java 内存模型
为什么现在开发中强调JVM
1、当前的互联网开发环境有直接的关系:已经不再单独的面对传统的一台主机运行一些程序,而后在进行简单的维护,现在讲究的是: 高并发、分布式、高可用 ,对于程序的调优里面就需要去考虑JVM参数设计、JUC的使用。
【面试必问内容】Java架构师(基础能力):框架设计+通讯+多线程(JUC)+JVM+数据结构+良好的结构设计(需要大量的代码基础)
2、需要清楚内存模型、虚拟机分类、运行模式
3、不适当的 JVM运行状态 ,有可能会浪费你的 电脑性能、良好的JVM调优 ,可以 增加你电脑处理的负载 ;
4、GC处理流程以及常见的算法(JDK1.8、JDK1.9-JDK1.11)
Java程序执行流程
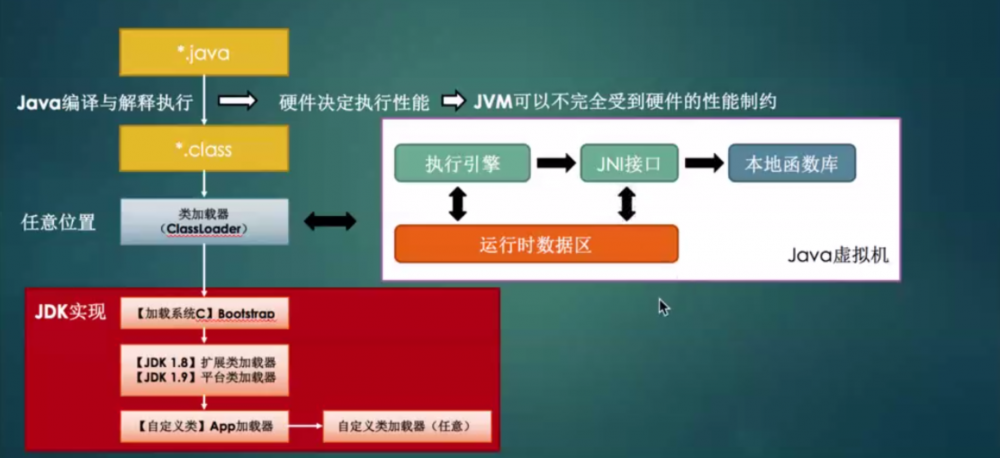
双亲加载机制:系统类由系统类加载负责,而自定义类由其他的类加载器负责。
Java运行时数据区(内存问题)
1、方法区:最重要的内存区域,多线程内存共享,保存了类的信息(名称、成员、接口、父类),反射机制是重要组成部分,动态进行类操作的实现。
2、 堆内存(Heap) :保存对象的真实信息,该内存牵扯到释放问题(GC);
3、 栈内存(Stack) :线程的私有空间,在每一次进行方法调用的时候都会存在有栈帧,采用先进后出的设计原则;
