使用 ELK Stack 集中 IBM Bluemix 应用程序日志
在 IBM Bluemix 中,应用程序实例可以随时消失(比如在重新启动应用程序或者将它移动到不同主机的时候),这使得程序调试变得很困难。除了应用程序的日志消息之外,通过 Bluemix 记录事件数据也有助于故障排除,这些数据总是转瞬即逝。在试图发现服务器或应用程序中的问题时,集中应用程序日志可能很有用,因为这允许您在一个地方搜索所有日志。它还允许通过在特定的时间范围内关联日志,让您识别跨多个服务器的问题。在本教程中,我们将向您展示如何使用的 ELK Stack 组件(Elasticsearch、Logstash 和 Kibana)为持久存储日志提供一个集中的存储位置,以及如何使用这些组件来分析和可视化日志数据。
“ 将日志保存在一个地方,这样您就可以搜索它们,而且可能获得对您的应用程序的前所未知的见解。这还有助于您可视化各种指标,比如谁在访问应用程序,哪些部分被用得最多。 ”
在本教程中,我们将介绍安装和配置 ELK Stack 组件的必要步骤。还将解释如何在一个单独的 Ubuntu 服务器上安装 Elasticsearch 和 Logstash,如何创建一个 Bluemix 服务,使用它充当您的 Bluemix 应用程序的日志输出(log drain)服务,以及如何使用 nginx Web 服务器 buildpack 在 Bluemix 中部署 Kibana。最后,我们将介绍一些基础知识,让您了解如何在 Kibana 中创建一个自定义仪表板来可视化您的日志数据。
构建您的应用程序需要做的准备工作
- 一个 Ubuntu 服务器(我们使用的是版本 14.04 LTS),它具有一个对您的 Bluemix 应用程序可见的 IP 地址。(如果无权访问 Ubuntu 服务器,请按照Provision a SoftLayer server [optional]下的指令进行操作。)
- Java
sudo apt-get install openjdk-7-jre - 一个开放了端口 5000、5514 和 9200 的防火墙
- 对如何使用 CloudFoundry 命令行接口 推送 Bluemix 应用程序非常熟悉
提供一个 SoftLayer 服务器(可选)
如果您无权访问 Ubuntu 服务器,那么可以通过使用以下步骤提供一个 SoftLayer 服务器:
- 通过输入您的帐号和计费信息,在 SoftLayer 注册页面 上注册获得一个免费试用版。
- 在 Configure Your Server 部分,选择您想要的 Data Center、Hostname 和 Domain Name。对于 Operating System,可以选择 Ubuntu Linux 14.04 LTS Trusty Tahr – Minimal Install(64 位) 。
- 在配置服务器之后,在 https://control.softlayer.com/devices/ 上的设备列表中查看它。注意您的公共 IP 地址。

点击查看大图
关闭 [x]
- 要通过 SSH 进入服务器,必须确定帐号信息,您可以在 https://control.softlayer.com/devices/passwords 上找到这些信息。将您的鼠标悬停在密码上来查看它或更改它。

点击查看大图
关闭 [x]
- 现在,您知道了根用户的密码,可以通过 SSH 使用您的首选方法进入 SoftLayer 服务器。要设置一个 SSH 密钥,请参阅 SoftLayer 文档中的 SSH Keys 页面。
步骤 1. 理解 ELK Stack
在设置您自己的 ELK 堆栈之前,了解一点关于该堆栈及其组件的知识会对您有所帮助。
