HashMap中数组的长度为什么要设计成2次幂?
了解本文的前提是你必须对数据结构有一定的了解,明白各数据结构的优势及弊端。当然如果你已经知道了HashMap底层的数据结构是数组+链表+红黑树那就更好了。如果你还知道hashMap默认初始化的数组长度是16,且每次扩容都扩容为原长度的两倍,那么我只能说“你已经是一个合格的大佬了”。
我算是一个比较喜欢刨根问底的人,我相信“存在既有意义”,这通常使我收益良多,但是偶尔也容易陷入死角。OK 废话不多说,转入正题。
下面是jdk1.8中HashMap的部分源码
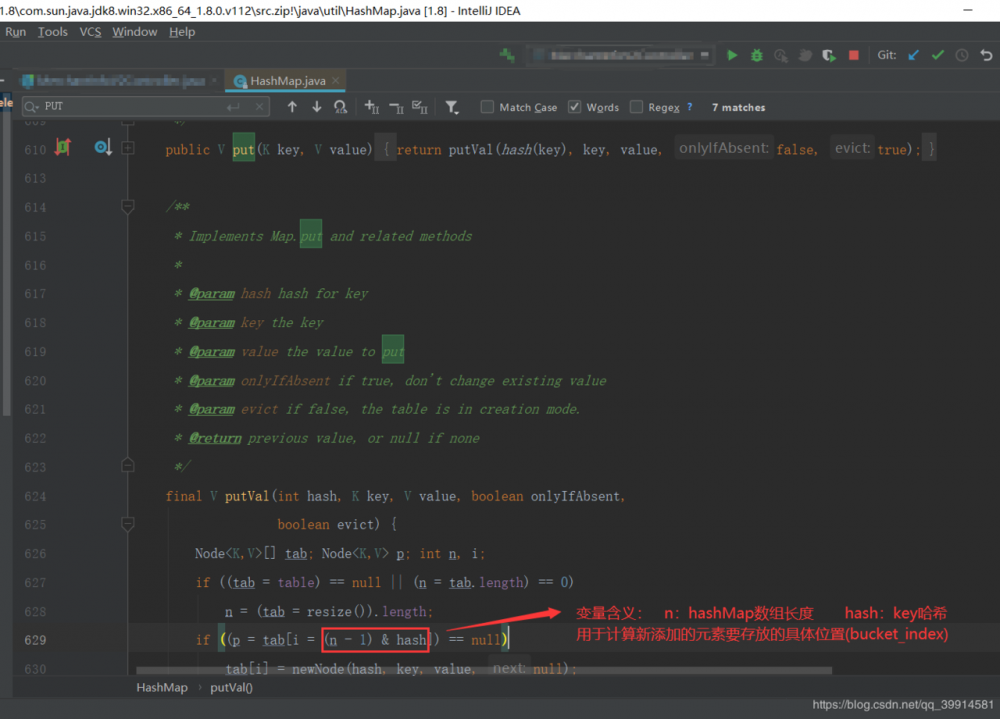
通过源码我们可以看到,HashMap新添加的元素是通过 ((数组长度 -1) & key的hashCode) 取模运算来计算槽位的(也就是新元素需要放在数组的哪个下标位置)
ps:取模运算这里就不做说明了,想要了解的小伙伴可以自行baidu
下面这个程序简单的模拟了,当数组长度分别为15、16时,添加100个元素所计算出的下标位置。这100个元素对应的hashcode分别从0-100递增
public static void main(String[] args) {
int[] length={15,16};
for(int n : length){
System.out.println("--------------"+n+"-----------------");
for(int hash=0;hash<=100;hash++){
System.out.print((hash & n-1)+"/t");
}
System.out.println();
}
}
复制代码
执行结果如下
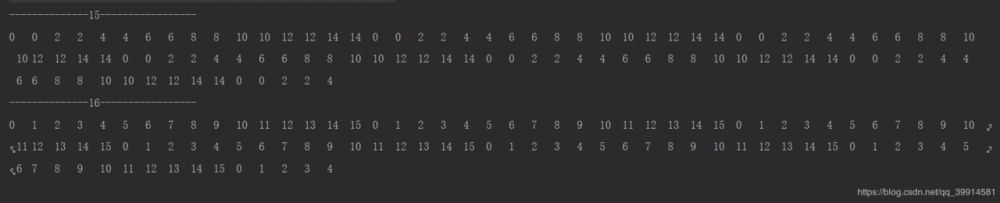
可以看出当数组的长度为16时,计算出了16个槽位并且均匀分布在数组的每一个位置,当数组长度为15时,只计算出了8个槽位,每个槽位放了一个两个节点的链表,导致了有8个槽位是空闲状态。这个问题一般被称为hash冲突,hash冲突会导致HashMap查询效率低下。我们从map中取数据时,本来可以直接通过key计算出的槽位取出对应元素就可以了,现在因为这个槽位存放的是一个链表,那么想要取数据还得遍历这个链表,在非常极端的情况下(所有元素的hashcode都是相同的),HashMap将会退化成一个链表。这样就失去了数组随机查找效率高的这样一个特性。
因此让数组的长度等于二次幂可以有效的减少hash冲突的概率。
HashMap还有许多的特性,感兴趣的话可以参考JDK自己手写一个HashMap。 ps:1.7的HashMap比较简单,如果要研究HashMap源码的话建议可以先从jdk1.7入手
最后附上之前自己实现的一个简单的HashMap blog.csdn.net/qq_39914581…
正文到此结束
热门推荐









相关文章

近期评论
-
ws0132613@gmail.comhttps://getmacos.com/gopanel/william smith
-
谢谢
-
https://www.newcmy.com/register?aff=HBVX建议您试试草莓云机场,可以流畅观看youtube和tiktok,上reddit/x也没有问题,还有各种ai优化节点。
-
-
-
想购买您这个站,我的联系方式QQ741756694微信同步 能卖联系
-
-
-
-
Loading...
![[HBLOG]公众号](https://www.liuhaihua.cn/img/qrcode_gzh.jpg)