3.1、本地变量表:局部参数或形参,允许保存有32位的插槽(Solt),如果超过了32位的长度,需要开辟两个连续性的插槽(long、double)--volatile关键字问题
3.2、操作数栈:执行所有的方法计算操作
3.3、常量池引用:String类、Integer类实例
3.4、返回地址:方法执行完毕后的恢复执行点
4、程序计数器:执行指令的一个顺序编码,该区域的所占比率几乎可以忽略;
5、本地方法栈:与栈内存功能类似,区别在于是为本地方法服务的
JVM分类
Java是直接通过指针进行的程序访问,所以它没有采用句柄的形式操作,这样使得程序的性能更高。
传统意义上来讲,JVM一共分为三种(虚拟机是一个公共标准)
【SUN】从JDK1.2开始使用了HotSpot虚拟机标准(2006年开源,利用C++实现、一些JNI部分使用的是系统提供C程序实现的、JIT即时编译器);
【BEA】使用了JRockit虚拟机标准,例如WebLogic;
【IBM】开发了JVM’s(J9)虚拟机;
Oracle后来通过收购得到了:SUN与BEA,那么Oracle有了两个虚拟机标准(不可能浪费两个研发团队去干相同的事情);
HotSpot
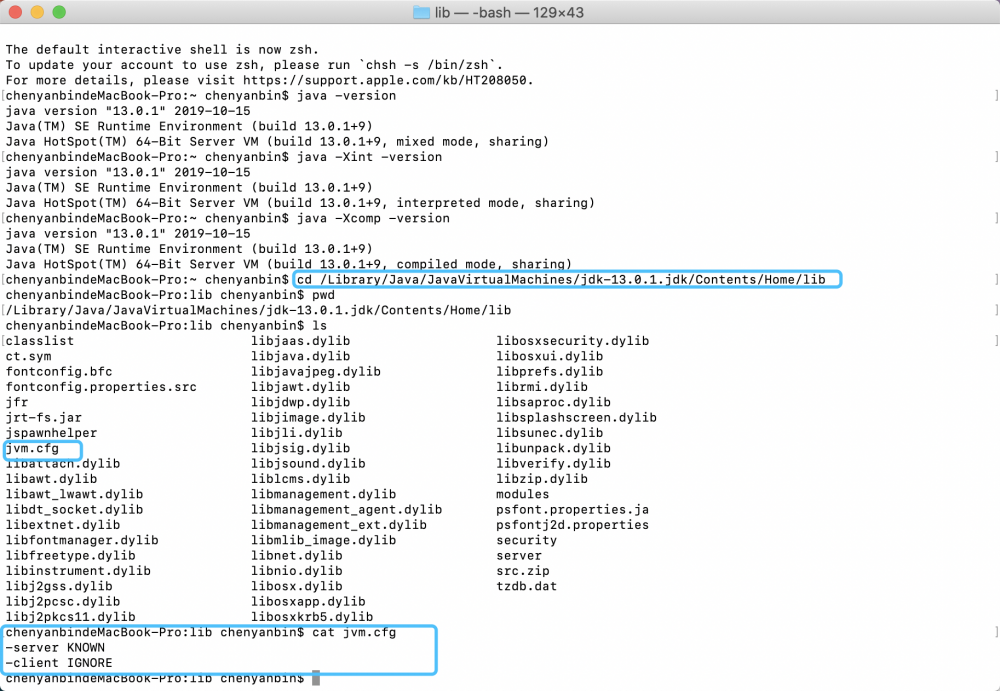
java version "13.0.1" 2019-10-15 Java(TM) SE Runtime Environment (build 13.0.1+9) Java HotSpot(TM) 64-Bit Server VM (build 13.0.1+9, mixed mode, sharing)
