Q Replication 对异构数据转换的支持
随着数据复制业务的不断发展,更多时效性要求较高的数据复制需求涌现,但是目前采用的应用级数据表复制技术无法满足高时效数据复制需求。为了进一步提升业务处理效能,Q Replication 产品进行了功能完善,实现了支持异构数据的转换,通过 Expression subscription 以及直接调用存储过程等方法,满足了客户相关应用场景的需求。
本文详细阐述了 Q Replication 对异构数据转换的支持,Expression subscription 的功能特性和转化机制,存储过程的功能特性和验证使用,以及对各种具体数据转换处理异构场景的分析。
支持目标端 Oracle 数据复制
应用背景及客户需求
当今商业实践中企业级的数据处理系统通常很庞大复杂。核心业务的数据灾备,多套系统之间的数据同步,应用升级时主备系统切换等需求使得应用层数据复制产品 Q Replication 的重要性得以体现。同时企业系统通常拥有复杂的配置,异构数据库之间的数据复制成为统一企业整体数据一致性的难题,其中 DB2 和 Oracle 这两个主流数据库之间的数据同步更是亟待解决的问题。
银行核心业务,信用卡业务或者数据分析报表业务往往分布在 DB2 和 Oracle 等异构数据库中。而异构数据库间的数据同步问题更加复杂。由于无法使用系统级别以及库级别备份,用户往往自己编写自己的 ETL 应用来处理异构数据差异。而此种方法大多只能使用夜间批量窗口进行,因此会有 T+1 天的数据延迟。使得下游数据库无法上线延迟要求较高的应用。
图 1. 数据延迟示意图

IBM IIDR Q 复制产品致力于数据复制及信息整合一直紧跟市场需求,Q 复制产品发布了新特性 Native Oracle Apply,提供了从 DB2 到 Oracle 近实时的表级别复制。如上如所示,相比于以往 ETL 等解决方案,应用层数据复制的提供了准实时的复制延迟,极大的提高了不同系统间数据的同步效率。针对异构数据库间不同表结构的问题,Q 复制 Native Oracle Apply 通过对 Expression 和 stored procedures 的支持提供了灵活的异构数据转换方案。
Native Oracle Apply 介绍
从 DB2 LUW V101FP3 开始,Data Replication 开始支持 Native Oracle Apply。与普通的 Q Apply 类似,Native Oracle Apply 接收从 MQ 队列传过来的消息,并把它们写入到 Oracle 数据库里。与以前的 Federation DB 的方式相比,Native Oracle Apply 配置步骤更简单,我们不需要再用 Federation 的命令来连接 Oracle 数据库,而是直接通过 Apply 程序去访问,所以它的效率也更高。Native Oracle Apply 的配置和相关参数与普通的 Q Apply 类似。我们可以通过 asnclp 或者 RC 来配置它,然后通过 asnoqapp 命令来启动它,通过 asnoqacmd 来停止服务或者更改相关参数。
