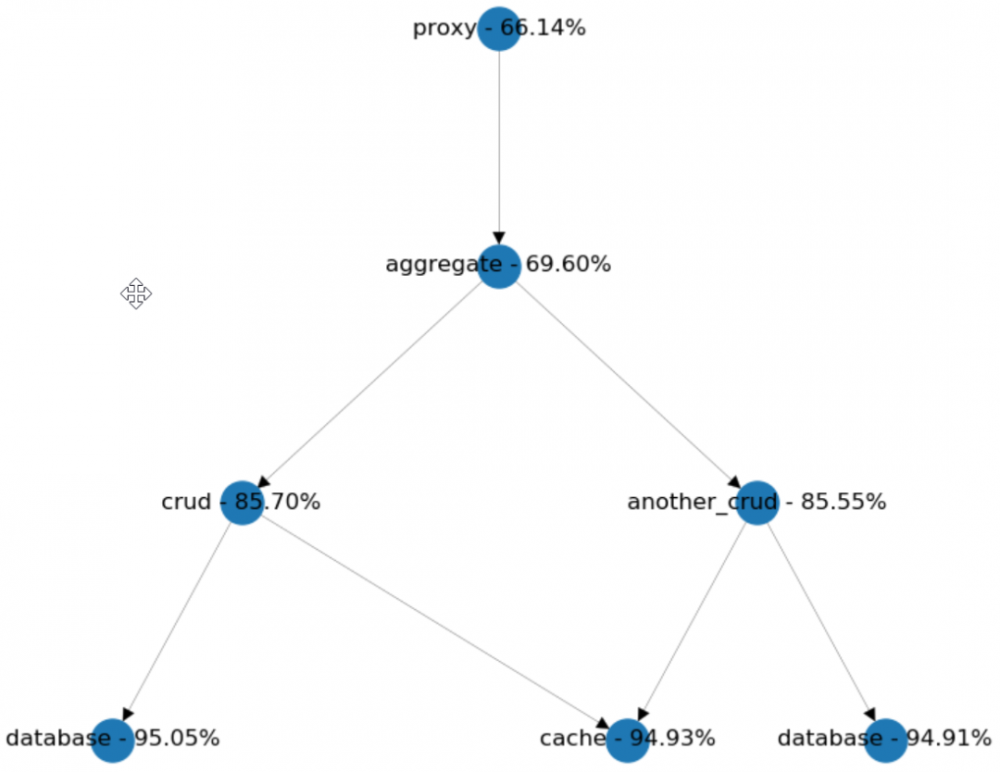
CRUD服务和集合
如上,我们有两个CRUD服务集成点。
假设我们想通过去掉another_crud到直连aggregate。从代理的角度,我们猜测可用性会增加,因此让我们做一些模拟并检查结果。
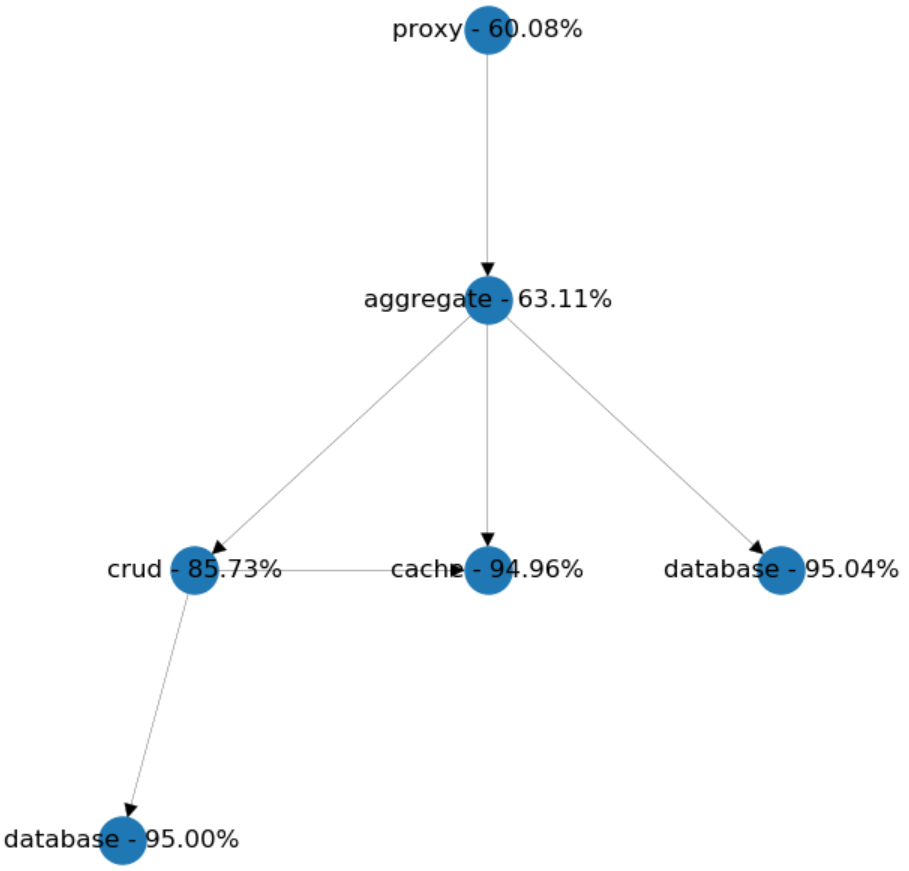