虚拟机提供三种处理模式:
1、 混合模式 :java -version
2、【禁用JIT】 纯解释模式 : java -Xint -version
3、 纯编译模式 : java -Xcomp -version
运行模式:
1、【client】 客户端运行 : 启动 速度 快 ,但中间程序的 执行慢 ,占用 内存小 ;
2、【server】 服务器端运行 : 启动 速度 慢 ,占用 内存多 ,执行 效率高 ;
3、修改路径:
控制台:cd /Library/Java/JavaVirtualMachines/jdk-13.0.1.jdk/Contents/Home/lib
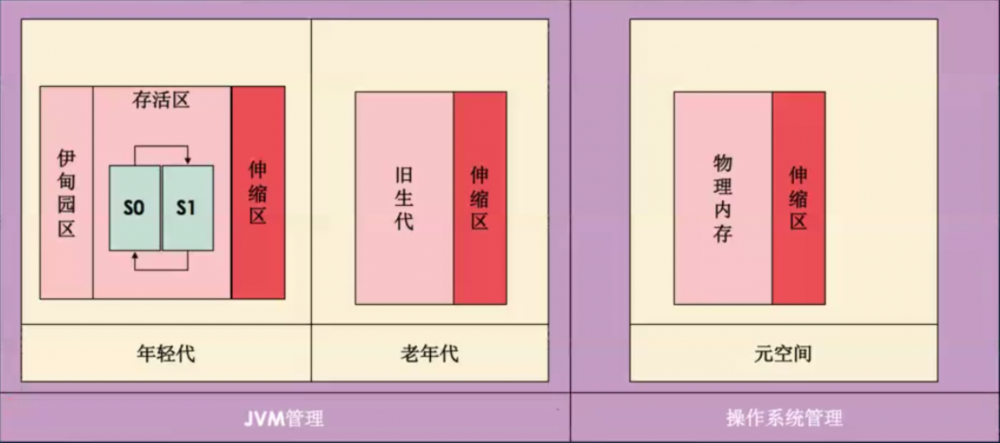
Java内存模型( 取消伸缩区 ) ( 重要 )
1、 合理的内存模型 可以 使GC的性能更加强大 ,不必太大的浪费服务器的性能,从而减少阻塞所带来的程序的性能影响。
例:你现在收拾屋子,基本上会有两类收拾方法:
方式一:简单的进行物品的码放以及打扫卫生,时间短;
方式二:房屋装修与改造,时间长。
2、Java中数据保存的内存位置:堆内存(调优、原理);
最需要强调的就是JDK1.8之后所带来的内存结构改变以及GC的策略提升;
1.8以后
JVM1.8以前
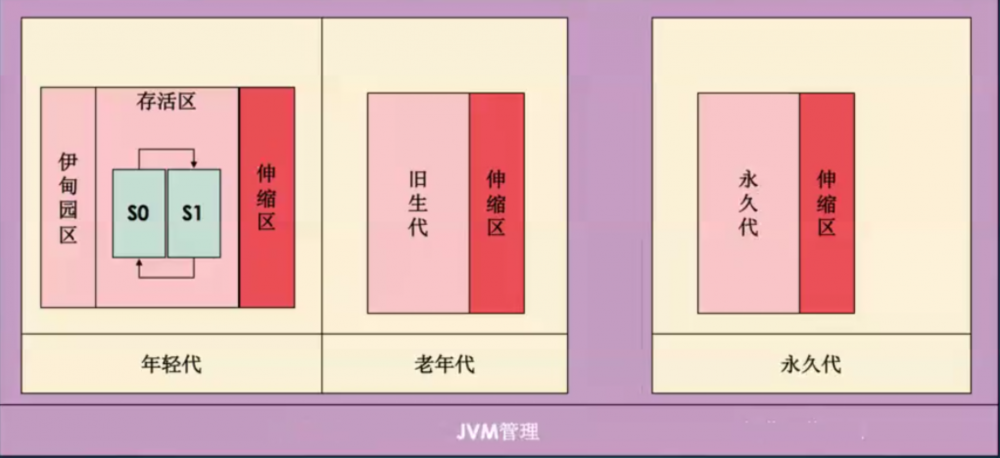
