基于 Jenkins 和 Kubernetes 的持续集成测试实践了解一下!


作者 | 刘春明, 责编 | Carol
出品 | CSDN 云计算(ID:CSDNcloud)
封图 | CSDN下载于视觉中国
目前公司为了降低机器使用成本,对所有的AWS虚拟机进行了盘点,发现利用率低的机器中,有一部分是测试团队用作Jenkins Slave的机器。 这不出我们所料,使用虚拟机作为Jenkins Slave,一定会存在很大浪费,因为测试Job运行完成后,Slave 处于空闲状态时,虚拟机资源并没有被释放掉。
除了资源利用率不高外,虚拟机作为Jenkins Slave还有其他方面的弊端, 比如资源分配不均衡 ,有的 Slave 要运行的 job 出现排队等待,而有的 Slave 可能正处于空闲状态。 另外, 扩容不方便, 使用虚拟机作为Slave,想要增加Jenkins Slave,需要手动挂载虚拟机到Jenkins Master上,并给Slave配置环境,导致管理起来非常不方便,维护起来也是比较耗时。
在2019年,运维团队搭建了Kubernetes容器云平台。为了实现公司降低机器使用成本的目标,我所在的车联网测试团队考虑将Jenkins Slave全面迁移到Kubernetes容器云平台。 主要是想提高Jenkins Slave资源利用率,并且提供比较灵活的弹性扩容能力满足越来越多的测试Job对Slave的需求。
本文就是我们的实践总结。

整体架构
我们知道Jenkins是采用的Master-Slave架构,Master负责管理Job,Slave负责运行Job。在我们公司Master搭建在一台虚拟机上,Slave则来自Kubernetes平台,每一个Slave都是Kubernetes平台中的一个Pod,Pod是Kubernetes的原子调度单位,更多Kubernetes的基础知识不做过多介绍, 在这篇文章中,大家只要记住Pod就是Jenkins Slave就行了。
基于 Kubernetes 搭建的 Jenkins Slave 集群示意图如下。
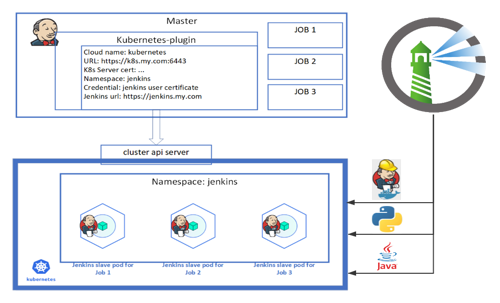
在这个架构中,Jenkins Master 负责管理测试Job,为了能够利用Kubernetes平台上的资源,需要在Master上安装Kubernetes-plugin。
Kubernetes平台负责产生Pod,用作Jenkins Slave执行Job任务。当Jenkins Master上有Job被调度时,Jenkins Master通过Kubernetes-plugin向Kubernetes平台发起请求,请Kubernetes根据Pod模板产生对应的Pod对象,Pod对象会向Jenkins Master发起JNLP请求,以便连接上Jenkins Master, 一旦连接成功,就可以在Pod上面执行Job了。
Pod中所用的容器镜像则来自Harbor,在这里,一个Pod中用到了三个镜像,分别是 Java镜像 、 Python镜像 、 JNLP镜像 。Java镜像提供Java环境,可用来进行编译、执行Java编写的测试代码,Python镜像提供Python环境,用来执行Python编写的测试代码,JNLP镜像是Jenkins官方提供的Slave镜像。
使用Kubernetes作为Jenkins Slave, 如何解决前面提到的使用虚拟机时的资源利用率低、资源分配不均的问题,并且实现Slave动态弹性扩容的呢?
首先,只有在Jenkins Master有Job被调度时,才会向Kubernetes申请Pod创建Jenkins Slave,测试Job执行完成后,所用的Slave会被Kubernetes回收。不会像虚拟机作为Slave时,有Slave闲置的情况出现,从而提高了计算资源的利用率。
其次,资源分配不均衡的主要问题在于不同测试小组之间,因为测试环境和依赖不同而不能共享Jenkins Slave。而Kubernetes平台打破了共享的障碍,只要Kubernetes集群中有计算资源,那么就可以从中申请到适合自己项目的Jenkins Slave,从而不再会发生Job排队的现象。
借助Kubernetes实现Slave动态弹性扩容就更加简单了。因为Kubernetes天生就支持弹性扩容。当监控到Kubernetes资源不够时,只需要通过运维平台向其中增加Node节点即可。对于测试工作来讲,这一步完全是透明的。

