如何设计实现一个地址反解析服务?
http://www.cnblogs.com/LBSer/p/4507829.html
一、什么是地址反解析
我们都知道手机定位服务,其本质是汇总各种信号得出一个经纬度坐标(x,y)(具体定位原理可以参考: LBS定位技术 、 基于朴素贝叶斯的定位算法 ),然而定位服务并未提供该坐标对应的实体地理信息,比如街道、POI等,要知道这些信息就需要使用地址反解析服务,该服务就是由经纬度信息得到结构化地址信息(图1)。

图1 地址反解析
例如lat:30.252188, lng:120.120427,地址反解析得到的结果如表1所示。
表1 地址反解析得到的结果
{ data: { province: "杭州市", city: "杭州", district: "西湖区", detail: "灵隐路-灵溪南路", lat: 30.252188, lng: 120.120427 } } 二、基本思路
一般现有的地图服务公司如高德、google、百度等都会提供地址反解析服务,当大家业务规模较小时可以选择调用他们提供的接口,但是如果业务规模较大时,再去直接调用显然不太合适。大家需要有自己的实现能力!
实现地址反解析服务有矢量和栅格两种思路。
1)矢量思路
高德、google、百度等地图服务公司有自己的地图数据,包括矢量数据(比如点、线、面等几何数据)以及矢量对应的属性信息(比如某线对应的属性是“北京朝阳望京东路”),因此他们的地址反解析思路很直接,直接根据经纬度查找附近的矢量数据(POI、道路等数据),比如查找到一条道路,然后返回道路对应的属性信息即可(图2)。具体实现思路与 地理围栏算法解析(Geo-fencing) 一文相似。

图2 矢量思路示意图
这种方式的优点是数据存储量较小。缺点是要求有详细的地图矢量数据以及对应的属性数据,而对一般公司来说很难获得。
尽管我们可以通过开源的openstreetmap拿到中国的矢量地图数据(如何获取、存储、管理、使用osm数据呢?可以参考: 利用OpenStreetMap(OSM)数据搭建一个地图服务 ),但是openstreetmap中国地区的矢量地图数据很不详细,精度也较低,完全依赖于openstreetmap的地图数据来进行地址反解析还不太靠谱。
2)栅格思路
什么是栅格思路?如图3a所示,比如将北京划分成很多栅格(也称之为瓦片),当栅格比较精细时,比如为10米*10米时,我们可以假设一个栅格内部的地址是相同的。这种假设是合理的,如图3b虚线框栅格内的两点所示,尽管该两点经纬度坐标不同,但是其地址均为“中国北京市朝阳区北苑路”。基于上述假设,我们可以事先存储各个栅格对应的地址信息。每当一个用户请求过来,首先判断该用户经纬度所对应的栅格,然后将此栅格对应的地址信息返回即可。
栅格思路的优点是很简单很直观,缺点是数据量大。 以北京为例,北京全市面积为 16,410.54平方千米,如果栅格大小为10米*10米,那么需要存储1.6亿个栅格对应的地址信息,如果放大到全国(约960万平方千米),数据量将更大。
 图3 栅格思路示意图
图3 栅格思路示意图
三、方案设计
在没有矢量数据的情况下一般应用可以采用栅格思路,因为简单直观易于上手,后期如果找到完备的矢量数据则可以借鉴矢量思路。
1)如何降低栅格方案的数据存储量?
栅格方案最大的缺点是存储量巨大,如何降低栅格方案的数据存储量呢?我们有两种思路。
a)有效栅格方案。前面讲到如果栅格为10米*10米时,仅北京就会有1.6亿个栅格。但是我们知道一般应用的用户基本是在城区进行访问,鲜有用户会在山沟沟里使用大家的服务,因此这1.6亿个栅格有大部分是不会有被访问到的(某栅格被访问到是指用户请求的经纬度落在该栅格范围内),我们将被用户访问到的栅格称之为有效栅格。事实上我们无需存储所有栅格对应的地址信息,而仅需存储有效栅格对应的地址信息即可实现我们的地址反解析服务,从而大大降低数据存储量。如图4所示,黄色栅格代表是有用户访问到的栅格,即有效栅格,有效栅格数目<<全部栅格数目。

