低基数索引为什么会对性能产生负面影响
低基数索引
关于识别将要创建的适当索引或是识别将要丢弃的不良索引的建议有很多。以下情况看起来似乎是合乎逻辑的:某个字段(比如 account enabled )上的索引有一组极小的惟一值( yes 、 no ),这可以大幅减少结果集。根据 B-树形索引的几何结构,值较低的索引可能对性能造成实际损害,而不是帮助提高性能。
回页首
索引基数是什么?
一个表的基数就是表中的行数或是记录数。对于索引而言,基数被认为是索引中惟一值的数量。惟一索引的基数等于表中的行数。但是,非惟一索引的基数可以是从 1 到表中行数的任意数字,具体取决于每个索引键在表中出现的次数。
低基数索引就是那些惟一值相对较少的索引。 account enabled 或 published 等列很可能只有两个惟一值( yes 和 no )。此类列上的索引的基数为 2。许多表的列可以包含一个很小的惟一值子集,这些列包括 Status 、 Color 和 Currency 等,具体情况取决于所存储的数据。
想找到现有索引的基数很容易。syscat.indexes 中的 FULLKEYCARD 列包含全文索引(full index)的基数:所有索引键值的惟一组合。在一个用于确定 FULLKEYCARD 的简单查询中,可假设称作 WSCOMUSR.I0000626 的索引的当前 RUNSTATS 如清单 1 中所示:
清单 1. 用于确定索引的 FULLKEYCARD 的查询
select FULLKEYCARD from syscat.indexes where indname='I0000626' and indschema='WSCOMUSR'
通常,会在表中列出所有的索引,同时列出其基数,这样做可能更为有用。列出表名称为 WSCOMUSR.OFFER 的所有索引及其 FULLKEYCARD 以及样例输出的查询如清单 2 所示:
清单 2. 通过表列出所有索引及其 FULLKEYCARD 的查询
select substr(INDNAME,1,25) as INDNAME, FULLKEYCARD from syscat.indexes where tabname='OFFER' and tabschema='WSCOMUSR' INDNAME FULLKEYCARD ------------------------- -------------------- SQL120207194412100 29383 I0000165 29383 I0000167 29378 I0000626 6 4 record(s) selected.
回页首
B-树形索引
DB2 使用包含多个层次的 B-树形索引,从概念上讲,B-树形索引通常用三个层次表示,如图 1 所示:
图 1. 三层 B-树形索引

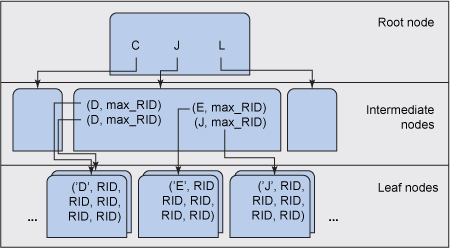
根节点是最高层次,列出了中间层中每个中间节点上表示的关键值的末尾部分。中间节点可能有多个层次,较高层次的中间节点指向其他中间节点,而不是叶节点。反过来,中间节点也指向叶节点。 节点 和 页面 这两个术语可针对 DB2 进行互换。叶级页(leaf page)保存关键值,并告诉 DB2 在表的数据页面的何处查找数据的 Record IDs (RIDs)。
对于最佳索引访问,DB2 会有一个特定的索引键,而且只需读取根页面、一个中间页面和一个叶级页。然后,DB2 会使用该叶级页上的 RID 从表数据页面中提取其他数据。RID 本身包含一个与表(SMS 表空间)或与表空间(DMS 表空间)有关的页数,以及该页面上的槽数。此访问计划允许 DB2 访问表中的任意一行,但前提条件是索引键位于一个三层索引中,只有 4 个可从磁盘读取的页面(page reads),且不用考虑表大小。
在图 1中,索引位于单个字符的一个列中。查找 E 的索引键值时,DB2 会在根节点上启动,并指向包含 D 、 F 和 J 的中间节点。然后,该中间节点将 DB2 指向包含 E 和 F 的叶节点,其中也包含 RID。 然后,将会使用 RID,DB2 直接指向表中的数据页,以获取所记录的数据。