令人惊讶的是,我们失去了大约6%的可用性!为什么?原因是我们不小心将聚合的依赖从2增加到3。这使我们的系统的可用性变得更差。
因此,使我们想起更加单一的设计。
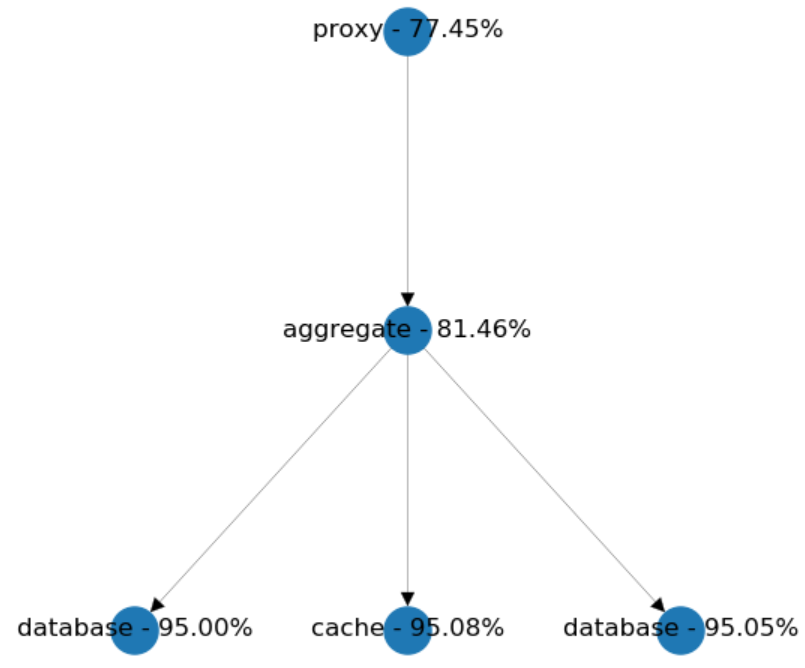
链式调用
另一个常见的模式是,服务间调用形成一条链,以简化数据聚合。在下面的示例中,从BFF中,获取用户数据和购物车信息会是不是更有优势呢?
