浏览器测试基础
本文主要介绍浏览器的结构、内核、进程模型以及相关的一些自动化测试的内容,可以作为浏览器测试的基础。
By 嫣梦
主流的浏览器的结构如下图所示,包含七个部分:
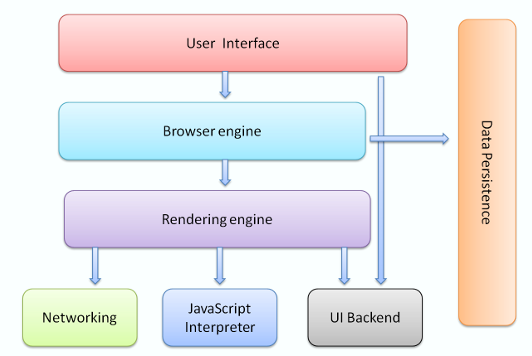
- 用户界面 - 包括地址栏、后退/前进按钮、书签目录等,也就是你所看到的除了用来显示你所请求页面的主窗口之外的其他部分。
- 浏览器引擎 - 用来查询及操作渲染引擎的接口。
- 渲染引擎 - 用来显示请求的内容,例如,如果请求内容为html,它负责解析html及css,并将解析后的结果显示出来。
- 网络 - 用来完成网络调用,例如http请求,它具有平台无关的接口,可以在不同平台上工作。
- UI后端 - 用来绘制类似组合选择框及对话框等基本组件,具有不特定于某个平台的通用接口,底层使用操作系统的用户接口。
- JS解释器 - 用来解释执行JS代码。
- 数据存储 - 属于持久层,浏览器需要在硬盘中保存类似cookie的各种数据,HTML5定义了web database技术,这是一种轻量级完整的客户端存储技术
内核简介
主流浏览器内核包括:
- Gecko——火狐系列
- Trident(mshtml)——IE系列
- KDE
- Webkit——safari&chrome
- Presto——opera
- Blink——chrome,Opera
常说的浏览器的内核,也就是浏览器最核心的部分——rendering engine,一般都叫“渲染引擎”,主要解析页面语法(包括html,css,javascript等)并且渲染页面。有时候也认为浏览器内核包含排版引擎和渲染引擎,js的引擎不分在内,只是个分类的方式,这里统一都在一起。
浏览器内核也就是浏览器所采用的render内核,它决定了最终网页时以什么内容和什么格式。不同内核对网页语法的解释不同,所以同一个网页在不同内核的浏览器中,渲染效果是不同的,也就是最终看到的网页显示不同。
出现了显示问题,一般需要两个方法验证:
用不同内核的浏览器进行测试来确定渲染问题(渲染不标准)
检查网站代码的编写(编写不标准)
更多请见: http://baike.baidu.com/view/1369399.htm?fr=aladdin
Trident(IE内核)
- Trident['traɪdnt] (mshtml)——IE系列
- Mosaic——重写
- JavaScript:Jscript,IE9开始用Chakra
微软在Mosaic代码的基础之上修改而来,借windows上位,长期一家独大
问题:
- Trident内核曾经几乎与W3C标准脱节
- 大量安全性问题
由于一家独大,老的IE对w3c标准支持很差,很多网站专门为了IE6写的页面,在IE6下正常;新的IE对w3c支持比较好,所以很多以前IE6下正常的页面在IE9下显示不正常,这不是兼容性的问题,是老的网页本身并不标准。
更多:
http://baike.baidu.com/subview/682014/8049760.htm?fr=aladdin Gecko内核
- Gecko ['ɡekəʊ]——火狐系列
- Mosaic——重写
- JavaScript:SpiderMonkey / TraceMonkey / JaegerMonkey
- Netscape6 最早使用的内核
- 现在主要由Mozilla基金会进行维护
- 开源
- 跨平台
- 基于的浏览器少
netscape6 最早使用的内核,现在主要由Mozilla基金会进行维护,开源的浏览器内核;
SpiderMonkey应用在Mozilla Firefox 1.0-3.0,TraceMonkey应用在Mozilla Firefox 3.5-3.6版本,JaegerMonkey应用在Mozilla Firefox 4.0及后续的版本。
更多: http://baike.baidu.com/view/404125.htm?fr=aladdin
webkit 内核
- Webkit——safari&chrome
- WebCore——khtml发展
- JavaScriptCore——kjs,Nitro(Safari 4以后)
- 由KHTML发展而来
- 苹果开源
- 目前火热
- 遵循W3C标准
- http://webkit.org