这种表示法实际上是一个惟一索引。低基数索引从定义上来看并不是惟一的。在索引叶级页上,惟一索引的索引键和 RID 的表示法如图 2 所示:
图 2. 如何将索引项存储为叶级页上的惟一索引

在非惟一索引中,任何给定索引键只在给定页面上出现一次。非惟一索引的叶级页如图 3 所示,其中索引键的所有 RID 都以 RID 顺序存储:
图 3. 如何将索引项存储为叶级页上的非惟一索引

利用这一信息以及当多个叶级页具有相同的键时非叶级页包含每个叶级页的最高 RID 值的事实,图 1中的 B-树形索引可更改为更为精确的索引,如图 4 所示:
图 4. DB2 非惟一 B-树形索引
回页首
测量差异
当在本文中谈到 页面读取 或 页面扫描 时,并不一定就是指物理 I/O。页面访问是否只处理缓冲池中的页面,或者说代理是否只对磁盘执行物理 I/O,这些我们不得而知。大家更希望出现的是前一种情况,并希望通过预取操作实现这一点。在本文中,页面读取、页面扫描和页面处理都是同一个意思,因为本文并不会深入探讨预测将要实现的程度。显然,为了让代理为满足某个查询而从磁盘中同步读取页面会使得性能变得更糟,而且不确定的是,有一部分操作可能使得与低索引基数相关的性能结果变得不稳定。
回页首
低索引基数的假设性示例的影响
使用一个假设性示例可以说明低基数索引会成为问题的原因。
在本节的示例中,使用了相同的查询和结果集,但是随着索引基数的增长,表的大小也会随之增长,所以结果集大小仍然保持不变。
从表 1 中的简单表开始:
表 1. 第一个假设性示例的样例表的描述
| ID | 类型 | 描述 |
|---|---|---|
| 没有索引的惟一标识符 | 两个可能的值 | 一些文本 |
在表 1 中,使用清单 3 中的语法所创建的表中也有一个标准的 B-树形索引:
清单 3. 创建假设性示例的索引的语法
CREATE INDEX indname ON table1 (type);
在这个低基数索引中,假设所有值的数据都是相等或均匀分布的。
描述表的一些整数:
- 表中的 10,000 行
- 适合叶级页的 20 个索引 RID
- 适合数据页的 10 行
- 索引基数 (FULLKEYCARD) 是 2
使用全表扫描访问表可能将会执行:10,000 行 / 10 数据行每页 = 1,000 次页面扫描
最后,包含低基数索引列的简单查询中的子句如清单 4 所示:
清单 4. Sample query for hypothetical table
SELECT id, description FROM table WHERE type =‘B’
在图 5 和以下所有的图中,索引访问用红色表示,而直接表访问用绿色表示:
图 5. 第一个假设性示例的索引访问与表访问图
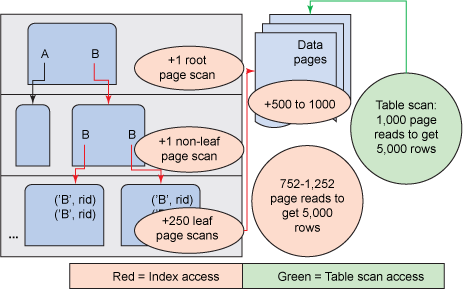
图 5显示了访问 1 个根节点、1 个中间节点、250 个叶级页,以及 500 到 1,000 之间的任意数量的表数据页面。这意味着可以利用索引采用 752-1,252 之间的任意数量的可从磁盘读取的页面数量来满足示例查询。另一方面,全表扫描可保证每次包含 1,000 个可从磁盘读取的页面。如果由 DB2 优化程序进行选择,那么索引访问可以采用表扫描使用的 75% 到 125% 之间的任意数量的可从磁盘读取的页面数量。
更改本例中的一些数字会产生有趣的结果。下一幅图检查了随着索引基数的增长以及表基数的增长而出现的情况,所以最后结果仍然返回相同数量的行。对于值的分布,仍然希望在索引中的所有值中都是相等的。修订后的表格条件如表 2 所示:
表 2. 第二个假设性示例的样例表描述
| ID | 类型 | 描述 |
|---|---|---|
| 没有索引的惟一标识符 | 4 个可能的值 | 一些文本 |
用于描述该表的整数:
- 表中的 20,000 行
- 适合叶级页的 20 个索引 RID
