【数据分析 R语言实战】学习笔记 第六章 参数估计与R实现(下)
6.3两正态总体的区间估计
(1)两个总体的方差已知

在R中编写计算置信区间的函数twosample.ci()如下,输入参数为样本x, y,置信度α和两个样本的标准差。
> twosample.ci=function(x,y,alpha,sigma1,sigma2){ + n1=length(x);n2=length(y) + xbar=mean(x)-mean(y) + z=qnorm(1-alpha/2)*sqrt(sigma1^2/n1+sigma2^2/n2) + c(xbar-z,xbar+z) + } 前面介绍的Z检验函数z.test()可以在两总体方差已知的情况下,计算两总体均值差的置信区间,分别用参数sigma.x和sigma.y来说明已知的标准差数值即可。
例:
Bamberger's是一家为社区提供大众性商品的零传商店,为了努力维持商店的良好声誉,公司实施了将营业时间延长至夜间的计划。以Bamberger's延长营业时间前后27个典型周的销售额数据为例(以万元为单位),计算这两个样本均值差的区间估计,从而可以看出计划实施后的效果。首先查看数据的基本类型,并绘制直方图对比。
> sales=read.table("D:/Program Files/RStudio/sales.txt",header=T) > head(sales) prior post 1 67.90 86.10 2 76.12 71.13 3 68.64 116.25 4 74.94 102.60 5 63.32 97.51 6 50.43 65.39 > attach(sales) > par(mfrow=c(1,2)) > hist(prior) #分别绘制计划前后销售额的直方图 > hist(post) 
从直方图可以看出,销售额样本大致呈正态分布,假设已知计划实施前后的总体标准差分别为8和12,调用上面写好的函数,计算样本均值差在置信水平为1-a下的置信区间
> twosample.ci(post,prior,alpha=0.05,8,12) [1] 19.10298 29.98295 > z.test(post,prior,sigma.x=8,sigma.y=12)$conf.int [1] 19.10298 29.98295 attr(,"conf.level") [1] 0.95
区间估计的结果是,Bamberger's公司延长营业时间后周营业额明显增加,增加额的范围是[19.10, 29.98]
(2)两个总体的方差未知但相等
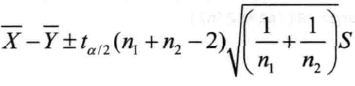
正如计算单.正态总体均值的置信区间,R中的函数t.test()还可以用来求两总体均值差的置信区间,山于总体方差相等,需要将其中的参数var.equal设为TRUE。
> t.test(post,prior,var.equal=TRUE)$conf.int [1] 18.66541 30.42051 attr(,"conf.level") [1] 0.95
由计算结果同样可以得到结论:Barnberger's公司延长营业时间后周营业额明显增加,在0.95的置信水平下,营业额增加的置信区间是[18.67,30.42]
(3) 两个总体的方差未知且不等
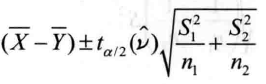
R中也没有直接的函数可用,仍需要手动写出一个函数twasarnple.ci2()
> twosample.ci2=function(x,y,alpha){ + n1=length(x);n2=length(y) + xbar=mean(x)-mean(y) + S1=var(x);S2=var(y) + nu=(S1/n1+S2/n2)^2/(S1^2/n1^2/(n1-1)+S2^2/n2^2/(n2-1)) + z=qt(1-alpha/2,nu)*sqrt(S1/n1+S2/n2) + c(xbar-z,xbar+z) + } 在实际分析中,两总体的方差未知且不等是最常见的情况,在Bamberger's公司的案例中如果延长营业时间前后的方差未知并且不相等,就要通过上面编写的函数计算样本均位差的置信区间:
> twosample.ci2(post,prior,0.05) [1] 18.63821 30.44771
相比之前,营业时间延长后的样本均值明显增加,两样本均值差的置信区问为[18.64, 30.45]由于方差未知,在做区间估计时可利用的信息更少,因此在相同置信水平下,这时估计得到的置信区间相对更宽一些。
6.3.2 两方差比的区间估计
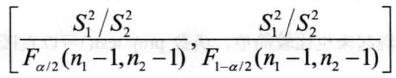
方差比的区问估计与方差的假设检验密不可分,所以R中的函数var.test()可以用来直接计算两正态总体方拾比的置信区间,调用格式如下:
var.test(x, y, ratio = 1, alternative = c("two.sided", "less", "greater"), conf.level = 0.95, ...) > var.test(prior,post)$conf.int [1] 0.1772458 0.8534348 attr(,"conf.level") [1] 0.95 通过函数var.test()计算后的结果可以看出,两样本方差比在95%置信水平下的区间估计为[0.1772, 0.8534],这说明延长营业额后,周营业额的波动性变大。
6.4关于比率的区间估计
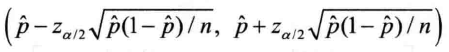
比率的估计在R中实现起来也比较简单,函数prop.test()可以直接完成对P的估计和检验,其调用格式为
prop.test(x, n, p = NULL,
alternative = c("two.sided", "less", "greater"),
conf.level = 0.95, correct = TRUE)
其中,参数x为具有某种特征的样本个数;n为样本量;P设置假设检验时原假设的比率值;correct是逻辑值,设置是否应用Yates连续性修正,默认为TRUE
例:
某市为了解居民住房情况,抽查了n=2000户家庭,其中人均不足5平米的困难户有x=214个,通过样本信息计算该市困难户比率P的置信区间(置信度为0.95)
> prop.test(214,2000) 1-sample proportions test with continuity correction data: 214 out of 2000, null probability 0.5 X-squared = 1234, df = 1, p-value < 2.2e-16 alternative hypothesis: true p is not equal to 0.5 95 percent confidence interval: 0.09396256 0.12157198 sample estimates: p 0.107
比率检验函数的计算结果表明,在95%的置信水平下,困难户比率的区间估计为[0.0940,0.1216],而最后一行的P值给出的是点估计,该市困难户比率为0.107
事实上,当样本数足够多时,x服从超儿何分布,上面我们用的是正态分布近似,但当抽样比很小时还可以用二项分布来近似,这时用到的函数是二项式检验binom.test(),其调用格式如下,内部参数与prop.test()一致。在上例中,如果该市的总人口数较大,那么抽样比很小,就应当用二项分布近似:
> binom.test(214,2000) Exact binomial test data: 214 and 2000 number of successes = 214, number of trials = 2000, p-value < 2.2e-16 alternative hypothesis: true probability of success is not equal to 0.5 95 percent confidence interval: 0.09378632 0.12137786 sample estimates: probability of success 0.107
二项式检验的结果表明,在95%的置信水平下,困难户比率的区间估计为[0.0938, 0.1214],这与修正正态近似的结果非常接近,点估计值仍为0.107

正文到此结束
热门推荐










相关文章

近期评论
-
你这基本没有更新呀,最近文章显示还是2019年的文章。不符合要求哈
-
关键词:慕云博客 链接:https://www.lilun.me 描述:分享原创文字的个人博客
-
-
-
可以提供一下源码吗
-
不是商业站,鸡娃学习笔记
-
-
-
-
听他们说很厉害的样子
Loading...
![[HBLOG]公众号](http://www.liuhaihua.cn/img/qrcode_gzh.jpg)