异构数据转换方案
采用不同数据库技术使得信息资源的异构性在企事业的管理信息系统中无处不在,形成了大量的信息孤岛,不利于信息资源的共享,阻碍了企事业单位的信息交流。Q Replication 增加了对异构数据的支持,实现了主机 DB2 到平台 Oracle 数据库复制,并保持着同样高的复制性能。
对于基本的异构数据类型的,Q APPLY 能够自动转换相应的结构,同时也支持 Expression subscription,使得异构数据的转换更加灵活。这基本可以覆盖绝大多数的异构的数据转换,对于更复杂的数据提取和筛选以及数据转码处理,则可以通过存储过程进行转换,实现数据复制。
回页首
Expression subscription 功能特性及使用
Expression subscription 的配置
与普通的 Q Apply 类似,Native Oracle Apply 支持 Expression, 我们可以在创建 Q Subscription 的时候使用 Expression。下面就是一个简单的例子,我们要在 Oracle 的目标表中,合并两列 C2 和 C3 中的字符串并存放到 C4 中。
下面是源表的定义:
Create table T1(MYKEY varchar(10) not null, C2 varchar(10) not null, C3 varchar(10) not null,primary key(MYKEY))
清单 1. asnclp 调用文件示例
ASNCLP SESSION SET TO Q REPLICATION; SET SERVER CAPTURE TO DB SOURCE; SET SERVER TARGET TO CONFIG SERVER TARGET FILE "asnservers.ini" ID USER1 PASSWORD "PASS1234"; SET RUN SCRIPT NOW STOP ON SQL ERROR ON; SET CAPTURE SCHEMA SOURCE ASN; SET APPLY SCHEMA ASN; CREATE QSUB SUBTYPE U USING REPLQMAP "QMAP1" (SUBNAME "T10001" T1 TARGET NAME T1 TYPE USERTABLE TRGCOLS ALL EXPRESSION (":C2 || :C3" TARGET C4) ); QUIT; 从上面的文件中我们可以看到,合并两列我们用的是 EXPRESSION (":C2 || :C3" TARGET C4)。在编写表达式的时候,需要注意在源表列名的前边加上冒号 (:),而目标表的列名前边,不用加冒号。为了查看 Expression 的实际效果,我们需要启动 Q Capture 和 Native Oracle Apply, 并且在源表中插入下面的数据。
