sql server 2012 数据引擎任务调度算法解析(下)
上次我们说到,sql server 2012的企业版的任务调度流程,一直到给新连接分配了scheduler,都是与以前的版本算法是一致的,只有在进行任务分配的时候,算法才有了细微的调整。
新算法的目的是尽量减小在同一NUMA节点内随机分配scheduler带来的性能影响(原来的算法也不能称为随机,因为是按负载系数进行分配的,但是由于负载系数会不确定,所以暂时将原分配算法定性为:随机~~)
我们知道,在sql server 2008版本以后,引入了Resource Governor(后文简称RG),在2012版本中,微软就将Resource Governor这个特性应用到了任务调度算法中来,这里需要注意的是,如果没有开启RG功能,那么sqlos将会把default RG设置应用到算法中。
PS:如果不知道Resource Governor是什么的同学请参考MSDN: https://msdn.microsoft.com/en-us/library/bb933866(v=sql.100).aspx
如果对RG有了解,就会知道RG是一个对资源进行分配的设置选项,它可以对CPU或内存的最大、最小可用资源进行配置。
每个scheduler也都有自己的目标资源池 ,每个SCHEDULER的资源池大小基本等于RG最大配置/scheduler总数的平均值
图为default的RG设置

假设共有4个可用的scheduler,那么每个sheduler的可用cpu上限大概就是25%
必须要注意的一点是,新的调度算法 并没有将当前CPU使用率做为一个参考指标 ,换句话说,有可能一个scheduler已经占用了CPU80%的计算资源,但是在进行任务调度的时候,还是按照100/4=25%进行计算的
OK,下面我们开始说明一下新的算法流程:
当需要给task指派一个scheduler的时候,如果首选scheduler在添加这个task后,不会使得当前scheduler的平均任务资源利用率下降到当前NUMA节点内平均资源利用率的80%以下,则将任务指派给首选scheduler;反之,则将任务分配给同一NUMA节点中有最多可用资源的sheduler上。
也许这样说起来并不直观,我们用一些图例和计算说明一下具体流程
依然模拟了这样一个环境:2NUMA,四核,1433端口绑定到NUMA0,使用默认的RG设置(也就是MAX CPU=100%)
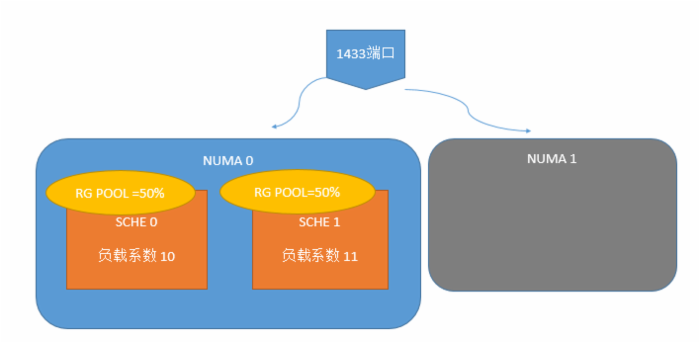
我们可以列出下表

全局的平均值则=(5.56+4.55)/2=5.05,那么80%数据值为5.05*0.8=4.04
1.
在sche1发起了一个任务分配的任务,计算公式则如下
scheduler1 avg = 50/(11+1)=4.17
我们发现4.17这个数值要高于全局平均使用率的80%(4.04),那么这个任务还是会分配给首选scheduler,也就是sche1
(这里注意:如果按以前版本负载系数的算法,则是(11+1)/9=1.33,在sche1添加这个任务,任务负载会超出sch0的20%以上,则此任务则会分配给sche0)
2.
上面的表格变为如下:
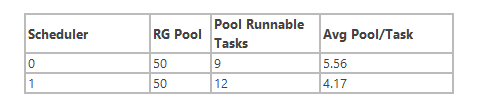
全局的平均值则=(5.56+4.17)/2=4.86,那么80%数据值为4.86*0.8=3.89
3.
接下来我们再继续在sche1上添加新的任务,计算公式则如下
scheduler1 avg = 50/(12+1)=3.85<3.89
则新的任务会分配到非首选schduler上,也就是sche0上,表格变成
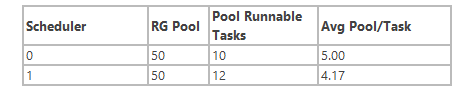
我们可以看出,通过新的算法,并没有对不同的scheduler上的任务造成过大的数量差距,而且减小了在不同scheduler上切换任务的次数
以上就是sql server 2012任务调度算法的一些基本内容
补充
在服务器启动时候,我们可以使用2个trace flag进行调度算法的指定,当然和一般的trace flag一样,如果不是特别需要且经验非常丰富的DBA,不要对这些看似高大上的参数进行调整
-T8008- 使用2012企业版之前的调度算法,也就是我在第一篇中写到的算法
-T8016- 强制指派任务到首选scheduler上(基本上等于不进行什么算法判断了)
正文到此结束
热门推荐










相关文章






Loading...
![[HBLOG]公众号](http://www.liuhaihua.cn/img/qrcode_gzh.jpg)