- 适合数据页的 10 行
- 索引基数 (FULLKEYCARD) 是 4
使用全表扫描访问表可能将会执行:20,000 行 / 10 数据行每页 = 2,000 次页面扫描
修改后的图如图 6 所示:
图 6. 第二个假设性示例的索引访问 vs 表访问图

在本例中,使用索引需要 752 到 2,252 之间的可从磁盘读取的页面数量,而全表扫描则需要 2,000 个可从磁盘读取的页面。全表扫描仍有可能比索引访问更有效,具体情况取决于表在该索引上的集群。
执行进一步的操作,并再次更改条件,同时保持结果集大小不变,这会产生如表 3 所示的表:
表 3. 第三个假设性示例的样例表描述
| ID | 类型 | 描述 |
|---|---|---|
| 没有索引的惟一标识符 | 16 个可能的值 | 一些文本 |
用于描述该表的整数:
- 表中的 80,000 行
- 适合叶级页的 20 个索引 RID
- 适合数据页的 10 行
- 索引基数 (FULLKEYCARD) 是 16
使用全表扫描访问表可能将会执行:80,000 行 / 10 数据行每页 = 8,000 次页面扫描
低基数索引中所有值的行分布等同于全部 16 个值的分布。修改后的图如图 7 所示:
图 7. 第三个假设性示例中的索引访问与表访问图

在这个示例中,可以保证索引最后的可从磁盘读取的页面数量少于表扫描。在前面的所有示例中,可从磁盘读取的页面数量可能比较少,但也可能会比较多。
前面的每一个示例都提供了一系列可能的数据页面读取数量,以供索引访问返回到数据页面。在这个范围内,实际的可从磁盘读取的页面数量取决于表在特定索引上的聚合程度。如果表已经在索引上聚合,或者接近于聚合,那么数据页面读取数量将会较低,因为数据页上将会有多个行,而且索引键的值相同。如果低基数索引中值相同的记录分布在表中的更多页面上,那么数据页面读取数量将会较高。最大可能的数据页面读取数量可以是返回行的数量,也可以是表中页面的总数。
这些示例已经过简化,消除了其他一些因素,只关注手头问题。下一节将介绍一个真实的表和索引。
回页首
低索引基数所带来的影响的真实示例
本示例来自 IBM WebSphere® Commerce 数据库中的一个基表。该表是 MBRATTRVAL,其中存储的属性与网站上的用户有关。表的行大小较小,因为 VARCHAR 很少会通过填充来持续更长时间。表的结构如表 4 所示:
表 4. MBRATTRVAL 表的描述
| 列名称 | 数据类型 |
|---|---|
| MBRATTRVAL_ID | BIGINT NOT NULL |
| STORRENT_ID | INTEGER |
| MEMBER_ID | BIGINT NOT NULL |
| ATTRTYPE_ID | CHAR(16) NOT NULL |
| MBRATTR_ID | BIGINT NOT NULL |
| FLOATVALUE | DOUBLE |
| INTEGERVALUE | INTEGER |
| STRINGVALUE | VARCHAR (4000) |
| DATETIMEVALUE | TIMESTAMP |
| OPTCOUNTER | SMALLINT |
STOREENT_ID 列上有一个索引。该列将各个条目划分成特定的 商店 ,这些商店可以是单独的电子商务网站。在本例中,只有 7 个可能的值具有不稳定的分布,如清单 5 所示:
清单 5. MBRATTRVAL 表中低基数索引值的分布
select storeent_id, count(*) as count from MBRATTRVAL group by storeent_id with ur STOREENT_ID COUNT ----------- ----------- 10152 552784 10851 4888360 10852 362532 11352 188 12002 4477 12551 338 - 22 7 record(s) selected.