insert into T1 values('K1','222','333')
检查 Oracle 目标表中的数据,我们就会看到 C4 中的字符串是由 C2 和 C3 合并得来的。
清单 2. 查询结果
SQL> select * from T1; MYKEY C2 C3 C4 ---------- ---------- ---------- ---------- K1 222 333 222333
除了使用 asnclp 配置 Expression 之外,我们也可以用 RC (Replication Center) 来配置。
在创建 Q Subscription 的第 6 步,点击 Column mapping 右侧的省略号按钮。
图 2. 创建 Q Subscription
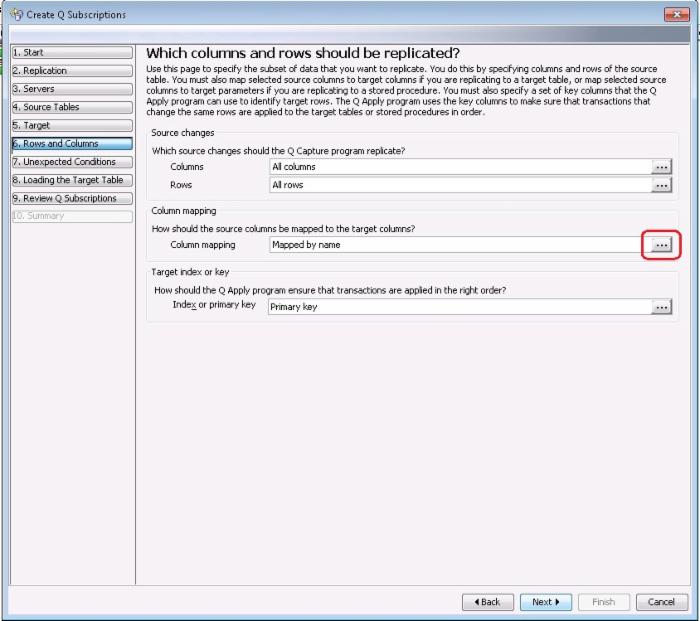
在下面的 Column Mapping 对话框中,点击 New Expression 按钮
图 3. 创建表达式
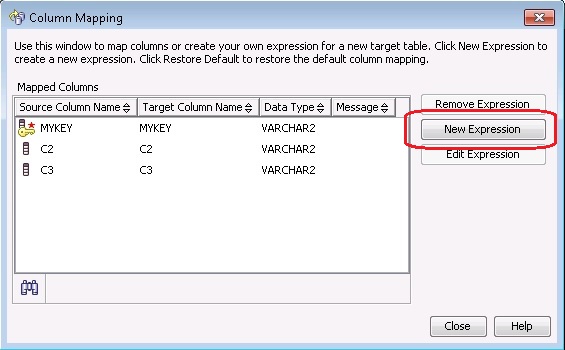
在 Expression 对话框中,我们可以输入 Expression 和 Target Column Name:
图 4. 编辑表达式
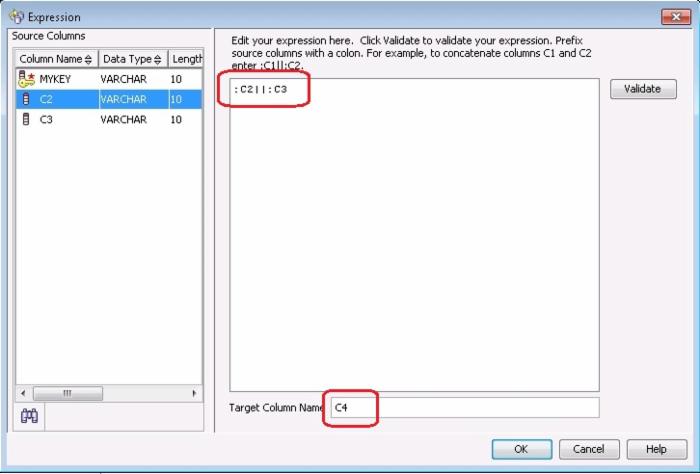
然后我们可以点击 Validate 按钮来检查我们的 Expression 是否正确:
图 5. 表达式核验
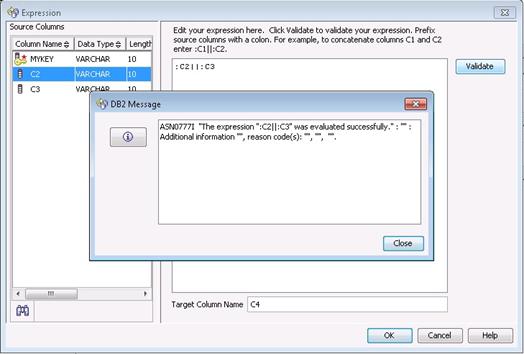
点击 Close 按钮,点击 OK 按钮,并完成其它步骤之后,Q Subscription 就创建成功了,它里面包含的 Expression 和上文中使用 asnclp 创建的 Expression 具有相同的功能。
Expression 支持类型及转换机制详解
Q Subscription 中使用的 Expression,实际调用的是 Oracle 数据库中的表达式。因此只要是 Oracle 支持的表达式,在 Expression 中都可以使用。我们可以用 RC 中的 Validate 按钮来验证一下 Expression 和 Oracle 表达式之间的关系。
例一:在 Expression 中写入一个 DB2 支持,而 Oracle 不支持的表达式 current timestamp, 这个表达式在 DB2 中将返回当前的时间:
清单 3. 查询结果
db2 => select current timestamp from T1 -------------------------- 2014-12-02-08.38.18.551088 2014-12-02-08.38.18.551088 2 record(s) selected.
