机器学习:更多的数据总是优于更好的算法吗?
【编者按】 在机器学习中,更多的数据总是比更好的算法好吗?对于Quora上的这个问题,Netflix公司工程总监Xavier Amatriain认为,很多时候增加更多的样本到训练集并不会提高模型的性能,而如果没有合理的方法,数据就会成为噪音。他通过Netflix的实践经验推导出最终的结论:我们需要的是好的方法,来帮助我们理解如何解释数据,模型,以及两者的局限性,这都是为了得到最好的输出。
在机器学习中,更多的数据总是比更好的算法好吗?
不是这样的。有时候更多的数据有用,有时它的作用不大。
为数据的力量辩护,也许最著名的是谷歌的研发总监 Peter Norvig ,他声称“我们没有更好的算法。我们仅仅拥有更多的数据”。这句话通常是链接到文章《The Unreasonable Effectiveness of Data》,这篇文章也是Norvig自己写的(虽然它的来源被放在IEEE收费专区,不过你应该能够在网上找到pdf格式的原文档)。更好的模型盖棺定论是Norvig的语录“所有模型都是错的,无论如何你都不会需要他们的”被错误地引用之时(点击 这里 查看作者澄清他是如何被错误引用的) 。
Norvig等人的作用是指在他们的文章中,他们的观点早在几年前被微软研究人员Banko和Brill在一篇著名的论文[2001]《 Scaling to Very Very Large Corpora for Natural Language Disambiguation 》中引用。在这篇论文中,作者给出了下图。

该图表明,对于给定的问题,迥然不同的算法执行结果几乎是一样的。然而,添加更多的样本(单词)到训练集里面,可以单调增加模型的精度。
因此,在封闭的情况下,你可能会认为算法更重要。嗯…没有这么快。事实是,Norvig的断言以及Banko和Brill的论文都是正确的…在一个环境中。但是,他们现在再次被错误地引用到一些环境中,而这些环境与最初的环境是完全不同的。但是,为了搞明白为什么,我们需要了解一些技术。(我不打算在这篇文章中给出一个完整的机器学习教程。如果你不明白我下面将要做出的解释,请阅读我对《 How do I learn machine learning? 》的回答?
方差还是偏差?
基本的想法是,一个模型的可能表现不好存在两种可能的(而且是几乎相反的)原因。
在第一种情况下,对于我们拥有的数据量来说,我们所用的模型太复杂了。这是一种以高方差著称的情形,其可以导致模型过拟合。我们知道,当训练误差远低于测试误差时,我们正面临着一个高方差问题。高方差问题可以通过减少特征数量加以解决,是的,还有一种方法是通过增加数据点的数量。所以,什么样的模型是Banko &Brill的观点和Norvig的断言可以处理的?是的,回答正确:高方差。在这两种情况下,作者致力于语言模型,其中词汇表中的大约每一个词都具有特征。与训练样本相比,这有一些模型,它们具有许多特征。因此他们很有可能过拟合。是的,在这种情况下,添加更多的样本将带来很多帮助。
但是,在相反的情况下,我们可能有一个模型,它太简单了以至于无法解释我们拥有的数据。在这种情况下,以高偏差著称,添加更多的数据不会带来帮助。参见下面一个真实的在Netflix运行的系统的一个制表以及它的性能,同时我们添加更多的训练样本到里面去。
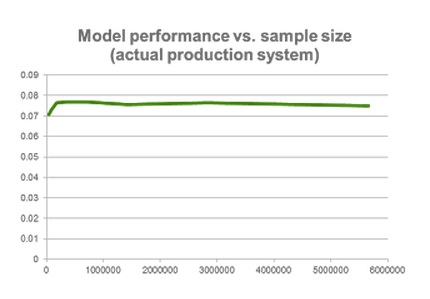
所以, 更多的数据并不总是有帮助的 。正如我们刚刚看到的,在许多情况下,增加更多的样本到我们的训练集并不会提高模型的性能。
多特征救援
如果你一直跟着我的节奏,到目前为止,你已经完成了理解高方差和高偏差问题的功课。你可能会认为我故意留下了一些东西要讨论。是的,高偏差模型将不会受益于更多的训练样本,但是他们很可能受益于更多的特征。所以,到底这是不是都是关于增加“更多”数据的?好吧,再强调一次,这得视情况而定。
例如,在Netflix Prize的早期,有一个以评论额外特征的使用来解决问题的 博客文章 ,它是由企业家和斯坦福大学教授 Anand Rajaraman 建立的。这个帖子解释了一个学生团队如何通过从IMDB添加内容特征来改善预测精度特性。
现在回想起来,很容易在批评后作出针对一个单一数据点的粗俗的过度泛化。更有甚者, 后续文章 提及SVD是一个“复杂”的算法,不值得一试,因为它限制了扩大更多的特征的能力。显然,Anand的学生没有赢得Netflix Prize,而且他们现在可能意识到SVD在获奖作品中发挥着重要的作用。
事实上,许多团队后来显示,添加来自IMDB的内容特征等等到一个优化算法上几乎没有改善。Gravity team的一些成员,他们是Netflix Prize的最优秀的竞争者之一,发表了一篇详细的论文,展示了将这些基于内容的特征添加到高度优化的协同过滤矩阵分解的方法没有任何改善。这篇论文题为“ Recommending New Movies: Even a Few Ratings Are More Valuable Than Metadata ”。