配置Jenkins Master
要想利用Kubernetes作为Jenkins Slave,第一步是在Jenkins Master上安装Kubernetes插件。安装方法很简单,用Jenkisn管理员账号登录Jenkins,在Manage Plugin页面,搜索Kubernetes,勾选并安装即可。
接下来就是在Jenkins Master上配置Kubernetes连接信息。Jenkins Master连接Kubernetes云需要配置三个关键信息: 名称 、 地 址 和 证书 。全部配置信息如下图所示。
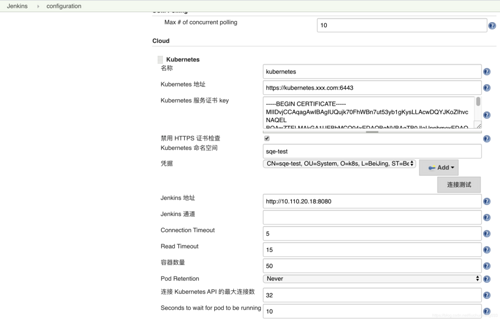
名称将会在Jenkins Pipeline中用到,配置多个Kubernetes云时,需要为每一个云都指定一个不同的名称。
Kubernetes地址指的是Kubernetes API server的地址,Jenkins Master正是通过Kubernetes plugin向这个地址发起调度Pod的请求。
Kubernetes服务证书key是用来与Kubernetes API server建立连接的,生成方法是,从Kubernetes API server的/root/.kube/config文件中,获取/root/.kube/config中certificate-authority-data的内容,并转化成base64 编码的文件即可。
# echo certificate-authority-data的内容 | base64 -D > ~/ca.crt
ca.crt的内容就是Kubernetes服务证书key。
上图中的凭据,是使用客户端的证书和key生成的pxf文件。先将/root/.kube/config中client-certificate-data和client-key-data的内容分别转化成base64 编码的文件。
# echo client-certificate-data的内容 | base64 -D > ~/client.crt # echo client-key-data的内容 | base64 -D > ~/client.crt
根据这两个文件制作pxf文件:
# openssl pkcs12 -export -out ~/cert.pfx -inkey ~/client.key -in ~/client.crt -certfile ~/ca.crt # Enter Export Password: # Verifying - Enter Export Password:
自定义一个password并牢记。
点击Add,选择类型是Cetificate,点击Upload certificate,选取前面生成cert.pfx文件,输入生成cert.pfx文件时的密码,就完成了凭据的添加。
接着再配置一下Jenkins URL和同时可以被调度的Pod数量。
配置完毕,可以点击 “Test Connection” 按钮测试是否能够连接到 Kubernetes,如果显示 Connection test successful 则表示连接成功,配置没有问题。
配置完Kubernetes插件后,在Jenkins Master上根据需要配置一些公共工具,比如我这了配置了allure,用来生成报告。这样在Jenkins Slave中用到这些工具时,就会自动安装到Jenkins Slave中了。