而在 Oracle 中,这个表达式是不支持的:
清单 4.Oracle 中运行结果
SQL> select current timestamp from T1; select current timestamp from T1 * ERROR at line 1: ORA-00936: missing expression
我们将表达式 current timestamp 放到 RC 的 Expression 对话框中,并点击 Validate 按钮,我们就会看到,报错信息与 sqlplus 报的错误是相同的:
图 6.RC 中运行结果

例二:在 Expression 中写入一个 DB2 不支持,而 Oracle 支持的表达式 initcap(MYKEY), 这个表达式在 DB2 中是不支持的:
清单 5.DB2 查询示例
db2 => select initcap(MYKEY) from T1 SQL0440N No authorized routine named "INITCAP" of type "" having compatible arguments was found. SQLSTATE=42884
清单 6.ORACLE 查询示例
SQL> select initcap(MYKEY) from T1; INITCAP(MY ---------- Smith Smith2
我们将表达式 initcap(MYKEY) 放到 RC 的 Expression 对话框中,并点击 Validate 按钮,我们就会看到,验证是成功的。注意我们要在源表列名的前边加上冒号 initcap(:MYKEY)。
图 7. 验证结果示例
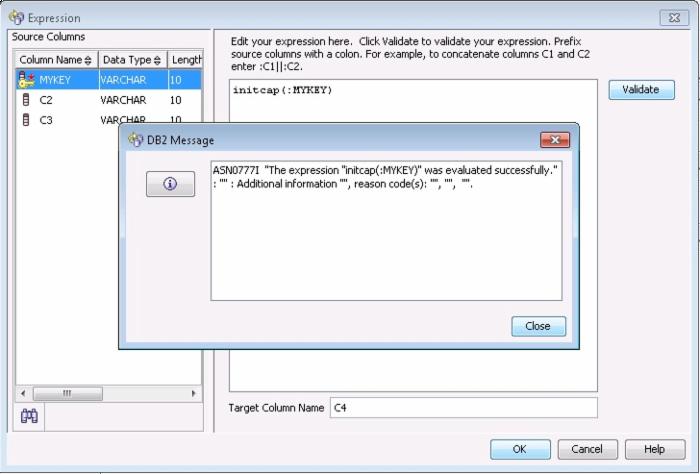
与 RC 相同,Native Oracle Apply 程序在接收到 MQ 传来的数据以后,也会调用 Oracle 本身与 Expression 相对应的表达式来处理这些数据,并把处理好的数据写入到 Oracle 数据库中。我们可以利用上面的例二中创建的 Q Subscription 来实际查看一下数据的复制。
首先启动 Q Capture 和 Native Oracle Apply。然后在源表中插入一行数据,确认在 MYKEY 列中的字母都是小写的 aaaa。
清单 7. 插入数据及查询结果
db2 => insert into T2 values('aaaa','2222','3333') DB20000I The SQL command completed successfully. db2 => select * from T2 MYKEY C2 C3 ---------- ---------- ---------- aaaa 2222 3333 1 record(s) selected. Native Oracle Apply 在获取到这条数据后,会根据 Expression initcap(:MYKEY) 来调用 Oracle 相对应的表达式,得到返回的数据后做为目标表的列 C4 放到 Oracle 数据库中。我们可以看到 C4 中第一个字母已经是大写的。
清单 8. 查询结果示例
SQL> select C4,C2,C3 from T2; C4 C2 C3 ---------- ---------- ---------- Aaaa 2222 3333
回页首
Stored Procedure 功能特性及使用
存储过程命名规范和参数类型
- 命名规范
Oracle 存储过程的命名为 schema.procname,或者也可以定义在一个包或者一个对象集合下,比如:schema.packagename.procname。
Oracle 支持存储过程名称的重载,通过包的名字区分识别。当一个程序在一个包中定义,Oracle 支持多参数的重载,以及相同数量个数但不同参数类型的重载。
下边是一系列重载的例子:
清单 9. 重载示例
EXEC [MYSCHEMA].MYPROC(1); EXEC [MYSCHEMA].MYPKG.MYPROC (1); EXEC [MYSCHEMA].MYPKG.MYPROC ("HELLO"); EXEC [MYSCHEMA].MYPKG.MYPROC (1, 2, 3); 在这个例子中,MYPROC 是一个独立的存储过程,MYPKG.MYPROC 则是另一个存储过程,并具有三种不同的参数重载。[ MYSCHEMA] 是一个可选项,默认是当前用户所使用的 SCHEMA。