当 内存不足 的时候就 需要 进行 伸缩区的控制 ,当 内存充足 的时候就需要考虑将 伸缩区所占用的内存释放 掉(收起),一定会 造成额外 的 计算性能 的影响, 导致 程序的 整体性能下降 。既然已经确定了当前可能是高并发的访问,并且我的程序独立的在一台服务器上,那么这台服务器的资源就应该全部给我去使用。
public static void main(String[] args) {
System.out.println("MAX_MEMORY;"+byteToM(Runtime.getRuntime().maxMemory()));
System.out.println("TOTAL_MEMORY;"+byteToM(Runtime.getRuntime().totalMemory()));
}
public static double round(double num,int scale) {
return Math.round(Math.pow(10, scale)*num)/Math.pow(10, scale);
}
public static double byteToM(long num) {
return round(num/1024/1024, 2);
}
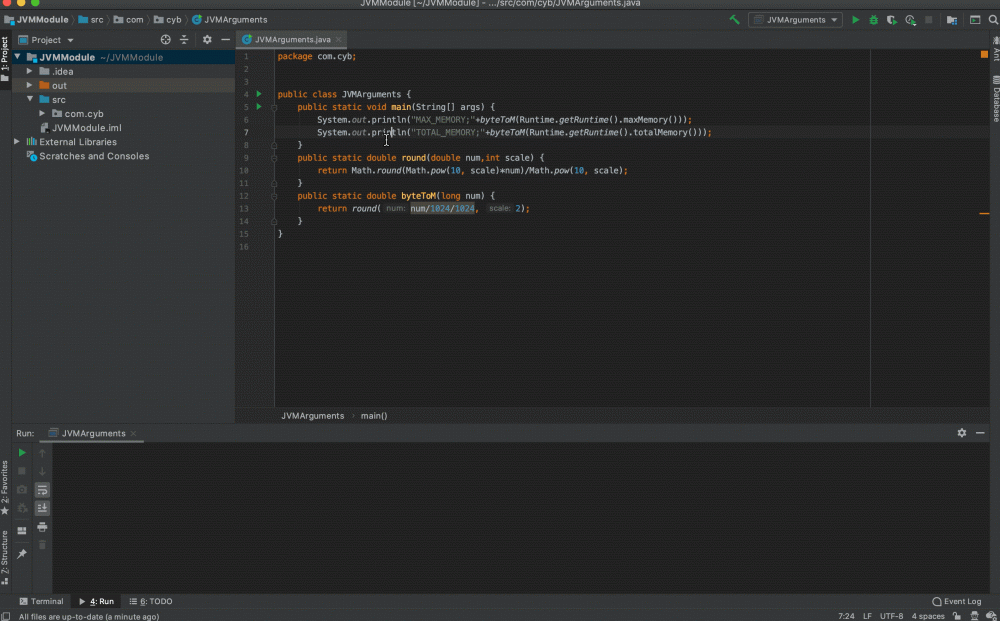
------初始打印结果