定制Jenkins Pipeline
配置完成Kubernetes连接信息后,就可以在测试Job的Pipeline中使用kubernetes作为agent了。与使用虚拟机作为Jenkins Slave的区别主要在于pipeline.agent部分。下面代码是完整的Jenkinsfile内容。
pipeline { agent { kubernetes{ cloud 'kubernetes-bj' //Jenkins Master上配置的Kubernetes名称 label 'SEQ-AUTOTEST-PYTHON36' //Jenkins slave的前缀 defaultContainer 'python36' // stages和post步骤中默认用到的container。如需指定其他container,可用语法 container("jnlp"){...} idleMinutes 10 //所创建的pod在job结束后的空闲生存时间 yamlFile "jenkins/jenkins_pod_template.yaml" // pod的yaml文件 } } environment { git_url = 'git@github.com:liuchunming033/seq_jenkins_template.git' git_key = 'c8615bc3-c995-40ed-92ba-d5b66' git_branch = 'master' email_list = 'liuchunming@163.com' } options { buildDiscarder(logRotator(numToKeepStr: '30')) //保存的job构建记录总数 timeout(time: 30, unit: 'MINUTES') //job超时时间 disableConcurrentBuilds() //不允许同时执行流水线 } stages { stage('拉取测试代码') { steps { git branch: "${git_branch}", credentialsId: "${git_key}", url: "${git_url}" } } stage('安装测试依赖') { steps { sh "pipenv install" } } stage('执行测试用例') { steps { sh "pipenv run py.test" } } } post { always{ container("jnlp"){ //在jnlp container中生成测试报告 allure includeProperties: false, jdk: '', report: 'jenkins-allure-report', results: [[path: 'allure-results']] } } } }
上面的Pipeline中,与本文相关的核心部分是agent.kubernetes一段,这一段描述了如何在kubernetes 平台生成Jenkins Slave。
cloud, 是Jenkins Master上配置的Kubernetes名称,用来标识当前的Pipeline使用的是哪一个Kubernetes cloud。
label, 是Jenkins Slave名称的前缀,用来区分不同的Jenkins Slave,当出现异常时,可以根据这个名称到Kubernetes cloud中进行debug。
defaultContainer, 在Jenkins Slave中我定义了是三个container,在前面有介绍。defaultContainer表示在Pipeline中的stages和post阶段,代码运行的默认container。也就是说,如果在stages和post阶段不指定container,那么代码都是默认运行在defaultContainer里面的。如果要用其他的container运行代码,则需要通过类似container(“jnlp”){…}方式来指定。
idleMinutes, 指定了Jenkins Slave上运行的测试job结束后,Jenkins Slave可以保留的时长。在这段时间内,Jenkins Slave不会被Kubernetes回收,这段时间内如果有相同label的测试Job被调度,那么可以继续使用这个空闲的Jenkins Slave。这样做的目的是,提高Jenkins Slave的利用率,避免Kubernetes进行频繁调度,因为成功产生一个Jenkins Slave还是比较耗时的。
yamlFile, 这个文件是标准的Kubernetes的Pod 模板文件。Kubernetes根据这个文件产生Pod对象,用来作为Jenkins Slave。这个文件中定义了三个容器(Container)以及调度的规则和外部存储。这个文件是利用Kubernetes作为Jenkins Slave集群的核心文件,下面将详细介绍这个文件的内容。
至此,测试Job的Pipeline就建立好了。