- 参数类型
与 DB2 的存储过程不同的是,Oracle 存储过程定义的默认类型是 PL / SQL 类型,它是常规的 Oracle 数据库类型的超类型。下面的示例是对比:
清单 10. 支持参数类型示例
CREATE OR REPLACE PROCEDURE MYPROC (C1 IN NUMBER, --> Number 是 PL/SQL 类型 C2 IN VARCHAR2, --> Varchar2 是 PL/SQL 类型 C3 IN RAW) IS --> Raw 是 PL/SQL 类型 BEGIN <body of stored procedure> END; / CREATE OR REPLACE PROCEDURE MYPROC (C1 IN NUMBER(10), --> 错误 C2 IN VARCHAR2(10), -->错误 C3 IN RAW(16)) IS -->错误 BEGIN <body of stored procedure> END; /
上面的例子可以看出,当描述为 PL/SQL 类型时,任何数量类型的最大长度都被视为 38 位,任何 VARCHAR2 或 RAW 类型的最大长度都被看做 4000 位。所以不论用户的定义是大小,都被试作最大的长度,这将会严重影响复制性能。为了对数据类型有更精确的限制,Oracle 提供了两种方式去指定。
一种是默认的数据类型,比如:
SUBTYPE INTEGER IS NUMBER(38,0); -- 只允许整数
另一种是,可以参照表中的列的数据类型作为原型,比如:
清单 11. 以列的数据类型为原型示例
CREATE TABLE MYSCHEMA.MYTAB( C1 NUMBER(8) ); -- CREATE A STANDALONE STORED PROC CREATE OR REPLACE PROCEDURE MYPROC(C1 IN MYSCHEMA.MYTAB.C1%TYPE) IS BEGIN INSERT INTO MYTAB VALUES (P_C1); COMMIT; END; /
在这个例子中,MYPROC 中 C1 的类型就是 MYSCHEMA.MYTAB 表中 C1 的类型,即 NUMBER(8)。
存储过程的定义详解
存储过程的定义
当目标端需要在复制到目标库之前对数据进行复杂的处理,则需要使用存储过程来实现,作为 Q APPLY 的目标端。创建的存储过程需要满足 Q 复制的如下要求,其中有以下 4 个是必须要用的参数:
·IN/OUT OPERATION NUMBER
第一个是 IN/OUT OPERATION NUMBER,OPERATION 操作必须被定义为 IN/OUT 数字类型,输入参数用来确定所输入的数据是哪种 SQL 操作,比如 16 表示输入的数据时插入操作。
清单 12. 操作参数
16 -> insert 32 -> non key update 64 -> delete 128 -> key update
- IN SUPPRESSION_IND VARCHAR2
第二个参数 IN SUPPRESSION_IND VARCHAR2 用来表明源表数据是否被压缩。1 代表被压缩,0 代表未被压缩。
- IN SRC_COMMIT_LSN RAW
第三个参数 IN SRC_COMMIT_LSN RAW 表明源端 commit 的 LSN,类型可以改为 RAW(16)。
- IN SRC_COMMIT_TIME TIMESTAMP
第四个参数 IN SRC_COMMIT_TIME TIMESTAMP 表明源端 commit 的时间,类型可以改为 TIMESTAMP(6)。
清单 13. 存储过程定义实例:
CREATE TABLE THETAB(KEY1 NUMBER(8) NOT NULL, C2 VARCHAR2(100) NOT NULL, C3 TIMESTAMP(0) NOT NULL PRIMARY KEY (KEY1)); CREATE OR REPLACE PROCEDURE THEPROC( OPERATION IN OUT INTEGER, SUPPRESSION_IND IN VARCHAR, SRC_COMMIT_LSN IN RAW, SRC_TRANS_TIME IN TIMESTAMP, XKEY1 IN THETAB.KEY1%TYPE, KEY1 IN THETAB.KEY1%TYPE, C2 IN THETAB.C2%TYPE, C3 IN THETAB.C3%TYPE) AS … END;