ELK Stack 由三个组件组成: Logstash 、 Elasticsearch 和 Kibana 。
Logstash 是一个用来管理日志的工具。它支持几乎任何类型的日志,包括系统日志、错误日志和自定义应用程序日志。它可以从许多来源接收日志,这些来源包括 syslog、消息传递(例如 rabbitmq)和 jmx,它能够以多种方式输出数据,包括电子邮件、websockets 和 Elasticsearch。
Elasticsearch 是一种全文的、实时的搜索和分析引擎,它存储通过 Logstash 索引的日志数据。它构建于 Apache Lucene 搜索引擎库之上,通过 REST 和 Java api 来公开数据。Elasticsearch 是可扩展的,构建它是为了供分布式系统使用它。
Kibana 是一个基于 Web 的图形界面,用于搜索、分析和可视化存储在 Elasticsearch 指标中的日志数据。它利用 Elasticsearch 的 REST 接口来检索数据,不仅允许用户创建他们自己的数据的定制仪表板视图,还允许他们以特殊的方式查询和过滤数据。
下图说明了如何使用 ELK Stack 组件从 IBM Bluemix 收集日志数据。
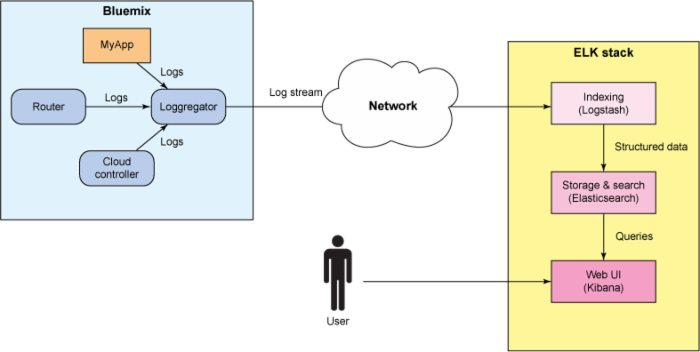
点击查看大图
关闭 [x]
步骤 2. 安装 Logstash
- 从 Elasticsearch 下载站点 (目前版本 1.4.2)的 Logstash 部分下载 logstash 核心下载 tar 文件。
- 为 Logstash 创建一个目标目录(例如,
mkdir ~/logstash)。 - 将 tar 文件提取到目标目录:
tar -xvfz logstash-1.4.2.tar.gz。
步骤 3. 安装 Elasticsearch
- 从 Elasticsearch 下载站点 (目前版本 1.4.3)的 Elasticsearch 部分下载 Elasticsearch 下载 tar 文件。
- 为 Elasticsearch 创建一个目标目录(例如,
mkdir ~/elasticsearch)。 - 将 tar 文件提取到目标目录:
tar -xvfz elasticsearch-1.3.4.tar.gz。 - 要启动 Elasticsearch 进程,可以运行
bin/elasticsearch-d。 - 要测试您的安装,可以运行
curl -X GET http://localhost:9200/。
如果安装成功,则会看到类似下面的内容:
{ "status" : 200, "name" : "Thundra", "version" : { "number" : "1.3.4", "build_hash" : "a70f3ccb52200f8f2c87e9c370c6597448eb3e45", "build_timestamp" : "2014-09-30T09:07:17Z", "build_snapshot" : false, "lucene_version" : "4.9" }, "tagline" : "You Know, for Search" }
步骤 4. 配置 Logstash
要配置 Logstash,必须创建一个包含以下三个部分的配置文件:输入、过滤器和输出。
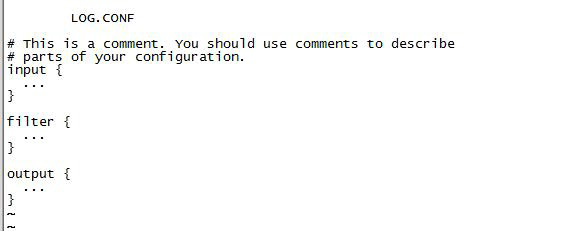
输入部分
配置文件的第一部分定义了您的输入。输入是负责吸收数据的 Logstash 模块。 产品文档 中描述了有关输入的许多选项。在本教程中,我们将配置一个 TCP 输入,因为 Bluemix 使用了 TCP 协议来传输 syslog 数据。
过滤器部分