为了公平起见,论文的标题也是一个过度泛化。基于内容的特征(或一般的不同特征)在许多情况下可以提高精确度。但是,你明白我的意思: 更多的数据并不总是有帮助的。
更好的数据!=更多的数据
在我看来,重要的是要指出,更好的数据始终更好。对此没有反对意见。所以任何你能够直接针对你的数据进行“改善”的努力始终是一项很好的投资。问题是, 更好的数据并不意味着更多的数据 。事实上,有时这可能意味着少!
想想数据清理或异常值去除,就当是我的观点一个微不足道的说明。但是,还有许多其他的更微妙的例子。例如,我已经看到人们投入大量的精力到 Matrix Factorization ,而真相是,他们可能通过采样数据以及得到非常相似的结果获得认可。事实上,做某种形式的智能人口抽样的正确的方式(例如使用分层抽样)可以让你得到比使用整个未过滤得的数据集更好的结果。
科学方法的终结?
当然,每当有一个关于可能的范式的变化激烈的争论,就会有像Malcolm Gladwell 和 Chris Anderson这样的人 以此谋生甚至未曾认真思考(不要误会我的意思,我是他们俩的粉丝,我读过他们的很多书)。在这种情况下, Anderson挑选了Norvig的一些评论,并错误地在一篇文章中引用,该文章的标题为:“ The End of Theory: The Data Deluge Makes the Scientific Method Obsolete ”。

这篇文章阐述了几个例子,它们讲的是丰富的数据如何帮助人们和企业决策甚至无需理解数据本身的含义。正如Norvig在他的辩驳中自己指出的问题,Anderson有几个观点是正确的,但是很难实现。而且结果是一组虚假陈述,从标题开始:海量数据并未淘汰科学方法。我认为这恰恰相反。
数据没有合理的方法=噪音
所以,我是在试图制造大数据革命只是炒作的言论吗?不可能。有更多的数据,无论是更多的例子样本或更多的特征,都是一种幸事。数据的可用性使得更多更好的见解和应用程序成为可能。更多的数据的确带来了更好的方法。更重要的是,它需要更好的方法。

综上所述,我们应该不理会过分简单的意见,它们所宣扬的是理论或者模型的无用性,或者数据在其他方面的成功的可能性。尽可能多的数据是必要的,所以就需要好的模型和理论来解释它们。但是,总的来说,我们需要的是好的方法,来帮助我们理解如何解释数据,模型,以及两者的局限性,这都是为了得到最好的输出。
换句话说,数据固然重要,但若没有一个合理的的方法, 数据 将会成为 噪音。
( 注 : 本文的答案基于作者此前发表的博客文章: More data or better models? )
原文链接: In machine learning, is more data always better than better algorithms? (翻译/王辉 责编/周建丁)
【预告】 首届中国人工智能大会(CCAI 2015)将于7月26-27日在北京友谊宾馆召开。机器学习与模式识别、大数据的机遇与挑战、人工智能与认知科学、智能机器人四个主题专家云集。人工智能产品库将同步上线,预约咨询:QQ:1192936057。欢迎关注。
正文到此结束
热门推荐










相关文章






Loading...
![[HBLOG]公众号](http://www.liuhaihua.cn/img/qrcode_gzh.jpg)