其中前四个参数为之前介绍的固定参数。随后是所有列的参数,参数名为列名。主键列需要两个参数,其中一个带前置 X 的参数为主键 update 之前的值 (如例子中的 XKEY1),不带 X 的参数为主机上 update 之后的值 (如例子中的 KEY1)。
Stored Procedure Targets 的验证方法
Oracle 可以通过 PL/SQL 来调用或者直接存储过程的语句,如下两种方式:
清单 14. 调用方式示例一
BEGIN CALL MYSTOREDPROC(1); END ; /
或者
清单 15. 调用方式示例二
EXEC MYSTOREDPROC(1);
输出是存储过程的执行状态,通过这个返回结果验证数据复制是否成功完成,实现主机到平台的数据类型转换。
表 1. 返回值意义列表
| Oracle return code | Type of operation | What the return code means | How Q Apply reacts |
|---|---|---|---|
| 0 | Insert | 数据被成功插入数据库. | Q Apply 处理下一条数据. |
| 0 | Update | 数据被成功更新. | Q Apply 处理下一条数据 |
| 0 | Delete | 数据被成功删除. | Q Apply 处理下一条数据 |
| +100 | Delete | 数据在目标端不存在 | Q Apply 不再尝试. |
| +100 | Update | 数据在目标端不存在 | 若强制 Q Apply 执行 update, Q Apply 将把 update 变成 insert 操作,然后再次尝试 update。 |
| +1 | Insert | 数据在目标端已经存在 | 若强制 Q Apply 执行 insert, Q Apply 将把 insert 变成 update 操作,然后再次尝试 insert。 |
| +1 | Key update | 新的 KEY 在目标端已经存在 | 若强制 Q Apply 执行 key update, Q Apply 将把此次 key update 变成对已存在的新 key 的 update 操作,然后再次尝试 update。 |
例如,当 operation 是插入操作时,RC 为 0 表示数据插入成功,而 RC 为+1 就表示目标端已经存在同一条数据。
控制表信息及新参数
在完成存储过程的编写后,需要对 Q 复制的控制表进行配置。
控制表本身并没有变更,但是新增了对存储过程支持的值来进行相应的配置,保证对存储过程的支持。
表 2. 控制表参数含义
| Parameter | Datatype | Notes / description |
|---|---|---|
| IBMQREP_TARGETS.TARGET_TYPE (existing) | INTEGER | TARGET_TYPE=5 时表示此 QSub 使用存储过程 |
| IBMQREP_TARGETS.TARGET_NAME (existing) | VARCHAR2 | TARGET_TYPE=5 时 TARGET_NAME 用来标识存储过程名字。当存储过程在 package 中时,需要使用如下格式"packagename".procedurename |
用户可以通过 ASNCLP 进行配置,事例语句如下。
清单 16. 创建 QMAP 示例
CREATE QSUB USING REPLQMAP QMAP1(SUBNAME SUBNUM1 SCHEMA.S1001 OPTIONS ALL CHANGED ROWS N HAS LOAD PHASE N EXIST TARGET NAME SCHEMA.PROC1001 TYPE STOREDPROC TRGCOLS ALL);
回页首
具体异构场景分析
数据类型转换
在处理异构场景过程中,会遇到很多困难。首先在不同数据库应用中,使用的数据类型定义会不尽相同。不仅是数据库本身支持的类型不同,不同数据库开发人员在类型定义时的不同习惯也会导致一定的差异。在数据库表定义无法变更的情况下,则数据复制软件需要支持异构数据类型转换。
