在线问卷数据的质量控制
在对互联网产品进行的用户研究中,通过在线问卷收集数据是一个非常普遍的方式。 在线问卷,不受访问的环境限制,回收速度很快,具有明显的优势。但是由于被访者没有相关的指导,在设备存在差异,回答的态度有不同等,因此数据的质量能否得到保证, 是一个关键的问题。数据质量绝对了数据是否具有科学性,是否可以代表用户,是否给出准确的研究结论。因此我们要考虑对在线问卷的数据进行质量控制的具体的方法,保证问卷数据的质量。
我们为什么会需要进行在线问卷数据的质量控制?
用户在线回答问卷的过程中,会出现一些问题,总结起来有以下三类:
1、会发生答题点击失误的情况
2、会有理解错误导致错误回答的情况
3、会出现答题不认真敷衍的情况
前两种情况,属于客观必然发生的小概率事件,不易通过技术对数据进行质量控制,但是出现的可能性小,可以忽略。而第三种情况,是用户答题态度有偏差,是可以通过 技术实现质量控制,从而把有问题的数据发现并剔除掉。
如何发现有问题的问卷数据并剔除呢?
针对答题不认真的问卷数据,我们要怎么才能发现呢?可以通过以下三个层面。
1. 地雷题
我们第一种方法,也是最常用的方法,是通过在问卷中设置地雷题,并通过地雷题 的数据来检验问卷数据的准确性。那么,什么是地雷题?
地雷题是问卷设计中验证用户回答态度认真与否而设计的题目。这类题目往往是 2 个,对应出现的。也就是针对相同的问题以不明显有差异的方式在问卷中提问两次。如果被访者回答对应出现的两道题目,给出了完全相反或者差异巨大的答案,那么可以在 一定程度上反映,这个人回答问卷的态度不够端正,可以怀疑这个人的数据是不真实的。
例如:在某个问卷中,Q1 问题是:以下物品,请问您家拥有哪些?,其中有“汽车” 选项。Q10 问题是:请问您家拥有以下哪些个人资产?,其中也有“汽车”选项。Q1 与 Q10 为地雷题,如果被访者这两个题目在汽车这个选项的答案出现差异,认为是不合格 的数据。
地雷题应该如何设置?
地雷题是在问卷收集之前,就要设置好的,如果没有设置,也就没办法通过其来进 行质控了。同时需要注意,地雷题的设置也是有技巧的,针对选择题,两道地雷题之间 的距离应该尽可能大。因为被访者在回答问卷的时候,不一定记得清之前问题和选择的 答案,如果地雷题之间相隔很多题目,用户如果态度不端正,是很容易被甄别出来的。
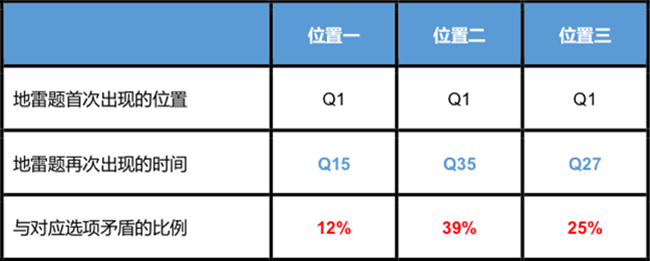
以下是一个实验的数据结果。实验是将相同的地雷题,放在问卷的三个不同位置, 所甄别出的不合格问卷数据的比例。我们发现,地雷题的相距越大,被访者回答与对应 选项的矛盾比例越高。
实验数据一:设置在不同位置地雷题的效果
2. 答题时间
通过答题时间的长短,我们可以知道很多被访者答题的情况:
(1)总体问卷回答时长
(2)单个问题回答时长
(3)总体问卷/单个问题的平均回答时长
(4)整体问卷/单个问卷的时长离散程度
……
通过以上这些时间数据,我们可以看到,一个被访者在正常情况下,回答整个问卷或者单个问题,他需要的一个时间大概是多久。如果回答问卷的平均需要15分钟的时间,而有的人用了1分钟就回答完了,而有的人用了2个小时,那么就很说明问题了, 回答时间过长或过短的被访者回答问卷存在一定的问题。
但是还有一种情况,就是如果平均时间是 15 分钟,那么 3 分钟的是否是认真的回 答,40 分钟是否是不认真的回答呢?这个我们需要什么依据来判断吗?这就需要一个标准,稍后我们来揭晓这个标准。
3. 题目选项个数
通过被访者回答问卷的多选题,选择的选项数量,也可以进行问卷数据的质量控制。 如果一被访者回答某个问题,所选择的选项明显多于或少于所有被访者回答这个问卷的 平均选项数,那么就要注意了!