MAX_MEMORY;4096.0
TOTAL_MEMORY;258.0
我现在的电脑内存为16G,所以会发现默认的内容:
MaxMemory: 整体电脑内存的1/4
ToTalMemory:
整体电脑的1/64
伸缩区的空间 :MaxMemory - TotalMemory = 空间好大
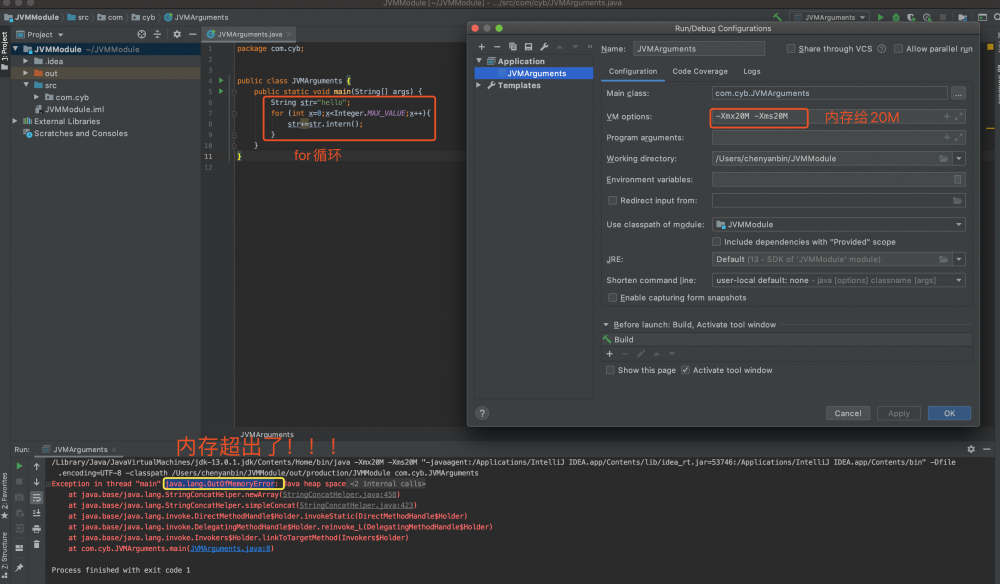
程序执行的时候设置有响应的执行参数 ( -Xmx10G -Xms10G )( 取消伸缩区 ):
-Xmx:分配的最大初始化内存
-Xms:最大的分配内存
java -Xmx大小单位 -Xms大小单位 类文件
------取消伸缩区打印结果
MAX_MEMORY;10240.0
TOTAL_MEMORY;10240.0
GC处理流程 ( 重要 )
1、对象的实例化需要依据关键字new完成,所有新对象都会在伊甸园区开辟,若果伊甸园区内存不足会发生MinorGC。
Member mem=new Member();很小,直接保存在伊甸园;
2、伊甸园区不是无限大的,所有肯定有些对象执行了N次MinorGC后还会存在,那么这些对象将进入到存活区(存活区有两个,一个负责保存存活对象,一个负责晋升,永远都有一个是空的内存);
3、如果经历过若干次的MinorGC回收处理之后发现空间依然不够使用的,那么则进行老年代的GC回收,执行了一个MajorGC(Full GC,性能很差),如果可以回收空间,则继续进行MinorGC;