Chromium同样使用webkit内核,但是花费了很大的精力将它重新整理了。
引擎方法:
V8 应用于Chrome、傲游3
Javascript 引擎
- 其他
- Linear A/ Linear B / Linear C/ Futhark/ Carakan
- KJS,KDE的ECMAScript/JavaScript引擎,最初由Harri Porten开发,用于KDE项目的Konqueror网页浏览器中。
- Narcissus,开放源代码,由Brendan Eich编写(他也参与编写了第一个SpiderMonkey)。
- Tamarin,由Adobe Labs编写,Flash Player 9所使用的引擎。
- Nitro(原名SquirrelFish),为Safari 4编写
- Sunspider
- Javascript测试标准
- http://www.webkit.org/perf/sunspider/sunspider.html
演变过程:
Linear A/Linear B/ Futhark / Carakan
Linear A->Opera 4.0-6.1
Linear B->Opera 7.0~9.2
Futhark->Opera 9.5-10.2
Carakan->Opera 10.5及后续
渲染流程

#:DOM即Document Object Model
Render进程解析html,将其中的各种标签和属性转化为dom节点,它解析外部CSS文件及style标签中的样式信息。这些样式信息以及html中的可见性指令将被用来构建另一棵树——render树。
Render树由一些包含有颜色和大小等属性的矩形组成,它们将被按照正确的顺序显示到屏幕上。
Render树构建好了之后,将会执行布局过程,它将确定每个节点在屏幕上的确切坐标。再下一步就是绘制,即遍历render树,并使用UI后端层绘制每个节点。
需要注意的是,解析和呈现的过程,是并行的——也就是,解析了一部分就呈现一部分。这是为了提高用户的体验,一边网络在请求,一边html开始解析,一边在浏览器页面上呈现。
Gecko vs. Webkit
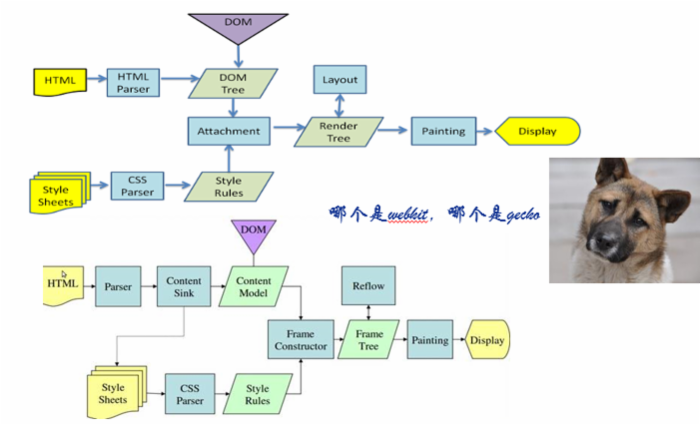
1.主流程相同
2.Gecko中每个元素成为一个frame,最终格式化组成的结构叫做frame树,webkit中使用render树这个名词来命名由渲染对象组成的树;
3.Webkit中元素的定位称为布局,Gecko中这个过程叫回流;
4.Webkit称利用dom节点及样式信息去构建render树的过程为attachment,Gecko中叫做frame constructor;
5.Gecko中,html和dom之间有一个内容接收的部分,叫做content sink
解析
- 解析(Parsing-general)
- 文法(Grammars)
- 上下文无关文法
- 解析器
- 文法(Grammars)
- 词法分析器
- 语法分析器(YACC/LEX)
- 自顶向下解析及自底向上解析
- 解析器生成器
- 自动化解析(Generating parsers automatically)
- 转换(Translation)
- 可惜:
- 这些不适合 html 。。。
- 这些适合 css 和 javascript
1.解析一个文档即将其转换为具有一定意义的结构——编码可以理解和使用的东西。解析的结果通常是表达文档结构的节点树,称为解析树或语法树;解析可以分为两个子过程——语法分析及词法分析
2.每种可被解析的格式必须具有由词汇及语法规则组成的特定的文法,称为上下文无关文法
Html 解析
特点:
- 非常规解析
- 上下文相关,不能自顶向下或者自低向上
- 语言本身的宽容特性
- 非法html有容错机制
- 解析过程是往复的,需要处理很多动态的东西,比
- 如javascript对html的影响
- html专属的解析器
- 符号化
- 构建树
完成的解析算法参考:
- http://www.w3.org/TR/html5/syntax.html#html-parser
1. HTML DTD (Document Type Definition文档类型定义), http://www.w3.org/TR/html4/strict.dtd
2.DOM标准: http://www.w3.org/DOM/DOMTR