下一节将定义过滤器。过滤器是解析原始数据并将它们转换成具有更多结构的某种格式的模块。Logstash 有许多用来过滤数据的插件,其中最有用的插件之一是 grok 。通过向常用模式分配标签,Grok 使得使用正则表达式来解析日志变得很容易。grok 模式的语法如下所示:
%{PATTERN:IDENTIFIER} Logstash 过滤器包含一系列的 grok 模式,可以将各种日志消息匹配和分配给各种标识符,这就是为日志分配结构的方式。Logstash 提供了标准模式来匹配通用组件的日志格式,这些组件包括 Apache、syslog、mysql 和 redis。但是,也可以创建新的模式来匹配任何日志文件格式。在本教程中,我们将向您展示如何创建一个名为 custom 的新文件,并将它放在 Logstash 安装目录的 patterns 目录中。这个新文件将包含用来匹配 Bluemix 日志消息的 grok 模式。通过将此模式放在一个单独的文件中,您可以在 Logstash 过滤器中使用它。
阅读: 了解有关针对 Logstash 的 grok 插件的更多信息
输出部分
配置文件的最后一部分定义了输出。输出是将已解析的数据传递给前提组件的模块。在本教程中,我们将向您展示如何配置输出,将日志数据发送到 Elasticsearch,以及如何将它们发送到控制台。
Logstash 配置
- 在 Logstash 安装目录的根目录中创建一个 log.conf 文件 ,并将以下代码复制到该文件中:
点击查看代码清单
关闭 [x]
input { tcp { port => 5000 type => syslog } } filter { grok { match => { "message" => "%{SYSLOG5424PRI}%{NONNEGINT:syslog5424_ver} +(?:%{TIMESTAMP_ISO8601:syslog5424_ts}|-) +(?:%{HOSTNAME:syslog5424_host}|-) +(?:%{NOTSPACE:app_id}|-) +(?:%{NOTSPACE:syslog5424_proc}|-) +(?:%{WORD:syslog5424_msgid}|-) +(?:%{SYSLOG5424SD:syslog5424_sd}|-|) +%{CLOUDFOUNDRYAPP:syslog5424_msg}" } add_field => { "format" => "cf" } } } output { elasticsearch { host => localhost protocol => http } stdout { codec => rubydebug } } - 现在,在 logstash-1.4.2/patterns 目录中创建一个名为 custom 的自定义 grok 模式并复制以下代码:
点击查看代码清单
关闭 [x]
CLOUDFOUNDRYAPP %{NOTSPACE:domain} - /[%{NOTSPACE:timex} %{NOTSPACE:milis}/] "%{HTTPMETHOD:httpmethod} %{PATH:path} %{NOTSPACE:protocol}" %{INT:response_code} %{INT:not_sure_todo} HTTPMETHOD (GET|PUT|POST|DELETE) - 要启动 Logstash,可以从 logstash 根目录运行以下命令:
bin/logstash agent -f log.conf
步骤 5. 在 Bluemix 中创建一个日志输出服务