图4 有效栅格方案(红点代表用户请求的经纬度,黄色栅格代表有效栅格)
b)自适应粒度栅格方案。之前栅格粒度是不变的,比如都是10米*10米,由于大部分栅格用户不会访问到,这样较为浪费存储空间。我们可以采用四叉树对地理空间进行划分(图5),每次划分都对空间进行四等分,直到划分出的栅格内没有用户请求点或者栅格的粒度<=10米*10米为止。在用户访问密集区域,栅格的粒度较为精细,精度较高,在鲜有用户访问区域,栅格粒度较粗,地址反解析的结果也较粗,可以发现:自适应粒度栅格数目<<均等粒度栅格数目。
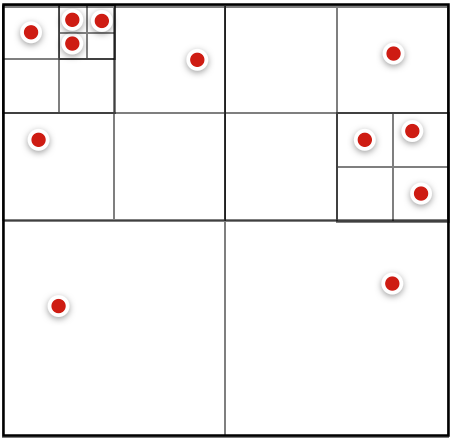
图5 自适应粒度栅格方案
从本质上讲有效栅格方案是key-value的存储结构,存储简单方便,并且更新也很简便,非常适合大数据环境。而自适应粒度栅格方案本质上是树存储结构(四叉树),涉及到树结构的节点分裂等操作,在大数据环境下实现逻辑较为复杂。简便起见我们采用有效栅格方案。
2)数据存储方式?
有效栅格方案本质是key-value的存储方式。1)这里的key指的是栅格的编号,一个用户请求过来,首先根据用户请求的经纬度判断其所在的栅格编号(key),然后查找该编号(key)对应的地址信息。栅格的编号方式有很多,可以采用geohash编码来进行编号(关于geohash可以查看 GeoHash核心原理解析 、 Geohash距离估算 ),一般来讲,geohash编码长度为8位时,其代表着20米*20米的栅格。2)value值指的是该栅格的中心点对应的地址信息。
此外还需存储该记录的时间戳,以便我们知道数据的新旧,方便更新(表2)。
表2 数据存储结构
 3)实现流程
3)实现流程
地址反解析服务实现流程分为预处理以及线上服务两个步骤(参见图6)。
a)预处理
1)利用已有用户的定位/地址反解析请求日志来确定有效栅格
用户定位/地址反解析请求会携带有经纬度信息,可以计算该经纬度对应的geohash编码(key),并查询数据库,如果没有该key则进行插入,数据量较大时可以使用mapreduce进行处理,最后将数据写入Hbase以便线上实时查询;
2)获取各个有效栅格对应的地址信息
获取每个有效栅格对应的经纬度,去请求地图服务商google、baidu、高德、搜狗等的地址反解析服务接口,获得相应结构化地址信息并进行插入。
上述两个步骤也可以合二为一,确定了有效栅格后即可请求地图服务商接口,并将geohash编码、结构化地址信息和时间戳信息插入到数据库中。
b)线上服务
对一个用户请求,首先得到经纬度,通过geohash对该经纬度编码,从而查找数据库,如果找到便直接返回,如果没找到或离上次更新时间与现在间隔超过一个月(具体时间可以动态设置)之内,则请求第三方地址反解析接口,并将更新任务放在任务队列里实现异步更新。
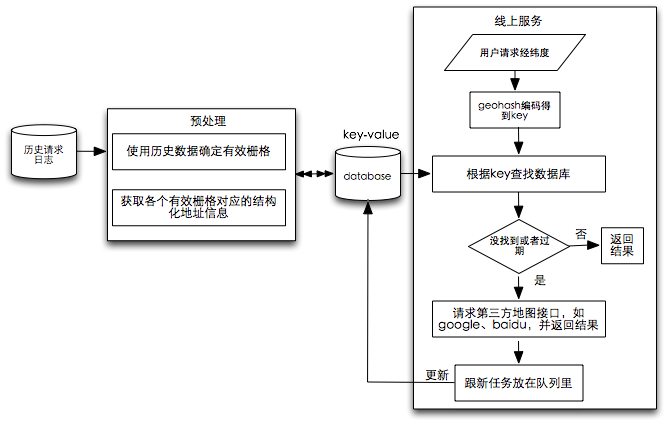
图6 栅格思路的地址反解析方案
正文到此结束
热门推荐










相关文章






Loading...
![[HBLOG]公众号](http://www.liuhaihua.cn/img/qrcode_gzh.jpg)