IIDR QRep Native Oracle Apply 默认支持 DB2 源和 Oracle 目标端的同类型转换,如同为 time,或者 varchar 转为 varchar2 等。但是对于用户表定义中较大的差异,如 varchar 转为 number,或 varchar 转为 time,则需要通过添加 Expression 或者 stored procedure 的方式来实现。
图 8. 数据转换示意图
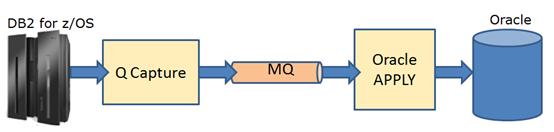
如上图所示,Apply 程序会从 MQ 中读取消息并进行解析。如果在 QSub 中配置了 Expression,apply 则会在动态 SQL 中拼接 Expression,从而使用 Oracle Function 进行数据类型转换。例如:
清单 17. 数据类型转换表达式
to_char(:SRC_COL)
不光是数据类型转换,使用 Expression 同样可以完成简单的数据处理。通过使用 LPAD,SUBSTR,Trim 等函数可以实现数据位数变化,数据截取等任务。同时还可以调用 User Defined Function(UDF)来进一步扩展处理能力。
清单 18. 使用函数进行数据类型转换示例
lpad(to_char(:SRC_COL),10,' ') ltrim(substr(lpad(to_char(:SRC_COL),8,'0'),2,7),'0')
虽然通过调用 UDF 已经使 Expression 的方式具有了一定的扩展性,但对于多列数据间的计算以及更为复杂的场景,则需要使用 Stored Procedure 的方式来提高扩展性。在本文之前的段落中,我们已经介绍了如何编写 Oracle Apply 适用的 Stored Procedure。在实际调用中,Oracle Apply 会将原有的增删改操作改为调用 Stored Procedure 的 call 语句。从而完全将数据分析,处理以及插入的任务交由 Stored Procedure 来完成。在具体编写的过程中,可以使用 internal SQL 或者 external C/Java 的方式。
codepage 转换
在不同数据库之间进行复制,codepage 的差异也是影响复制关系建立的重点,因此 Oracle Apply 需要完成 codepage 的自动转换,以满足异构数据之前的整合。
图 9.codepage 转换示意图
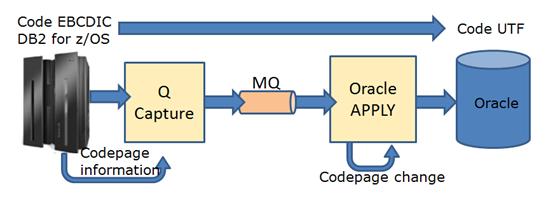
例如上图所示,源端为 DB2 数据库,使用 EBCDIC。目标端为 Oracle 数据库,使用 UTF。首先,Q Capture 从源端数据库中读取信息,并对字符类型数据进行分析。获取 Codepage 信息。然后,Q Capture 在发送消息时会对将相应的字符数据类型标记为 EBCDIC,MQ 将消息直接发送出去。在目标端系统中,Oracle Apply 被设置成与 Oracle codepage 相同的值 UTF。最后,Q Apply 会调用函数,将消息中 EBCDIC 的字符转换为 UTF。Q Apply 在随后插入数据的过程中,因为标记与 Oracle 数据库 codepage 相同,Oracle 不会再对数据进行转码。从而完成整个转码的过程。
一种情况是,源端数据库中实际数据与表定义 codepage 不符合,或者用户想自定义更改 codepage 转码。可以在源端 QSub 定义中更改 ALTERNATIVE_CODEPAGE 这一列,输入用户自己想要定义的源端码制。这样 Q Capture 在发送消息时会使用用户定义码制来进行标记。目标端转码过程不变。
回页首
结束语
随着企事业竞争与兼并的加剧以及多样化新技术的采用,使得具有异构特征的信息资源充斥着企事业信息平台。本文通过对 Q Replication 支持异构数据转换的研究,详细阐述了通过 Expression 以及存储过程进行对复杂数据的转换,以及相关的功能特性和转化机制,并解决了实际场景中各种具体对异构数据转换的处理问题。
通过对异构数据资源进行转换和整合处理,使得信息资源更具有统一性和可靠性,节约了时间和物质资源,为信息资源的交换和使用提供了良好的前提,对数据维护、数据拓展具有着重要的意义。
回页首
参考资源
正文到此结束
热门推荐










相关文章






Loading...
![[HBLOG]公众号](http://www.liuhaihua.cn/img/qrcode_gzh.jpg)

