Java面试宝典2020系列 MySQL篇(一)
MySQL 是一种关系型数据库,在Java企业级开发中非常常用,因为 MySQL 是开源免费的,并且方便扩展。阿里巴巴数据库系统也大量用到了 MySQL,因此它的稳定性是有保障的。MySQL是开放源代码的,因此任何人都可以在 GPL(General Public License) 的许可下下载并根据个性化的需要对其进行修改。MySQL的默认端口号是3306。
2. MySQL存储引擎
MySQL 当前默认的存储引擎是InnoDB, 并且在5.7版本所有的存储引擎中只有 InnoDB 是事务性存储引擎,也就是说只有 InnoDB 支持事务。
查看MySQL提供的所有存储引擎:
mysql> show engines; 复制代码
查看MySQL当前默认的存储引擎:
mysql> show variables like '%storage_engine%'; 复制代码
查看MySQL当前表的存储引擎:
mysql> show table status like "table_name" ; 复制代码
MyISAM和InnoDB区别:
MyISAM是MySQL的默认数据库引擎(5.5版之前)。虽然性能极佳,而且提供了大量的特性,包括全文索引、压缩、空间函数等,但MyISAM不支持事务和行级锁,而且最大的缺陷就是崩溃后无法安全恢复。不过,5.5版本之后,MySQL引入了InnoDB(事务性数据库引擎),MySQL 5.5版本后默认的存储引擎为InnoDB。
大多数时候我们使用的都是 InnoDB 存储引擎,但是在某些情况下使用 MyISAM 也是合适的比如读密集的情况下。(如果你不介意 MyISAM 崩溃恢复问题的话)。一般情况下我们选择 InnoDB 都是没有问题的,但是某些情况下你并不在乎可扩展能力和并发能力,也不需要事务支持,也不在乎崩溃后的安全恢复问题的话,选择MyISAM也是一个不错的选择。但是一般情况下,我们都是需要考虑到这些问题的。
- 是否支持行级锁 :MyISAM 只有表级锁(table-level locking),而InnoDB 支持行级锁(row-level locking)和表级锁,默认为行级锁。
- 是否支持事务和崩溃后的安全恢复 :MyISAM 强调的是性能,每次查询具有原子性,其执行速度比InnoDB类型更快,但是不提供事务支持。但是InnoDB 提供事务支持事务,外部键等高级数据库功能。 具有事务(commit)、回滚(rollback)和崩溃修复能力(crash recovery capabilities)的事务安全(transaction-safe (ACID compliant))型表。
- 是否支持外键 :MyISAM不支持,而InnoDB支持。
- 是否支持MVCC :仅 InnoDB 支持。应对高并发事务, MVCC比单纯的加锁更高效;MVCC只在 READ COMMITTED 和 REPEATABLE READ 两个隔离级别下工作;MVCC可以使用 乐观(optimistic)锁 和 悲观(pessimistic)锁来实现;各数据库中MVCC实现并不统一。
3. 字符集及校对规则
字符集指的是一种从二进制编码到某类字符符号的映射。校对规则则是指某种字符集下的排序规则。MySQL中每一种字符集都会对应一系列的校对规则。
MySQL采用的是类似继承的方式指定字符集的默认值,每个数据库以及每张数据表都有自己的默认值,他们逐层继承。比如:某个库中所有表的默认字符集将是该数据库所指定的字符集(这些表在没有指定字符集的情况下,才会采用默认字符集)。
查看MySQL字符集编码设置:
mysql> show variables like '%character%'; 复制代码
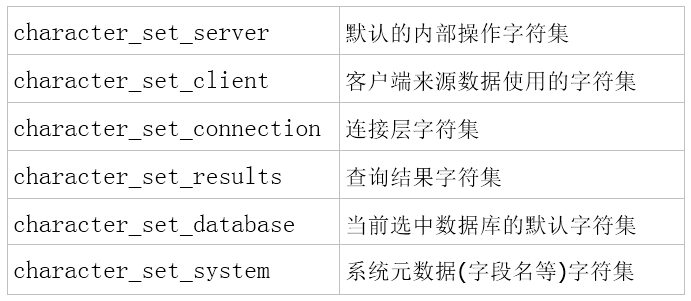
设置MySQL字符集编码:
mysql> set names 'utf8'; 复制代码
相当于同时:
- set character_set_client = utf8;
- set character_set_results = utf8;
- set character_set_connection = utf8;
修改MySQL库的字符集:
mysql> alter database database_name character set xxx; 复制代码
只修改库的字符集,影响后续创建的表的默认定义;对于已创建的表的字符集不受影响。
修改MySQL表的字符集:
mysql> alter table table_name character set xxx; 复制代码