以下是一些问卷题目,被访者的选择的选项情况
实验数据二:在线问卷的不同题目选项个数的平均值与最大值 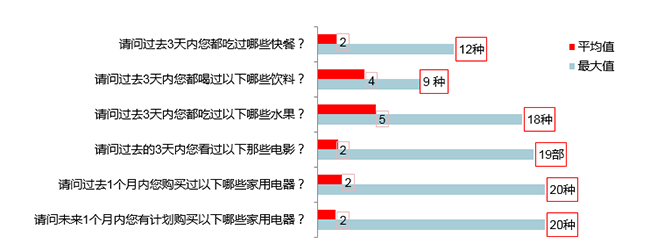
我们可以看到,对于吃饭,喝饮料,吃水果这种日常问题,被访者选择的选项个数明显多于平均值或者不符合常理,就应被认为是不合理的。比如图中,吃水果的题目, 有的用户选择了三天内吃了 18 种水果,这样的数据可能就有问题。
3σ 原则数据检验标准
刚才我们讲了答题时间,选项个数,可以反映被访者答题的数据质量。那么对于这两个因素,有没有一个标准可以来准确判断,怎么样的情况,我们就要剔除掉样本数据呢?
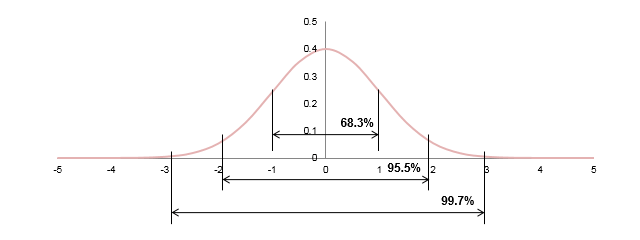
我们要引入一个概念。即统计学原理的 3σ 原则。3σ 准则又称为拉依达准则,它是先假设一组检测数据只含有随机误差,对其进行计算处理得到标准偏差,按一定概率确 定一个区间,认为凡超过这个区间的误差,就不属于随机误差而是粗大误差,含有该误 差的数据应予以剔除。这种判别处理原理及方法仅局限于对正态或近似正态分布的样本 数据处理,它是以测量次数充分大为前提的。在正态分布中 σ 代表标准差,μ 代表均值。
3σ 原则为数值分布在(μ-σ,μ+σ)中的概率为 0.6826,数值分布在(μ-2σ,μ+2σ)中 的概率为 0.9544,数值分布在(μ-3σ,μ+3σ)中的概率为 0.9974,可以认为,Y 的取值几乎全部集中在(μ-3σ,μ+3σ)区间内,超出这个范围的可能性仅占不到 0.3%。3σ 原则 告诉我们,标准正态分布时有 99.7%的可能数据应该落在 μ+3σ 的范围内。
选项个数在一定程度上是比较稳定的,即所有人选择个数的均值是相对稳定的。考虑到不同情况下大家行为的差异,我们需要关注所有人选择个数的标准差来衡量其离散 程度。由于在多选题中没有负数出现,因而数据分布如下图所示。数据落在 μ+3σ 范围内的概率均超过 99%,也就是说一个正常的数据有 99%的可能性会落在这个范围内, 超过这个范围的值发生的概率极小,因而一旦发生,可以认为是奇异值,需要剔除掉。
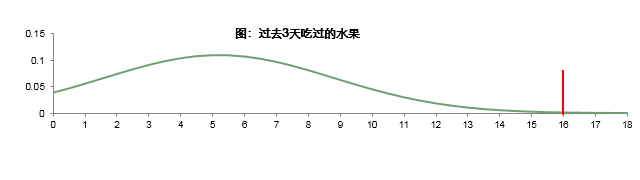
结合上图举例:如果 1000 人回答吃水果的题目,平均值是 4 个,标准差是 4,那么这道题目选项个数的合理范围的最小值是 0(4-3*4=-8,水果个数不能为负数,取 0) 个,最大值是 16(4+3*4)个,超过 16 个的问卷数据应被视为无效,而无效的被访者 不会超过 3 人。
同样的方法,也可以验证被访者答题时间是否合理。
今天我们讲了如何通过地不同的方式和方法,对在线问卷数据进行质量控制。希望 今天的内容对大家在问卷数据处理有一定的帮助,未来我们会进一步完善相关方法,并 及时和大家探讨!
正文到此结束
热门推荐










相关文章

近期评论
-
你这基本没有更新呀,最近文章显示还是2019年的文章。不符合要求哈
-
关键词:慕云博客 链接:https://www.lilun.me 描述:分享原创文字的个人博客
-
-
-
可以提供一下源码吗
-
不是商业站,鸡娃学习笔记
-
-
-
-
听他们说很厉害的样子
Loading...
![[HBLOG]公众号](http://www.liuhaihua.cn/img/qrcode_gzh.jpg)