需要将大量详细信息添入与假设性示例类似的图中:
- 每个表页面上的数据行的平均数量
- 索引中的级别
- 每个叶级页的索引 RID 的数量
尝试预测 DB2 优化程序将会选择的访问路径需要额外的数据,比如分布统计信息是否已收集。预测并不是此处的重点;相比之下,具有表扫描的基于索引的访问计划才是重点。
加入这三个系统的一个查询提供了所需的值,如清单 6 所示:
清单 6. 返回对低基数索引至关重要的值的查询
select CARD , (PAGESIZE-100)/(AVGROWSIZE+10) as avg_rows_per_table_page , NLEVELS , FULLKEYCARD , CASE WHEN LEVEL2PCTFREE = -1 and AVGNLEAFKEYSIZE > 0 THEN (PAGESIZE-100)/(AVGNLEAFKEYSIZE+7) ELSE -1 END as AVG_IND_RIDS_PER_NLEAF , CARD/NLEAF as AVG_IND_RIDS_PER_LEAF from syscat.indexes i, syscat.tablespaces ts, syscat.tables t where i.TBSPACEID=ts.TBSPACEID and i.tabschema=t.tabschema and i.tabname=t.tabname and indname='I0000327' and indschema='WSCOMUSR' AVG_ROWS_ AVG_IND_RIDS_ AVG_IND_RIDS_ CARD PER_TABLE_PAGE NLEVELS FULLKEYCARD PER_NLEAF PER_LEAF ---------- --------------- ------- ------------ -------------- -------------- 5719360 81 3 7 735 1156 1 record(s) selected.
这里的每个数据页面的平均开销按 100 字节估算,每个数据行的开销按 10 字节估算。每个索引 RID 的行开销按 7 字节估算。当这些数字确实来自 9.7 IBM DB2 信息中心时,它们将是一些估计值而不是精确值,因此,使用这些值计算的值很可能是大致正确,但不是完全正确。
如果这些对象包含与默认情况不同的 PCTFREE,则需要更改该查询,以便将这些情况考虑在内。
其他开销也可能会增加表或索引占据的总空间。
在本例中,81 行可能适合该表中的一个数据页,而且平均每个索引叶级页上有 1156 个 RID。
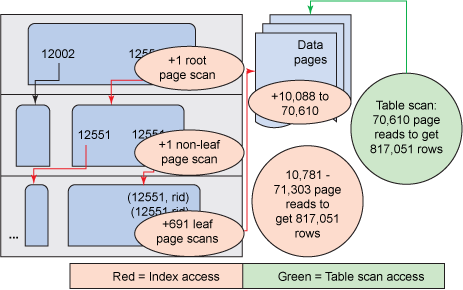
首先,如果数据正常分布在 7 个值上,请注意观察图的变化。图 8 显示了将数据插入与假设性示例中所用的图类似的图中的情况。由于这种平均分布,所以该示例仍然属于假设性示例。以后的示例将会更接近于真实示例。
图 8. 真实示例中,全文索引键的均匀数据值分布图
假设在本例的查询中提供了静态值。查询如清单 7 所示:
清单 7. 均匀分布示例中使用的查询
select MBRATTRVAL_ID, MEMBER_ID, ATTRTYPE_ID, MBRATTR_ID from MBRATTRVAL where STOREENT_ID=12345 with ur
与完全的假设性示例类似,所以可能会减少可从磁盘读取的页面数量,也可能会增加该数量。在常态分布中,索引可能会读取数量为 10,781 到 71,300 之间的数据页面,并获取 817,051 条记录。不使用索引来检索相同数据的表扫描将使用 70,610 个页面。
现在,请查看包含频繁出现的数值和非频繁出现数值的同一个图。
首先,出现频率较低的是:12002,出现了 4,477 次。所有的查询如清单 8 所示:
清单 8. 低频示例中使用的查询
select MBRATTRVAL_ID, MEMBER_ID, ATTRTYPE_ID, MBRATTR_ID from MBRATTRVAL where STOREENT_ID=12002 with ur
图表如图 9 所示:
图 9. 真实示例中低频值的图