只修改表的字符集,影响后续该表新增列的默认定义,已有列的字符集不受影响。
mysql> alter table table_name convert to character set xxx; 复制代码
同时修改表字符集和已有列字符集,并将已有数据进行字符集编码转换。
查看数据库支持的所有校对规则:
mysql> show collation; 复制代码
查看当前字符集和校对规则设置:
mysql> show variables like 'collation_%'; 复制代码
字符集校对规则特征:
- 两个不同的字符集不能有相同的校对规则;
- 每个字符集有一个默认校对规则;
- 存在校对规则命名约定:以其相关的字符集名开始,中间包括一个语言名,并且以_ci(大小写不敏感)、_cs(大小写敏感)或_bin(二元)结束。
注意:系统使用utf8字符集,若使用utf8_bin校对规则执行SQL查询时区分大小写,使用utf8_general_ci不区分大小写(默认的utf8字符集对应的校对规则是utf8_general_ci)。
4. MySQL数据索引
MySQL索引使用的数据结构主要有BTree索引 和 哈希索引 。对于哈希索引来说,底层的数据结构就是哈希表,因此在绝大多数需求为单条记录查询的时候,可以选择哈希索引,查询性能最快;其余大部分场景,建议选择BTree索引。
使用索引的原因:
- 通过创建唯一性索引,可以保证数据库表中每一行数据的唯一性;
- 可以大大加快 数据的检索速度(大大减少的检索的数据量), 这也是创建索引的最主要的原因;
- 帮助服务器避免排序和临时表;
- 将随机IO变为顺序IO;
- 可以加速表和表之间的连接,特别是在实现数据的参考完整性方面特别有意义。
使用索引的注意事项:
- 在经常需要搜索的列上,可以加快搜索的速度;
- 在经常使用在WHERE子句中的列上面创建索引,加快条件的判断速度;
- 在经常需要排序的列上创 建索引,因为索引已经排序,这样查询可以利用索引的排序,加快排序查询时间;
- 对于中到大型表索引都是非常有效的,但是特大型表的话维护开销会很大,不适合建索引;
- 在经常用在连接的列上,这 些列主要是一些外键,可以加快连接的速度;
- 避免 where 子句中对宇段施加函数,这会造成无法命中索引;
- 在使用InnoDB时使用与业务无关的自增主键作为主键,即使用逻辑主键,而不要使用业务主键;
- 删除长期未使用的索引,不用的索引的存在会造成不必要的性能损耗 MySQL 5.7 可以通过查询 sys 库的 chema_unused_indexes 视图来查询哪些索引从未被使用;
- 在使用 limit offset 查询缓慢时,可以借助索引来提高性能。
Mysql索引主要使用的两种数据结构:
1. 哈希索引
对于哈希索引来说,底层的数据结构就是哈希表,因此在绝大多数需求为单条记录查询的时候,可以选择哈希索引,查询性能最快;其余大部分场景,建议选择BTree索引。
2. BTree索引
MySQL的BTree索引使用的是B树中的B+Tree,但对于主要的两种存储引擎的实现方式是不同的。
- MyISAM : B+Tree叶节点的data域存放的是数据记录的地址。在索引检索的时候,首先按照B+Tree搜索算法搜索索引,如果指定的Key存在,则取出其 data 域的值,然后以 data 域的值为地址读取相应的数据记录。这被称为“非聚簇索引”。
- InnoDB : 其数据文件本身就是索引文件。相比MyISAM,索引文件和数据文件是分离的,其表数据文件本身就是按B+Tree组织的一个索引结构,树的叶节点data域保存了完整的数据记录。这个索引的key是数据表的主键,因此InnoDB表数据文件本身就是主索引。这被称为“聚簇索引(或聚集索引)”。而其余的索引都作为辅助索引,辅助索引的data域存储相应记录主键的值而不是地址,这也是和MyISAM不同的地方。在根据主索引搜索时,直接找到key所在的节点即可取出数据;在根据辅助索引查找时,则需要先取出主键的值,再走一遍主索引。 因此,在设计表的时候,不建议使用过长的字段作为主键,也不建议使用非单调的字段作为主键,这样会造成主索引频繁分裂 。
Mysql覆盖索引介绍:
如果一个索引包含(或者说覆盖)所有需要查询的字段的值,我们就称之为“覆盖索引”。我们知道InnoDB存储引擎中,如果不是主键索引,叶子节点存储的是主键+列值。最终还是要“回表”,也就是要通过主键再查找一次。这样就会比较慢覆盖索引就是把要查询出的列和索引是对应的,不做回表操作!