定制Jenkins Slave模板
使用虚拟机作为Jenkins Slave时,如果新加入一台虚拟机,我们需要对虚拟机进行初始化,主要是安装工具软件、依赖包,并连接到Jenkins Master上。使用Kubernetes cloud作为Jenkins Slave集群也是一样,要定义Jenkins Slave使用的操作系统、依赖软件和外部磁盘等信息。只不过这些信息被写在了一个Yaml文件中,这个文件是Kubernetes的Pod 对象的标准模板文件。Kubernetes会自根据这个Yaml文件,产生Pod并连接到Jenkins Master上。
这个Yaml文件内容如下:
apiVersion: v1 kind: Pod metadata: # ① 指定 Pod 将产生在Kubernetes的哪个namespace下,需要有这个namespace的权限 namespace: sqe-test spec: containers: # ② 必选,负责连接Jenkins Master,注意name一定要是jnlp - name: jnlp image: swc-harbor.nioint.com/sqe/jnlp-slave:root_user imagePullPolicy: Always # 将Jenkins的WORKSPACE(/home/jenkins/agent)挂载到jenkins-slave volumeMounts: - mountPath: /home/jenkins/agent name: jenkins-slave # ③ 可选,python36环境,已安装pipenv,负责执行python编写的测试代码 - name: python36 image: swc-harbor.nioint.com/sqe/automation_python36:v1 imagePullPolicy: Always # 通过cat命令,让这个container保持持续运行 command: - cat tty: true env: # 设置pipenv的虚拟环境路径变量 WORKON_HOME - name: WORKON_HOME value: /home/jenkins/agent/.local/share/virtualenvs/ # 创建/home/jenkins/agent目录并挂载到jenkins-slave Volume上 volumeMounts: - mountPath: /home/jenkins/agent name: jenkins-slave # 可以对Pod使用的资源进行限定,可调。尽量不要用太多,够用即可。 resources: limits: cpu: 300m memory: 500Mi # ④ 可选,Java8环境,已安装maven,负责执行Java编写的测试代码 - name: java8 image: swc-harbor.nioint.com/sqe/automation_java8:v2 imagePullPolicy: Always command: - cat tty: true volumeMounts: - mountPath: /home/jenkins/agent name: jenkins-slave # ⑤ 声明一个名称为 jenkins-slave 的 NFS Volume,多个container共享 volumes: - name: jenkins-slave nfs: path: /data/jenkins-slave-nfs/ server: 10.125.234.64 # ⑥ 指定在Kubernetes的哪些Node节点上产生Pod nodeSelector: node-app: normal node-dept: sqe
通过上面的Yaml文件,可以看到通过 spec.containers 在Pod中定义了三个容器,分别是负责连接Jenkins Master的jnlp,负责运行Python代码的python36,负责运行Java代码的java8。我们可以把Jenkins Slave比喻成豆荚,里面的容器比喻成豆荚中的豆粒,每颗豆粒具有不同的职责。

同时,还声明了一个叫作jenkins-slave 的volume,jnlp 容器将Jenkins WORKSPACE目录(/home/jenkins/agent )mount到jenkins-slave 上。同时python36和java8这两个容器也将目录/home/jenkins/agent mount到jenkins-slave 上。从而,在任何一个容器中对/home/jenkins/agent 目录的修改,在其他两个容器中都能读取到修改后的内容。挂载外部存储的主要好处是可以将测试结果、虚拟环境持久化下来,特别是将虚拟环境持久化下来之后,不用每次执行测试创建新的虚拟环境,而是复用已有的虚拟环境,加快了整个测试执行的过程。
另外,还指定了使用kubernetes的哪一个Namespace命名空间以及在哪些Node节点上产生Jenkins Slave。关于这个Yaml文件的其他细节说明,我都写在了文件的注释上,大家可以参考着理解。

定制容器镜像
前面介绍了Jenkins Slave中用到了三个容器,下面我们分别来看下这三个容器的镜像。
首先,DockerHub(https://hub.docker.com/r/jenkinsci/jnlp-slave)提供了Jenkins Slave的官方镜像,我们这里将官方镜像中的默认用户切换成root用户,否则在执行测试用例时,可能会出现权限问题。JNLP容器镜像的Dockerfile如下:
FROM jenkinsci/jnlp-slave:latest LABEL maintainer="liuchunming@163.com" USER root
Python镜像是在官方的Python3.6.4镜像中安装了pipenv。因为我们团队目前的Python项目都是用pipenv管理项目依赖的。这里说一下,pipenv是pip的升级版,它既能为你项目创建独立的虚拟环境,还能够自动维护和管理项目的依赖软件包。与pip使用requirements.txt管理依赖不同,pipenv使用Pipefile管理依赖,这里的好处不展开介绍,有兴趣的朋友可以查看一下pipenv的官方文档https://github.com/pypa/pipenv。Python镜像的Dockerfile如下:
FROM python:3.6.4 LABEL maintainer="xxx@163.com" USER root RUN pip install --upgrade pip RUN pip3 install pipenv
Java镜像是根据DockerHub上的maven镜像扩展来的。主要改动则是将公司内部使用的maven配置文件settings.xml放到镜像里面。完整的Dockerfile如下:
FROM maven:3.6.3-jdk-8 LABEL maintainer="xxx@163.com" USER root # 设置系统时区为北京时间 RUN mv /etc/localtime /etc/localtime.bak && / ln -s /usr/share/zoneinfo/Asia/Shanghai /etc/localtime && / echo "Asia/Shanghai" > /etc/timezone # 解决JVM与linux系统时间不一致问题 # 支持中文 RUN apt-get update && / apt-get install locales -y && / echo "zh_CN.UTF-8 UTF-8" > /etc/locale.gen && / locale-gen # 更新资源地址 ADD settings.xml /root/.m2/ # 安装jacococli COPY jacoco-plugin/jacococli.jar /usr/bin RUN chmod +x /usr/bin/jacococli.jar
制作完容器镜像之后,我们会将其push到公司内部的harbor上,以便kubernetes能够快速的拉取镜像。大家可以根据自己实际情况,按照项目需求制作自己的容器镜像。