- 要在您的 Bluemix 应用程序上启用日志输出,需要为您的应用程序附加一个用户提供的服务,指定您的 ELK Stack 作为 syslog 输出。如果 Bluemix 上还没有应用程序,那么可以下载一个 样例 Java 应用程序 。
- 使用 CloudFoundry Command Line Interface 工具,创建一个用户提供的服务,指定 ELK Stack 实例作为 syslog 输出。使用以下命令:
cf create-user-provided-service SERVICENAME -l syslog://HOST:PORT-
SERVICENAME是您想要对您的服务使用的名称。 -
HOST是 Logstash 服务器的 IP 地址。 -
PORT应该是 5000,如 Logstash 配置文件的输入部分中所配置的那样。
-
- 现在,将这个用户提供的服务实例附加到您想要发出以下命令来捕获其日志的应用程序:
cf bind-service APPNAMESERVICENAME-
APPNAME是您想要附加日志服务的应用程序的名称。 -
SERVICENAME是从前面的命令中获得的名称。
-
- 日志输出服务现在已被绑定到您的应用程序。需要使用此服务开始重新载入(restage)应用程序。使用
cf restage命令立即执行此操作。
现在,不但应该将 stdout 和 stderr 日志消息发送到 Logstash,还应该将有关您的应用程序的其他 Bluemix 事件发送到 Logstash。
阅读: 使用第三方日志管理服务:了解有关在 Cloud Foundry 中创建日志输出的更多信息
阅读: 用户提供服务实例:了解有关 Cloud Foundry 中用户提供的服务的更多信息
验证日志输出服务
要验证您刚才创建的日志输出服务能够正常工作,需要确保日志消息已被记录到 Logstash 控制台。通过重启 Bluemix 应用程序生成一些日志消息,然后查看 Logstash 控制台。如果一切工作正常,那么您应该会在控制台中看到如下所示的消息:
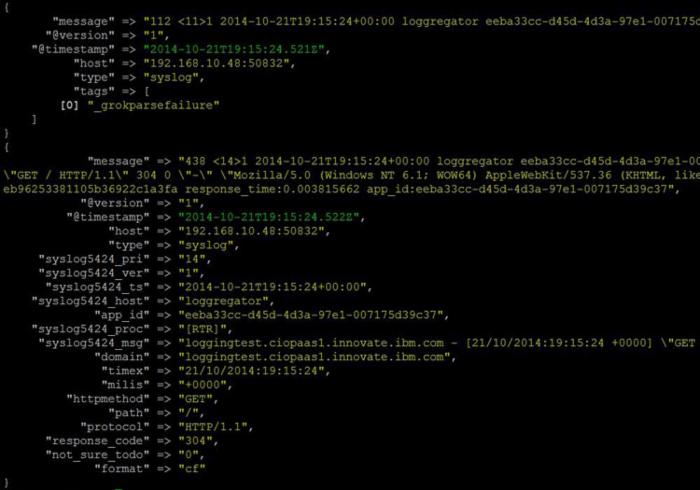
点击查看大图
关闭 [x]
步骤 6. 在 Bluemix 上部署 Kibana 3
- 从 Elasticsearch 下载站点 (当前版本 3.1.1)的 Kibana 部分,为您的操作系统下载适当的 Kibana 下载文件。
- 为 Kibana 创建一个目标目录,并将下载文件提取到该目录中。
- 从 Kibana 目标目录的根目录,在一个编辑器中打开 config.js 文件。
- 将 elasticsearch url 更改为指向您的 Elasticsearch 服务器(使用 IP_ADDRESS 的服务器 IP 地址和端口 9200):
elasticsearch: "http://IP_ADDRESS:9200"。 - 保存和关闭 config.js 文件。
- 在 Kibana 目标目录的根目录中,创建一个新的文件(manifest.yml),告诉 Bluemix 如何部署 Kibana。
- 将以下内容复制到 manifest.yml 文件中。manifest 文件表明 Bluemix 将会使用 nginx buildpack 来部署 Kibana。您可以根据需要更改
name和host属性。applications: - name: kibana-in-bluemix memory: 128M host: kibana-in-bluemix buildpack: https://github.com/cloudfoundry-community/nginx-buildpack.git
- 保存和关闭 manifest.yml 文件。