选择索引和利用索引查询的原则:
- 单行访问是很慢的。特别是在机械硬盘存储中(SSD的随机I/O要快很多,不过这一点仍然成立)。如果服务器从存储中读取一个数据块只是为了获取其中一行,那么就浪费了很多工作。最好读取的块中能包含尽可能多所需要的行。使用索引可以创建位置引,用以提升效率。
- 按顺序访问范围数据是很快的,这有两个原因。第一,顺序1/0不需要多次磁盘寻道,所以比随机I/O要快很多(特别是对机械硬盘)。第二,如果服务器能够按需要顺序读取数据,那么就不再需要额外的排序操作,并且GROUPBY查询也无须再做排序和将行按组进行聚合计算了。
- 索引覆盖查询是很快的。如果一个索引包含了查询需要的所有列,那么存储引擎就 不需要再回表查找行。这避免了大量的单行访问,而上面的第1点已经写明单行访问是很慢的。
索引为什么能提高查询速度?
MySQL的基本存储结构是页(记录都存在页里边):
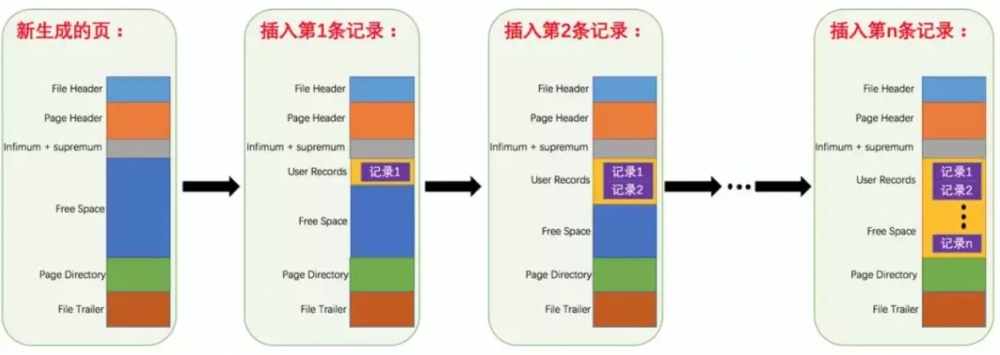
- 各个数据页可以组成一个双向链表
- 每个数据页中的记录又可以组成一个单向链表
- 每个数据页都会为存储在它里边儿的记录生成一个页目录,在通过主键查找某条记录的时候可以在页目录中使用二分法快速定位到对应的槽,然后再遍历该槽对应分组中的记录即可快速找到指定的记录
- 以其他列(非主键)作为搜索条件:只能从最小记录开始依次遍历单链表中的每条记录。 所以说,如果我们写select * from user where indexname = 'xxx'这样没有进行任何优化的sql语句,默认会这样做:
定位到记录所在的页:需要遍历双向链表,找到所在的页 从所在的页内中查找相应的记录:由于不是根据主键查询,只能遍历所在页的单链表了 很明显,在数据量很大的情况下这样查找会很慢!这样的时间复杂度为 。
索引做了些什么可以让我们查询加快速度呢? 其实就是将无序的数据变成有序(相对) :
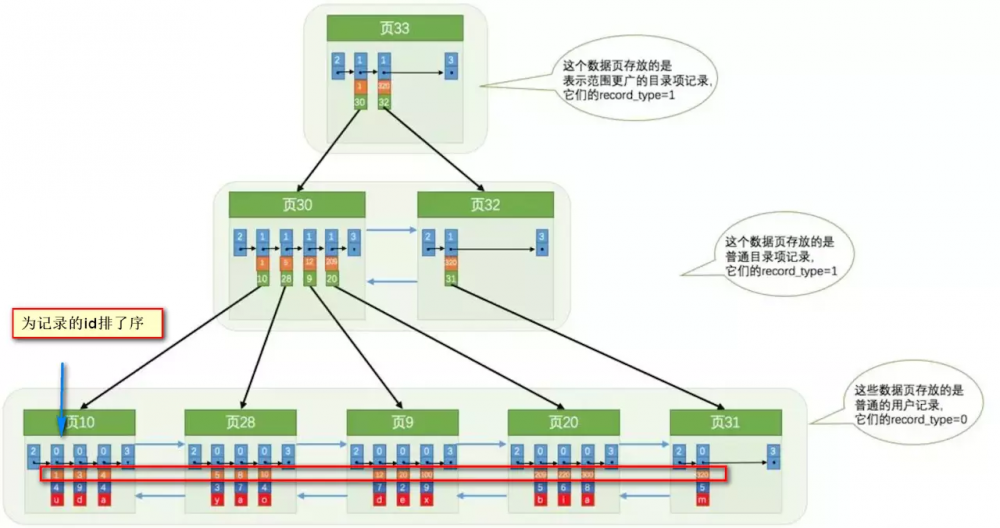
要找到id为8的记录简要步骤:
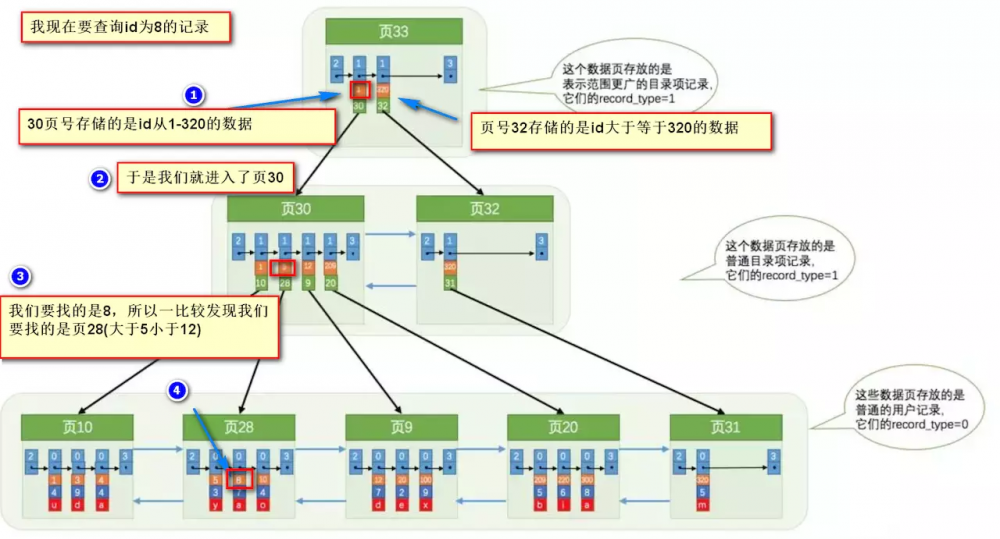
很明显的是:没有用索引我们是需要遍历双向链表来定位对应的页,现在通过 “目录” 就可以很快地定位到对应的页上了!(二分查找,时间复杂度近似为 )
其实底层结构就是B+树,B+树作为树的一种实现,能够让我们很快地查找出对应的记录。
索引的最左前缀原则:
MySQL中的索引可以以一定顺序引用多列,这种索引叫作联合索引。如User表的name和city加联合索引就是(name,city),而最左前缀原则指的是,如果查询的时候查询条件精确匹配索引的左边连续一列或几列,则此列就可以被用到。如下:
select * from user where name=xx and city=xx ; // 可以命中索引 select * from user where name=xx ; // 可以命中索引 select * from user where city=xx ; // 无法命中索引 复制代码
这里需要注意的是,查询的时候如果两个条件都用上了,但是顺序不同,如 city= xx and name =xx ,那么现在的查询引擎会自动优化为匹配联合索引的顺序,这样是能够命中索引的。
由于最左前缀原则,在创建联合索引时,索引字段的顺序需要考虑字段值去重之后的个数,较多的放前面。ORDER BY子句也遵循此规则。
5. MySQL事务机制
事务是逻辑上的一组操作,要么都执行,要么都不执行。
事务最经典也经常被拿出来说例子就是转账了。假如小明要给小红转账1000元,这个转账会涉及到两个关键操作就是:将小明的余额减少1000元,将小红的余额增加1000元。万一在这两个操作之间突然出现错误比如银行系统崩溃,导致小明余额减少而小红的余额没有增加,这样就不对了。事务就是保证这两个关键操作要么都成功,要么都要失败。
1. 事务的四大特性(ACID):
- 原子性(Atomicity) : 事务是最小的执行单位,不允许分割。事务的原子性确保动作要么全部完成,要么完全不起作用;
- 一致性(Consistency) : 执行事务前后,数据保持一致,多个事务对同一个数据读取的结果是相同的;
- 隔离性(Isolation) : 并发访问数据库时,一个用户的事务不被其他事务所干扰,各并发事务之间数据库是独立的;
- 持久性(Durability) : 一个事务被提交之后。它对数据库中数据的改变是持久的,即使数据库发生故障也不应该对其有任何影响。
2. 并发事务带来的问题:
- 脏读(Dirty read) : 当一个事务正在访问数据并且对数据进行了修改,而这种修改还没有提交到数据库中,这时另外一个事务也访问了这个数据,然后使用了这个数据。因为这个数据是还没有提交的数据,那么另外一个事务读到的这个数据是“脏数据”,依据“脏数据”所做的操作可能是不正确的。
- 丢失修改(Lost to modify) : 指在一个事务读取一个数据时,另外一个事务也访问了该数据,那么在第一个事务中修改了这个数据后,第二个事务也修改了这个数据。这样第一个事务内的修改结果就被丢失,因此称为丢失修改。 例如:事务1读取某表中的数据A=20,事务2也读取A=20,事务1修改A=A-1,事务2也修改A=A-1,最终结果A=19,事务1的修改被丢失。
- 不可重复读(Unrepeatableread) : 指在一个事务内多次读同一数据。在这个事务还没有结束时,另一个事务也访问该数据。那么,在第一个事务中的两次读数据之间,由于第二个事务的修改导致第一个事务两次读取的数据可能不太一样。这就发生了在一个事务内两次读到的数据是不一样的情况,因此称为不可重复读。