参考资料:
符号识别算法( The tokenization algorithm )
算法输出html符号,该算法用状态机表示。每次读取输入流中的一个或多个字符,并根据这些字符转移到下一个状态,当前的符号状态及构建树状态共同影响结果,这意味着,读取同样的字符,可能因为当前状态的不同,得到不同的结果以进入下一个正确的状态。
树的构建算法( Tree construction algorithm )
在树的构建阶段,将修改以Document为根的DOM树,将元素附加到树上。每个由符号识别器识别生成的节点将会被树构造器进行处理,规范中定义了每个符号相对应的Dom元素,对应的Dom元素将会被创建。这些元素除了会被添加到Dom树上,还将被添加到开放元素堆栈中。这个堆栈用来纠正嵌套的未匹配和未闭合标签,这个算法也是用状态机来描述,所有的状态采用插入模式。
浏览器 容错
你从来不会在一个html页面上看到“无效语法”这样的错误!
webkit给出一些官方“ 错误典范 ”:
- 在未闭合的标签中添加明确禁止的元素。这种情况下,应该先将前一标签闭合
- 不能直接添加元素。有些人在写文档的时候会忘了中间一些标签(或者中间标签是可选的),比如HTML HEAD BODY TR TD LI等
- 想在一个行内元素中添加块状元素。关闭所有的行内元素,直到下一个更高的块状元素
- 如果这些都不行,就闭合当前标签直到可以添加该元素。
渲染树构建
目的:正确的绘制文档内容——文档的可视化过程
特点:
- 和DOM并非一一对应
- 只显示需要显示的dom元素
- 调整和容错
- 特殊位置
- 样式相关(不深入讨论)
- 样式计算
- 样式解析
- 共享样式
- 级联顺序
- 动态加载(逐步)
Dom和render tree并非一一对应,比如:
- 只显示需要显示的dom元素
- Hidden的元素不会出现在渲染树中
- 调整和容错
- 一些对html的容错,还有复杂结构的元素
- 特殊位置
- 悬浮框,绝对坐标,特效等
DOM对应的是整体的页面结构,包含“看到的”和“看不到的”,而render对应的是要展示的东东。
布局(回流)
目的:将render树中的元素按照属性找到位置和大小过程特点:
- 特点
- 流形式——靠后的元素不影响前面布局特征
- 递归执行——每个元素递归进行布局
- 局部布局——尽可能对被影响的元素布局(dirty)
- 全量和增量
- 全量:全局样式改变,窗口改变,滚动条等
- 增量:DOM添加新元素等(队列或者计数方式)
- 同步和异步
- 一般全局layout同步
- 增量layout一般异步执行
- 脚本调用样式同步调用增量layout
- 缓存优化
- 直接从缓存中读取渲染树或者对象
Dirty bit 系统
为了不因为每个小变化都全部重新布局,浏览器使用一个dirty bit系统,一个渲染对象发生了变化或是被添加了,就标记它及它的children为dirty——需要layout。存在两个标识——dirty及children are dirty,children are dirty说明即使这个渲染对象可能没问题,但它至少有一个child需要layout。
layout过程:
1. parent渲染对象决定它的宽度
2. parent渲染对象读取chilidren,并:
a. 放置child渲染对象(设置它的x和y)
b. 在需要时(它们当前为dirty或是处于全局layout或者其他原因)调用child渲染对象的layout,这将计算child的高度
c. parent渲染对象使用child渲染对象的累积高度,以及margin和padding的高度来设置自己的高度-这将被parent渲染对象的parent使用
d. 将dirty标识设置为false
绘制
目的:遍历render树并调用它们的绘制方法在屏幕上绘制
过程特点:
- 特点
- 递归执行——逐一绘制每个元素
- 调用操作系统UI组件
- 全量和增量
- 全量:类似于布局中的全量
- 增量:有时候需要“回溯”
- 绘制顺序
- 按照压入堆栈的顺序进行绘制
- css2定义了绘制过程的 顺序
- 背景色->背景图->border->children->outline
动态变化
特点:以最小的动作响应一个变化行为特征:
- 一个元素的样式变化——重绘这个元素
- 一个元素的位置变化——重新布局和绘制