- 使用 CloudFoundry Command Line Interface 工具,通过从 Kibana 目标目录发出
cf push命令将 Kibana 部署到 Bluemix。 - 将浏览器指向 Bluemix 中新的 Kibana 应用程序,例如:http://kibana-in-bluemix.mybluemix.net。
如果正确安装了 Kibana,则会看到类似下面的内容出现在您的浏览器中。
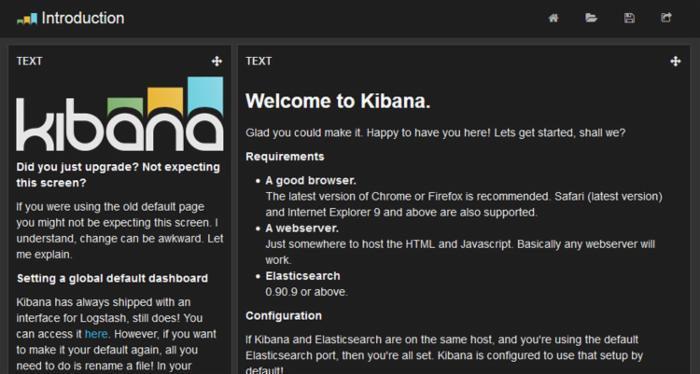
点击查看大图
关闭 [x]
步骤 7. 创建一个自定义仪表板
要创建一个新的仪表板,请执行以下操作:
- 让您的浏览器指向:
http:// IP_ADDRESS /index.html#/dashboard/file/blank.json
其中 IP_ADDRESS 是您的服务器的 IP 地址。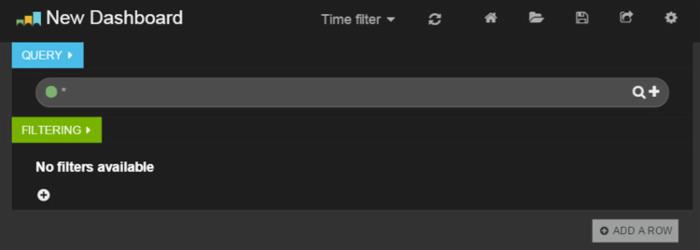
点击查看大图
关闭 [x]
- 保存仪表板,这样您就不会再失去它。单击仪表板顶部的 Save 图标。
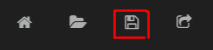
- 为仪表板提供一个惟一名称,比如 "tutorial"、"my dashboard" 或 "hello Kibana"。单击窗口外的任意地方来保存仪表板。
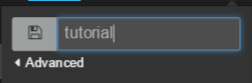
添加行和面板
- 我们要执行的第一个操作就是添加一个行,使用它作为面板的容器。单击右下角的 ADD A ROW 。接下来,为该行提供一个标题(例如,"Corn Row")和一个高度(150px)。最后,单击 Create Row 。
- 现在,您将看到已在 Rows 下列出的行。
- 要返回主仪表板,请单击 Save 。现在,您有了一个空行,让我们向它添加一个面板。单击 Add panel to empty row 。

建立一个直方图
- 现在,您必须选择想要构建哪种类型的面板。让我们创建一个日志条目的直方图。从下拉列表中选择 histogram 开始。
- 有许多的选项,但这些选项不会让您不知所措。输入一个带有默认选项的标题(例如,“A brief histogram of time”),然后看看会发生什么。如果您愿意的话,可以自由选择更多的选项。

点击查看大图
关闭 [x]
- 在准备好的时候单击 Save 。默认的直方图应该如下所示。

- 我们绘制的图形还不错,就是稍微有点宽。要配置图形设置,请单击齿轮图标。
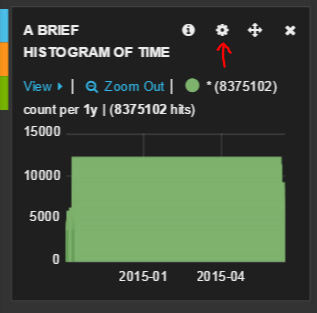
- 在 General 选项卡下,将跨度增加到 6。通过选择其他选项卡,您还可以访问更多的选项。

- 单击 Save 继续后面的操作。您应该获得类似下方的直方图:
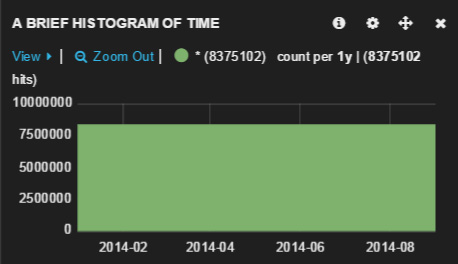
- 在继续后面的操作之前,继续前进,单击右上角的 Save 图标保存仪表板。
添加一个时间过滤器
- 该仪表板是关于正确大小的仪表板,可视化不会告诉我们太多关于数据的信息。我们想要在短时间内查看数据。我们的仪表板的顶部应该如下所示:

- 选择 Time filter ,此时会显示一个包含几个时间段的下拉菜单。在这里,我们选择了 Last 24h ,但您可以选择您认为适用于您的日志数据的任何时间范围。
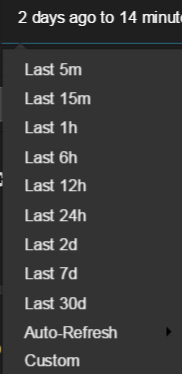
- 这导致对仪表板执行两处更改。首先,直方图看起来有所不同,因为它现在显示了不同时间跨度的数据。此外,一个新的过滤器被添加到了过滤部分。
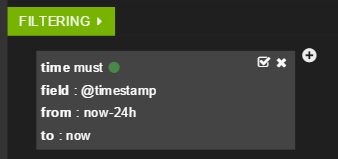