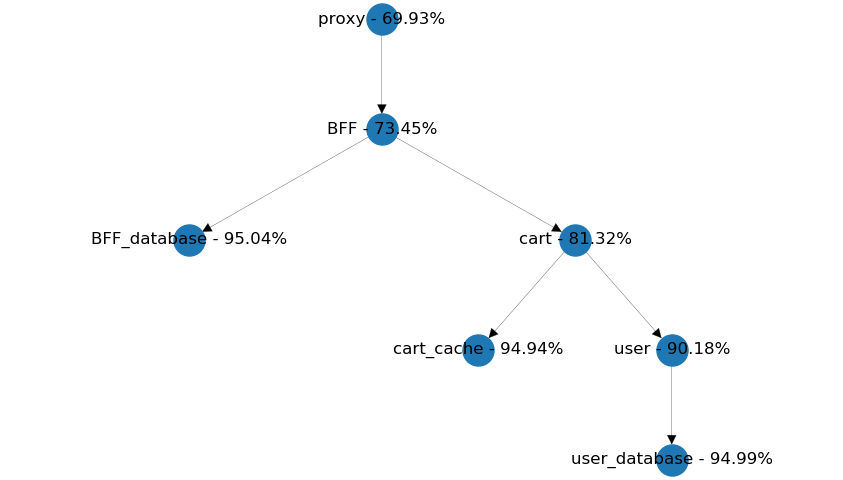
链式调用示例
因为用户数据包含在每个相关的购物车信息中,我们应该考虑购物车服务的可重用性。
另外,如果不能在一段时间内接收到用户信息,我们需要考虑哪个服务应该提供有意义的默认值。这些默认值在每个用例中都一样还是不同?
与购物车页面相比,用户页面对失败的用户请求应该更加敏感。因此,下面的设计可能比上面更可扩展。
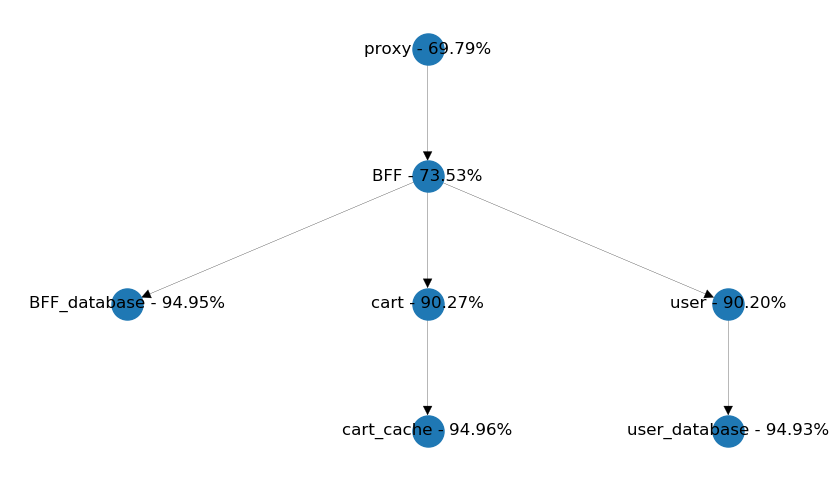
最终设计
总结
除了以上,最好了解其他与容错相关的模式。这会提高服务的具弹性。
重试
Cassandra的快速读取保护 就是一个很好的例子。此内置功能可确保如果在指定时间范围内未收到响应,则将发送其他请求。
Resilience4J实现了许多容错模式,包括重试。你甚至可以选择对重试策略以一定程度的随机性配置指数补偿。
如果你正在寻找集中式解决方案,那么最流行的代理和服务网格都已实现,例如Traefik或Istio。
补偿
最好在重试策略中添加指数补偿,以免服务因你的资源而产生混乱。例如Envoy代理提供的默认补偿算法。
默认值
每当依赖服务不可用时,你仍然可以选择从缓存中返回过时的值或某些默认值。由于大多数情况下,默认值与程序实体紧密相关,因此只能在你的应用程序代码中引入。Resilience4J提供了一些现成的实现,例如fallbackMethod其Spring注释中的属性。
断路器
断路器是最著名的稳定性模式。其中最受欢迎的实现是Hystrix。而且,几乎所有常用的服务网格,和类库都可以使用他,例如Istio,Envoy,Traefik或Resilience4J)。
超时时间
你的数据库连接,需要提供超时时间。如果你使用的是Spring Boot,则应为JDBC池配置Hikari CP,检查默认超时设置并设置一个更合理的值,因为默认值通常过高。
译者:王延飞
原文:https://dzone.com/articles/incorporating-fault-tolerance-into-your-microservi
译文:https://www.kubernetes.org.cn/7060.html
END
Kubernetes CKA线下班


正文到此结束
热门推荐









相关文章






Loading...
![[HBLOG]公众号](http://www.liuhaihua.cn/img/qrcode_gzh.jpg)