4、如果MajorGC失败,则继续内存已经占用完满,则抛出OOM异常。
5、如果新创建的对象的空间占用过大将直接保存到老年代中。
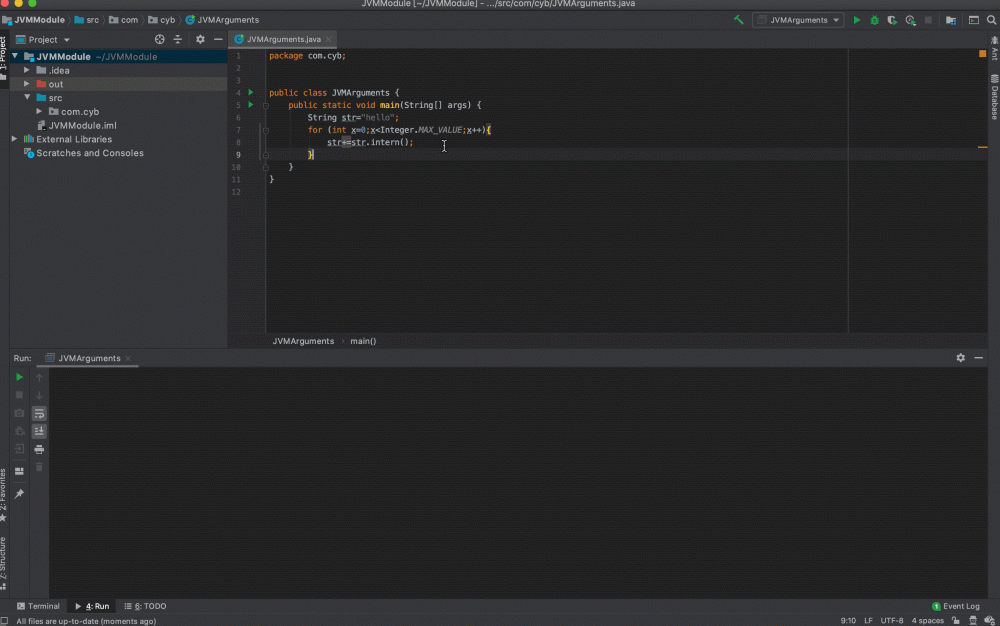
String str="hello";
for (int x=0;x<Integer.MAX_VALUE;x++){
str+=str.intern();
}
添加一些参数: -XX:+PrintGCDetails
JDK 1.8的时候默认会根据系统的不同而选择不同个GC回收策略
JDK 1.9~默认的采用GC操作就是G1
内存回收算法
1、年轻代回收算法
1.1、“复制”清理算法,将保留的对象复制到存活区之中,存活区的内容会保存到老年代之中;
1.2、伊甸园区总是会有大量的新对象产生,所以HotSpot虚拟机使用了BTP(单一CPU的时代所有对象依次保存)、TLAB(拆分不同的块,依据CPU的核心个数拆分)技术形式进行处理
2、老年代回收算法
2.1、“标记-清除”算法:先进行对象的第一次标记,在这段时间之内会暂停程序的执行(如果标记的时间长或者对象的内容过多),这个暂停的时间就会长
2.1.1、就会产生串行标记、并行标记使用问题
2.2、“标记-压缩”算法:将零散的内存空间进行整理重新集合再分配
G1算法
1、支持大内存(4-64G)、支持多CPU,减少停顿时间,可以保证并发状态下的程序的执行。