- 幻读(Phantom read) : 幻读与不可重复读类似。它发生在一个事务(T1)读取了几行数据,接着另一个并发事务(T2)插入了一些数据时。在随后的查询中,第一个事务(T1)就会发现多了一些原本不存在的记录,就好像发生了幻觉一样,所以称为幻读。
不可重复读的重点是修改比如多次读取一条记录发现其中某些列的值被修改,幻读的重点在于新增或者删除比如多次读取一条记录发现记录增多或减少了。
3. 事务的四大特性(ACID):
- READ-UNCOMMITTED(读取未提交) : 最低的隔离级别,允许读取尚未提交的数据变更,可能会导致脏读、幻读或不可重复读。
- READ-COMMITTED(读取已提交) : 允许读取并发事务已经提交的数据,可以阻止脏读,但是幻读或不可重复读仍有可能发生。
- REPEATABLE-READ(可重复读) : 对同一字段的多次读取结果都是一致的,除非数据是被本身事务自己所修改,可以阻止脏读和不可重复读,但幻读仍有可能发生。
- SERIALIZABLE(可串行化) : 最高的隔离级别,完全服从ACID的隔离级别。所有的事务依次逐个执行,这样事务之间就完全不可能产生干扰,也就是说,该级别可以防止脏读、不可重复读以及幻读。
| 隔离级别 | 脏读 | 不可重复读 | 幻影读 |
|---|---|---|---|
| READ-UNCOMMITTED | √ | √ | √ |
| READ-COMMITTED | × | √ | √ |
| REPEATABLE-READ | × | × | √ |
| SERIALIZABLE | × | × | × |
MySQL InnoDB 存储引擎的默认支持的隔离级别是 REPEATABLE-READ(可重读) 。我们可以通过 SELECT @@tx_isolation; 命令来查看,MySQL 8.0 该命令改为 SELECT @@transaction_isolation;
6. MySQL日志模块
MySQL 自带的日志模块式 binlog(归档日志) ,所有的存储引擎都可以使用,我们常用的 InnoDB 引擎还自带了一个日志模块 redo log(重做日志) 。
最开始 MySQL 并没与 InnoDB 引擎( InnoDB 引擎是其他公司以插件形式插入 MySQL 的) ,MySQL 自带的引擎是 MyISAM,但是我们知道 redo log 是 InnoDB 引擎特有的,其他存储引擎都没有,这就导致会没有 crash-safe 的能力(crash-safe 的能力即使数据库发生异常重启,之前提交的记录都不会丢失),binlog 日志只能用来归档。
并不是说只用一个日志模块不可以,只是 InnoDB 引擎就是通过 redo log 来支持事务的。那么,又会有同学问,我用两个日志模块,但是不要这么复杂行不行,为什么 redo log 要引入 prepare 预提交状态?这里我们用反证法来说明下为什么要这么做?