- 在继续后面的操作之前,再次保存仪表板。
添加一个表面板
- 这样,在日志到达的时候,您就可以查看时间,放入一个包含所有个人日志记录的表格。为此,首先需要添加一个新行,将面板放入该行中。再次单击 ADD A ROW ,添加一个包含您选择的名称的行。向该行添加一个新面板,但这次选择 table 。
让我们为它分配一个标题(例如,Log records),并将跨度更改为 12,但保持其他选项的默认值。然后单击 Save 。现在,向下滚动现有的直方图,您应该能够看到所有日志记录。
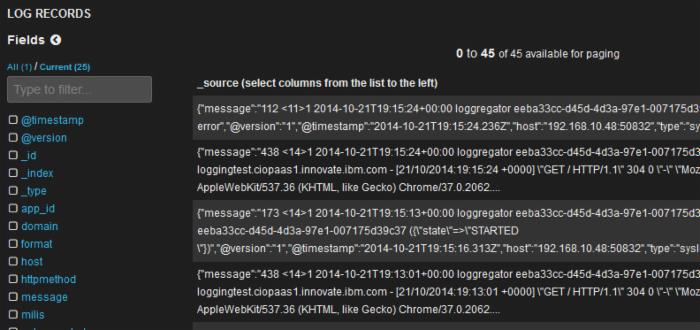
点击查看大图
关闭 [x]
- 有大量信息需要处理,但是您可以通过单击单个日志记录来查看其详细信息。
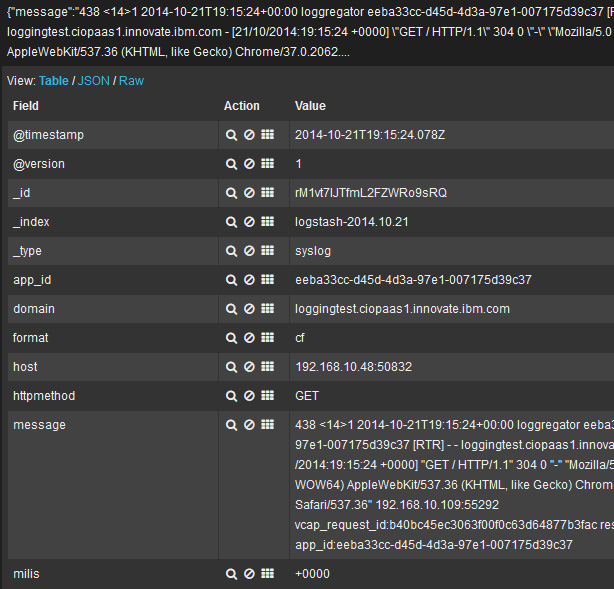
- 再次声明,在继续后面的操作之前保存仪表板。
添加过滤器
- 您已经见过一个 Time 过滤器,但让我们来尝试应用您自己的自定义过滤器。查看我们放入表中的数据,您可以看到,拥有
[App/0]的日志记录是将通过我们的 Bluemix 应用程序记录的消息,但其他记录拥有其他的标识符,比如[RTR]。RTR 记录实际上是通过 Bluemix 路由器进行记录的。
点击查看大图
关闭 [x]
- 让我们来筛选这些消息。要添加一个过滤器,请单击现有时间过滤器旁边的加号。
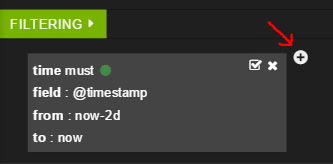
- 您可以选择使用 must 、 mustNot 或 either 。让我们使用 mustNot 筛选出包含查询 RTR 的所有消息。

- 单击 Apply 并注意那些 RTR 消失了的日志消息。在继续后面的操作之前保存仪表板。
创建查询
- 现在,您已经有了几个面板,让我们来使用一些查询。查看数据表,您会注意到,有一些 format 字段的值为
cf的记录。
- 将符合标准的记录和不符合标准的记录进行比较。首先,您需要查询 format 字段的值为
cf的应用程序。查询某个特定字段,按照模式 "field_name:value" 进行查询。找到带有绿点和类型为format:cf的查询框,如下所示: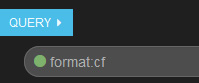
- 按下 Enter 并观察直方图的变化方式,因为只显示了格式为
cf的记录。
- 现在,添加另一个查询,选择格式不为
cf的记录。通过执行此操作,可以有效地将数据分隔成相反的类别。首先单击format:cf查询右边的加号图标,创建另一个查询。此查询的颜色将是橙色的。接下来,将NOT format:cf输入到新查询中。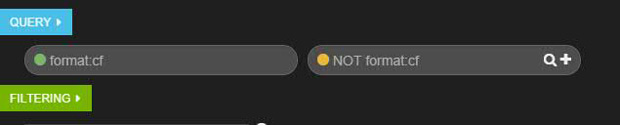
- 再次按下 Enter 来查看直方图的变化方式。

- 这是不是很有趣?现在,您了解了修改 Kibana 仪表板的基础知识,并为探索 Kibana 提供的所有功能做好了准备。尝试应用一些查询,添加不同类型的面板,并调整面板提供的许多选项。
阅读: Kibana 简介:了解关于 Kibana 的更多信息
阅读: Kibana 3 文档:访问 Kibana 3 上的 Elasticsearch 官方文档
阅读: Kibana 3: milestone 4:从关于 3.4 版本的 Elasticsearch 博客中了解关于 Kibana 3 特性的更多信息
生成环境注意事项
我们目前为止介绍的所有内容都很有用,在开始使用 ELK Stack 为您的 IBM Bluemix 应用程序 汇集日志时,需要掌握这些知识。不过,当您在生产环境中使用此解决方案时,仍有一些问题需要解决,这些问题的详细介绍已超出了本文的讨论范围。这些问题可以确保您数据的安全和删除过时的日志。