使用方法
JDK1.8:-XX:+UseG1GC JDK 11之后默认就是G1回收器,对于其他的回收算法实际上就可以忽略掉了
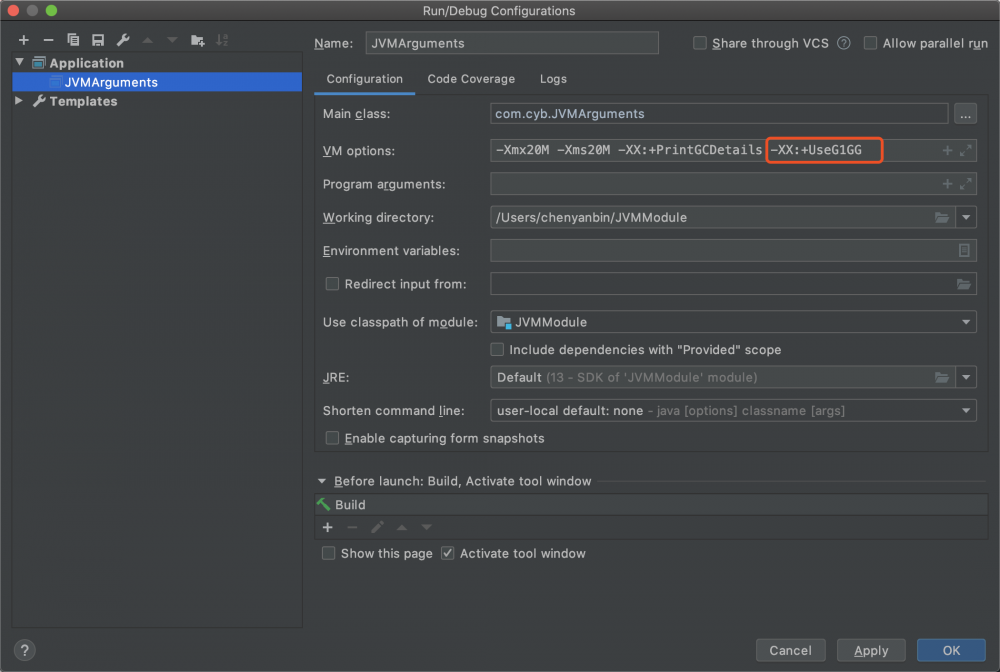
Tomcat调优
使用内存的调优
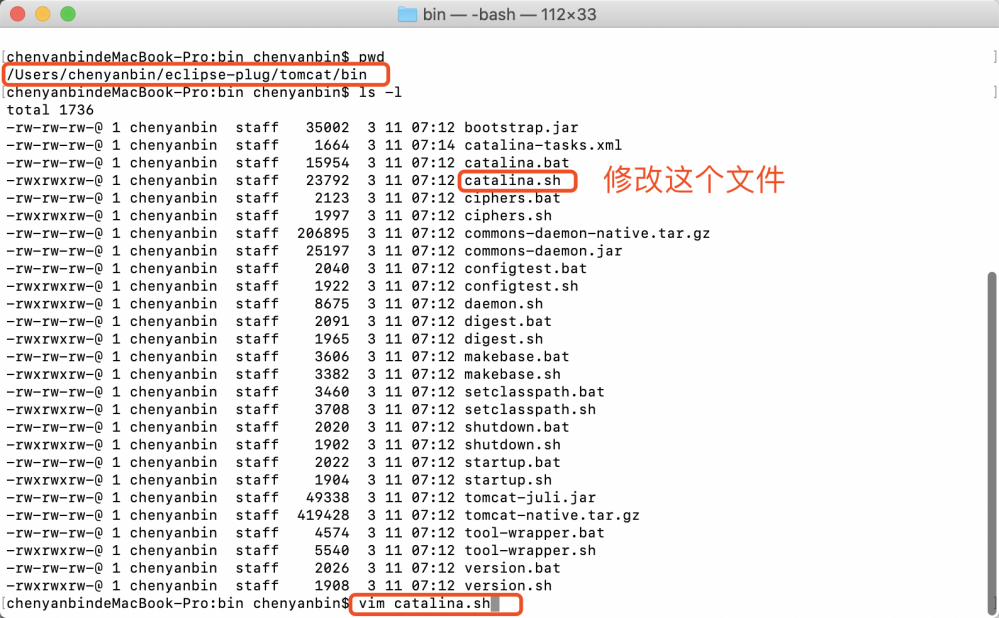
路径 :/tomcat/bin
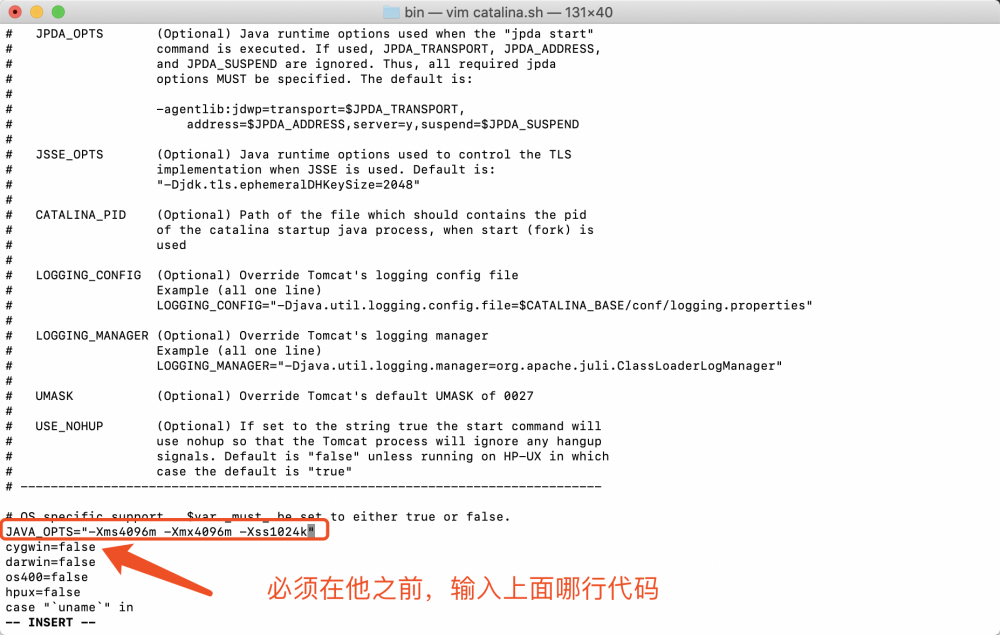
编辑 :catalina.sh
追加配置参数 : JAVA_OPTS="-Xms4096m -Xmx4096m -Xss1024k -XX:+UseG1GC"
正文到此结束
热门推荐









相关文章

近期评论
-
ws0132613@gmail.comhttps://getmacos.com/gopanel/william smith
-
谢谢
-
https://www.newcmy.com/register?aff=HBVX建议您试试草莓云机场,可以流畅观看youtube和tiktok,上reddit/x也没有问题,还有各种ai优化节点。
-
-
-
想购买您这个站,我的联系方式QQ741756694微信同步 能卖联系
-
-
-
-
Loading...
![[HBLOG]公众号](https://www.liuhaihua.cn/img/qrcode_gzh.jpg)