- 先写 redo log 直接提交,然后写 binlog ,假设写完 redo log 后,机器挂了,binlog 日志没有被写入,那么机器重启后,这台机器会通过 redo log 恢复数据,但是这个时候 bingog 并没有记录该数据,后续进行机器备份的时候,就会丢失这一条数据,同时主从同步也会丢失这一条数据。
- 先写 binlog,然后写 redo log ,假设写完了 binlog,机器异常重启了,由于没有 redo log,本机是无法恢复这一条记录的,但是 binlog 又有记录,那么和上面同样的道理,就会产生数据不一致的情况。
如果采用 redo log 两阶段提交的方式就不一样了,写完 binglog 后,然后再提交 redo log 就会防止出现上述的问题,从而保证了数据的一致性。那么问题来了,有没有一个极端的情况呢?假设 redo log 处于预提交状态,binglog 也已经写完了,这个时候发生了异常重启会怎么样呢? 这个就要依赖于 MySQL 的处理机制了,MySQL 的处理过程如下:
- 判断 redo log 是否完整,如果判断是完整的,就立即提交。
- 如果 redo log 只是预提交但不是 commit 状态,这个时候就会去判断 binlog 是否完整,如果完整就提交 redo log, 不完整就回滚事务。
这样就解决了数据一致性的问题。
7. SQL语句在MySQL中如何执行?
MySQL 主要分为 Server 层和存储引擎层:
- Server 层:主要包括连接器、查询缓存、分析器、优化器、执行器等,所有跨存储引擎的功能都在这一层实现,比如存储过程、触发器、视图,函数等,还有一个通用的日志模块 binglog 日志模块。
- 存储引擎: 主要负责数据的存储和读取,采用可以替换的插件式架构,支持 InnoDB、MyISAM、Memory 等多个存储引擎,其中 InnoDB 引擎有自有的日志模块 redolog 模块。现在最常用的存储引擎是 InnoDB,它从 MySQL 5.5.5 版本开始就被当做默认存储引擎了。
Server 层基本组件介绍:
- 连接器 :
连接器主要和身份认证和权限相关的功能相关,就好比一个级别很高的门卫一样。
主要负责用户登录数据库,进行用户的身份认证,包括校验账户密码,权限等操作,如果用户账户密码已通过,连接器会到权限表中查询该用户的所有权限,之后在这个连接里的权限逻辑判断都是会依赖此时读取到的权限数据,也就是说,后续只要这个连接不断开,即时管理员修改了该用户的权限,该用户也是不受影响的。
- 查询缓存 :
查询缓存主要用来缓存我们所执行的 SELECT 语句以及该语句的结果集。
连接建立后,执行查询语句的时候,会先查询缓存,MySQL 会先校验这个 sql 是否执行过,以 Key-Value 的形式缓存在内存中,Key 是查询预计,Value 是结果集。如果缓存 key 被命中,就会直接返回给客户端,如果没有命中,就会执行后续的操作,完成后也会把结果缓存起来,方便下一次调用。当然在真正执行缓存查询的时候还是会校验用户的权限,是否有该表的查询条件。
MySQL 查询不建议使用缓存,因为查询缓存失效在实际业务场景中可能会非常频繁,假如你对一个表更新的话,这个表上的所有的查询缓存都会被清空。对于不经常更新的数据来说,使用缓存还是可以的。
所以,一般在大多数情况下我们都是不推荐去使用查询缓存的。
MySQL 8.0 版本后删除了缓存的功能,官方也是认为该功能在实际的应用场景比较少,所以干脆直接删掉了。
- 分析器 :
MySQL 没有命中缓存,那么就会进入分析器,分析器主要是用来分析 SQL 语句是来干嘛的,分析器也会分为几步:
第一步,词法分析,一条 SQL 语句有多个字符串组成,首先要提取关键字,比如 select,提出查询的表,提出字段名,提出查询条件等等。做完这些操作后,就会进入第二步。