执行自动化测试
通过前面的步骤,我们使用Kubernetes作为Jenkins Slave的准备工作就全部完成了。接下来就是执行测试Job了。与使用虚拟机执行测试Job相比,这一步其实完全相同。
创建一个Pipeline风格的Job,并进行如下配置:

配置完成后,点击Build就可以开始测试了。

性能优化
跟虚拟机作为Jenkins Salve不同,Kubernetes生成Jenkins Slave是个动态创建的过程,因为是动态创建,就涉及到效率问题。解决效率问题可以从两方面入手,一方面是尽量利用已有的Jenkins Slave来运行测试Job,另一方面是加快产生Jenkins Slave的效率。下面我们分别从这两方面看看具体的优化措施。
7.1 充分利用已有的Jenkins Slave
充分利用已有的Jenkins Slave,可以从两方面入手。
一方面,设置idleMinutes让Jenkins Slave在执行完测试Job后,不要被立即消毁,而是可以空闲一段时间,在这段时间内如果有测试Job启动,则可以分配到上面来执行,既提高了已有的Jenkins Slave的利用率,也避免创建Jenkins Slave耗费时间。
另一方面,在更多的测试Job流水线中,使用相同的label,这样当前面的测试Job结束后,所使用的Jenkins Slave也能被即将启动的使用相同lable的测试Job所使用。比如,测试job1使用的jenkins Slave 的lable是
DD-SEQ-AUTOTEST-PYTHON,那么当测试job1结束后,使用相同lable的测试job2启动后,既可以直接使用测试job1使用过的Jenkins Slave了。
7.2 加快Jenkins Slave的调度效率
Kubernetes上产生Jenkins Slave并加入到Jenkins Master的完整流程是:
-
Jenkins Master计算现在的负载情况;
-
Jenkins Master根据负载情况,按需通过Kubernetes Plugin向Kubernetes API server发起请求;
-
Kubernetes API server向Kubernetes集群调度Pod;
-
Pod产生后通过JNLP协议自动连接到Jenkins Master。
后三个步骤都是很快的,主要受网络影响。而第一个步骤,Jenkins Master会经过一系列算法计算之后,发现没有可用的Jenkins Slave才决定向Kubernetes API server发起请求。 这个过程在Jenkins Master的默认启动配置下是不高效的。经常会导致一个新的测试Job启动后需要等一段时间,才开始在Kubernetes上产生Pod。
因此,需求对Jenkins Master的启动项进行修改,主要涉及以下几个参数:
-Dhudson.model.LoadStatistics.clock=2000 -Dhudson.slaves.NodeProvisioner.recurrencePeriod=5000 -Dhudson.slaves.NodeProvisioner.initialDelay=0 -Dhudson.model.LoadStatistics.decay=0.5 -Dhudson.slaves.NodeProvisioner.MARGIN=50 -Dhudson.slaves.NodeProvisioner.MARGIN0=0.85
Jenkins Master每隔一段时间会计算集群负载,时间间隔由hudson.model.LoadStatistics.clock决定,默认是10秒,我们将其调整到2秒,以加快 Master计算集群负载的频率,从而更快的知道负载的变化情况。 比如原来最快需要10秒才知道目前有多少job需要被调度执行,现在只需要2秒。
当Jenkins Master计算得到集群负载后,发现没有可用的Jenkins Slave。Jenkins master会通知Kubernetes Plugin的NodeProvisioner以recurrencePeriod间隔生产Pod。因此recurrencePeriod值不能比hudson.model.LoadStatistics.clock小,否则会生成多个Jenkins slave。
initialDelay是一个延迟时间,原本用于确保让静态的Jenkins Slave和Master建立起来连接,因为我们这里是使用Kubernetes插件动态产生Jenkins slave,没有静态Jenkins Slave,所以我们将参数设置成0。
hudson.model.LoadStatistics.decay这个参数原本的意义是用于抑制评估master负载的抖动,对于评估得到的负载值有很大影响。默认decay是0.9。我们把decay设成了0.5,允许负载有比较大的波动,Jenkins Master评估的负载就是在当前尽可能真实的负载之上,评估的需要的Jenkins Slave的个数。
hudson.slaves.NodeProvisioner.MARGIN 和hudson.slaves.NodeProvisioner.MARGIN0,这两个参数使计算出来的负载做整数向上对齐,从而可能多产生一个Slave,以此来提高效率。
将上面的参数,加入到Jenkins Mater启动进程上,重启Jenkins Master即生效。
java -Dhudson.model.LoadStatistics.clock=2000 -Dxxx -jar jenkins.war