安全性
如果您在生产环境中使用 ELK Stack,则应该采用适当的凭证,使用最佳实践来运行 Logstash Elasticsearch 作为守护进程服务。
要保护 Kibana,可以配置您的 Web 服务器来限制用户访问,或者可以探索第三方产品,比如 https://github.com/christian-marie/kibana3_auth 。此外,可以参考以下两个参考资料,获得关于安全性的更多信息。
阅读: 生成部署:了解关于保障 Elasticsearch 安全的更多信息。
阅读: Logstash 的官方文档包含有关安全性的其他信息和各种配置选项。
删除旧的记录(可选)
现在,您已经将所有日志通过 Logstash 集中到了 Elasticsearch 中,如何删除已经不再有用、只会占用索引中的空间和内存的旧记录呢?处理这个问题的一个方法是使用一个名为 Curator 的 Elasticsearch 工具,它有助于您使用简单的命令来管理时间序列指数,这些命令包括 delete 、 optimize 、 close 、 snapshot 和 alias 。
下面的指令可以帮助您开始了解 Curator,创建一个将处理清除工作的 cron 作业。
- 安装 pip:
sudo apt-get install python-pip。 - 使用 pip 安装 Curator:
sudo pip install elasticsearch-curator。 - 编辑 crontab:
crontab -e。 - 创建两个 cron 作业,一个用于删除超过 120 天的指数:
20 0 * * * /usr/local/bin/curator --host 127.0.0.1 delete --older-than 120
另一个作业用于关闭超过 90 天的指数:
20 0 * * * /usr/local/bin/curator --host 127.0.0.1 close --older-than 90
结束语
IBM Bluemix 使开发人员能够快速构建、部署和管理云应用程序,并搭建一个由可用服务和运行时框架组成的不断成长的生态系统。与此同时,Bluemix 要求开发人员重新思考他们开发应用程序的方式,包括如何处理日志文件。通过利用 Bluemix 的日志输出功能,ELK Stack 使得开发人员能够捕获、转换、分析和可视化应用程序的日志,最终使他们能够从应用程序中获得新的洞察。此外,ELK Stack 并不局限于 Bluemix 应用程序;它可以接收来自各种来源的日志数据,支持开发一个堆栈,集成来自整个企业的应用程序产品组合的数据。
正文到此结束
- 本文标签: IDE operating system value ssh 测试 安全 redis 空间 key java 定制 js 密钥 TCP json Ubuntu 协议 https 搜索引擎 数据 时间 实例 企业 目录 服务器 git 标题 调试 代码 DOM 开发 云 站点 ip cat UI GitHub 解析 操作系统 mysql Nginx 端口 产品 配置 API HTML REST 正则表达式 web IBM 进程 安装 管理 App 插件 linux apache tab tar sql
- 版权声明: 本文为互联网转载文章,出处已在文章中说明(部分除外)。如果侵权,请联系本站长删除,谢谢。
- 本文海报: 生成海报一 生成海报二
热门推荐










相关文章






Loading...
![[HBLOG]公众号](http://www.liuhaihua.cn/img/qrcode_gzh.jpg)