第二步,语法分析,主要就是判断你输入的 sql 是否正确,是否符合 MySQL 的语法。
完成这 2 步之后,MySQL 就准备开始执行了,但是如何执行,怎么执行是最好的结果呢?这个时候就需要优化器上场了。
- 优化器 :
优化器的作用就是它认为的最优的执行方案去执行(有时候可能也不是最优,这篇文章涉及对这部分知识的深入讲解),比如多个索引的时候该如何选择索引,多表查询的时候如何选择关联顺序等。
可以说,经过了优化器之后可以说这个语句具体该如何执行就已经定下来。
- 执行器 :
当选择了执行方案后,MySQL 就准备开始执行了,首先执行前会校验该用户有没有权限,如果没有权限,就会返回错误信息,如果有权限,就会去调用引擎的接口,返回接口执行的结果。
查询语句在MySQL中如何执行?
- 先检查该语句是否有权限,如果没有权限,直接返回错误信息,如果有权限,在 MySQL8.0 版本以前,会先查询缓存,以这条 sql 语句为 key 在内存中查询是否有结果,如果有直接缓存,如果没有,执行下一步。
- 通过分析器进行词法分析,提取 sql 语句的关键元素,然后判断这个 sql 语句是否有语法错误,比如关键词是否正确等等,如果检查没问题就执行下一步。
- 接下来就是优化器进行确定执行方案,优化器根据自己的优化算法进行选择执行效率最好的一个方案(优化器认为,有时候不一定最好)。那么确认了执行计划后就准备开始执行了。
- 进行权限校验,如果没有权限就会返回错误信息,如果有权限就会调用数据库引擎接口,返回引擎的执行结果。
更新语句在MySQL中如何执行?
MySQL 自带的日志模块式 binlog(归档日志) ,所有的存储引擎都可以使用,我们常用的 InnoDB 引擎还自带了一个日志模块 redo log(重做日志) ,我们就以 InnoDB 模式下来探讨这个语句的执行流程。
- 先查询到张三这一条数据,如果有缓存,也是会用到缓存。
- 然后拿到查询的语句,把字段设置修改值,然后调用引擎 API 接口,写入这一行数据,InnoDB 引擎把数据保存在内存中,同时记录 redo log,此时 redo log 进入 prepare 状态,然后告诉执行器,执行完成了,随时可以提交。
- 执行器收到通知后记录 binlog,然后调用引擎接口,提交 redo log 为提交状态。
- 更新完成。
正文到此结束
- 本文标签: 认证 企业 阿里巴巴 下载 需求 存储引擎 快的 mysql https src 数据 IO Select 服务器 同步 数据库 文章 代码 索引 插件 db client UI Action 遍历 并发 开源 备份 银行 关键词 API 一致性 组织 端口 Connection sql Atom 空间 zab 锁 java tar 删除 管理 高并发 value tab MySQL日志 安全 免费 时间 缓存 开发 目录 http NSA id key
- 版权声明: 本文为互联网转载文章,出处已在文章中说明(部分除外)。如果侵权,请联系本站长删除,谢谢。
- 本文海报: 生成海报一 生成海报二
热门推荐









相关文章

近期评论
-
ws0132613@gmail.comhttps://getmacos.com/gopanel/william smith
-
谢谢
-
https://www.newcmy.com/register?aff=HBVX建议您试试草莓云机场,可以流畅观看youtube和tiktok,上reddit/x也没有问题,还有各种ai优化节点。
-
-
-
想购买您这个站,我的联系方式QQ741756694微信同步 能卖联系
-
-
-
-
Loading...
![[HBLOG]公众号](https://www.liuhaihua.cn/img/qrcode_gzh.jpg)