总结
本文介绍了使用Kubernetes作为持续集成测试环境的优势,并详细介绍了使用方法,对其性能也进行了优化。通过这个方式完美解决虚拟机作为Jenkins Slave的弊端。
除了自动化测试能够从Kubernetes中收益之外,在性能测试环境搭建过程中,借助Kubernetes动态弹性扩容的机制,对于大规模压测集群的创建,在效率、便捷性方面更具有明显优势。
作者介绍: 刘春明,软件测试技术布道者,十年测试老兵,CSDN博客专家,MSTC大会讲师,ArchSummit讲师,运营“明说软件测试”公众号。擅长测试框架开发、测试平台开发、持续集成、测试环境治理等,熟悉服务端测试、APP测试、Web测试和性能测试。
【END】

更多精彩推荐
☞ 一站式杀手级 AI 开发平台来袭!告别切换零散建模工具
☞ 北京四环堵车引发的智能交通大构想
☞ 拜托,别再问我什么是堆了!
☞ 北京四环堵车引发的智能交通大构想
你点的每个“在看”,我都认真当成了喜欢
正文到此结束
- 本文标签: 空间 key 开发 http Job id tag web 自动化 nfs 管理 注释 XML 操作系统 运营 Java环境 服务端 测试环境 update node UI Docker 参数 src 下载 Master Agent java 测试 https 配置 时间 Select 快的 client 文章 十年 JVM rmi 定制 git 安装 需求 Kubernetes 软件 build python IO 性能优化 目录 协议 ip Slaves 代码 App 插件 Connection ACE NIO Dockerfile 云 编译 mail 集群 GitHub 智能 list Uber Word plugin bug linux ssl maven cat SDN CTO value 总结 博客 ORM ArchSummit 2019 root jenkins 进程 API
- 版权声明: 本文为互联网转载文章,出处已在文章中说明(部分除外)。如果侵权,请联系本站长删除,谢谢。
- 本文海报: 生成海报一 生成海报二
热门推荐










相关文章

近期评论
-
你这基本没有更新呀,最近文章显示还是2019年的文章。不符合要求哈
-
关键词:慕云博客 链接:https://www.lilun.me 描述:分享原创文字的个人博客
-
-
-
可以提供一下源码吗
-
不是商业站,鸡娃学习笔记
-
-
-
-
听他们说很厉害的样子
Loading...
![[HBLOG]公众号](http://www.liuhaihua.cn/img/qrcode_gzh.jpg)