- 添加&删除一个dom——受影响节点会重新布局和绘制
- 全局样式变化——呈现树缓存失效,全局的重新布局和绘制
这些就是浏览器随着页面不断加载而展示不同内容的原因,另外如js的一些局部变动也都属于动态的范畴。
进程模型
特点:- 进程模型属于浏览器,和渲染引擎无关
- 渲染引擎是单线程的,在渲染进程里面
- Firefox&Safari渲染渲染进程就是主进程
- IE的渲染进行是Tab进程
- 有就创建,没有就销毁
- 进程和主进程权限相同
- 有窗体——获取句柄直接操作
- Chrome多进程和单进程都支持
- 有进程上限
- 有就创建,没有就销毁
- 进程权限不同(沙箱)
- 无窗体——共享内存方式操作
#关于共享内存的技术,请先了解IPC相关内容
IPC 可以参考: http://www.ibm.com/developerworks/cn/linux/l-ipc
Chrome进程设定方式:
- Process-per-site-instance:就是你打开一个网站,然后从这个网站链开的一系列网站都属于一个进程。这是Chrome的默认模式。
- Process-per-site:同域名范畴的网站放在一个进程,比如www.google.com和www.google.com/bookmarks就属于一个域名内(google有自己的判定机制),不论有没有互相打开的关系,都算作是一个进程中。用命令行--process-per-site开启。
- Process-per-tab:这个简单,一个tab一个process,不论各个tab的站点有无联系,就和宣传的那样。用--process-per-tab开启。
- Single Process:没有多进程只有多线程,用--single-process开启。
Chrome进程模型参考: http://www.cnblogs.com/duguguiyu/archive/2008/10/12/1308876.html
IE和Chrome对比:
IErender进程是直接将页面信息画在渲染进程上的,它有窗口句柄,父子进程权限一样;
Chrome进程间相互隔离,和主进程依靠共享内存进行交互;
Render进程比较
- IE和Chrome对比:
- IE render有窗口句柄,父子进程权限一样;
- Chrome render进程间相互隔离,和主进程依靠共享内存进行交互;
- 优缺点
- Chrome进程不影响主进程的使用;
- IE Render进程中经典的假死!
- IE进程不安全;
- Chrome进程降权处理
- Chrome内存消耗大
优缺点是什么呢?
- Chrome Render进程中不包含有窗口,主进程和render进行异步调用,render进程死掉了不影响主进程的使用;
- IE Render进程中就是有窗口句柄,而窗口又总是存在父子关系,这样一旦子窗口卡死就会造成主窗口卡死——经典的假死!;
- Chrome进程降权处理,出现“沙箱”,保证进程的安全;
- Chrome内存消耗大,需要适当对内存工作集合进行调整,总体来说,内存足够用的时候,不作调整,其他情况需要释放空闲的的render资源,即render进程的资源需要释放!从这个角度讲,使用chrome空闲的时间过长,会影响用户体验。
插件进程
进程特点:- 插件进程:
- Chrome中“embed”或者“object”元素,render通知主线程创建插件进程;
- Chrome中每个插件一个进程,通过引用计数进行回收;
- IE中插件线程形式存在,由render进行直接加载;
- 插件加载
- IE:根据CLSID、type="application/x-shockwave-flash"
- chrome:根据插件的MIME类型来确认是哪款插件,在特定的路径下面查找该类型的插件来创建进程的
- .ocx或者dll
- 扩展:
- 网页应用
注意:NPAPI插件进程是不在沙箱内的,PPAPI是把插件进程放在了沙箱内,像render进程来降低插件进程的权限,以保证安全。详情: http://blog.csdn.net/milado_nju/article/details/11661287
正文到此结束
热门推荐










相关文章






Loading...
![[HBLOG]公众号](http://www.liuhaihua.cn/img/qrcode_gzh.jpg)