如果指定的值低于频率,那么 DB2 使用索引(62 到 4,483 之间)读取的页面明显少于使用表扫描 (70,610) 读取的页面。在本例中,低基数索引有助于减少读取的页面数量。
最后,频率最大的值:10851,出现 4,888,360 次。所用的查询如清单 9 所示:
清单 9. 低频示例中使用的查询
select MBRATTRVAL_ID, MEMBER_ID, ATTRTYPE_ID, MBRATTR_ID from MBRATTRVAL where STOREENT_ID=10851 with ur
图表如图 10 所示:
图 10. 真实示例中高频值的图
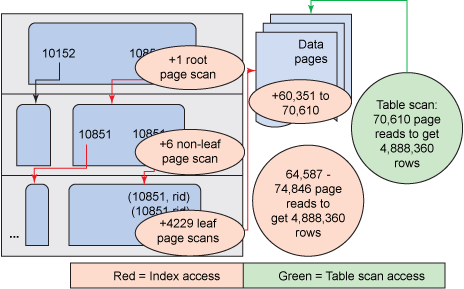
在最后一幅图的情况下,索引最多保存 10,259 个可从磁盘读取的页面(70,610 个表扫描页数减去 64,587 个最佳情况下的总索引访问页面),而它最少将使用额外的 4,236 个可从磁盘读取的页面(70,610 个表扫描页面减去 74,846 个最坏情况下的总索引单位页面)。
这些图展示了 3 个要点:
- 索引访问可能会添加更多的可从磁盘读取的页面,尤其在使用频繁出现的值时。
- 了解了数据在特定索引上的聚合程度,这对了解实际索引可从磁盘读取的页面数量所在的范围至关重要。
- 包括分布统计信息的当前统计信息非常重要,所以 DB2 不希望先进行正态分布,然后再获取其他信息。
低基数索引提供的性能不稳定,具体情况取决于表中的值和索引集群的频率。创建索引时,DBA 并不总能了解是使用频繁出现的值还是使用不太频繁出现的值。
回页首
低基数索引如何影响插入、更新和删除
对于非惟一索引,每个索引键在每个叶级页上只出现一次。这样可以节约大量的存储空间,而在以前的计算中,还可以显示出每个叶级页(真实示例中为 1156)中存储的项目数和非叶级页(真实示例中为 735)中存储的项目数的区别。这也有助于降低索引占据的空间。
虽然压缩不在本文的讨论范围之内,但如果压缩索引,该空间和可从磁盘读取的页面数量也可以进一步减少,因为 DB2 不需要存储全部 RID,而只存储 RID 之间的差异。
在以前的版本中,通过使用类型 1 索引,在对索引键进行更新时,仅对一行进行了插入、删除操作,因此 DB2 需要扫描整个 RID 列表。通过类型 2 索引,为每一个索引键将 RID 存储在索引中。DB2 还在索引的非叶级页上存储了与每一个较低级页面相关的最多 RID。在这个上下文中,认为 RID 就像索引键中的另一个列。当键的第一部分匹配时,DB2 可以为 RID 导航索引。这就意味着对于每一个已更新的行,DB2 需要访问索引根页面、索引中间页面和索引叶级页。然后,DB2 在叶级页上执行二分搜索法,以查找其要寻找的 RID。这可能会对每个三级索引的插入、更新和删除添加 3 个可从磁盘读取的页面,从而使得在这一区域中非惟一索引的处理与惟一索引的处理类似。这就是为什么所有可能帮助选择性能的索引都有可能会损害插入、删除,有时还会损害更新性能。
索引键值的更新需要先定位要更新的行的 RID,删除该 RID,然后再将该 RID 插入索引中的恰当位置。如果 PCTFREE 和后续活动已经允许在定位页面上存在可用空间,那么将会只添加 RID。如果不允许,则需要添加一个新叶级页至索引结构,还需要相应地更新非叶级页。默认的 PAGE SPLIT 行为很可能会包含逐渐接近从某一页到新叶级页的一半的索引行。这项更新处理更倾向于关注频繁更新的值。“published” 或 “store_id” 这样的列可能不会经常变化,但更新处理可能更关注那些发生变化的列(例如,“order status”)。
插入操作需要搜索整个 RID 列表,以查找在 RID 列表内的正确顺序,但同样的,在 DB2 已经遍历 B-树形索引结构后,该搜索就会位于叶级页上的列表内。这有时可能会以类似更新的方式产生额外的叶级页。
回页首
利用低基数索引避免问题
本文已经介绍了定义低基数索引可能帮助还是损害特定语句的性能的多个因素。
与表的行大小相比而言较大的行大小
当适合索引页的索引键数量接近于适合数据页的数据行数量时,索引访问可能会引入额外的可从磁盘读取的页面,而这些读取本应该由全表扫描执行。要想比较表行大小和索引行大小,可使用类似清单 10 中的查询来查看特定表的所有索引:
清单 10. 对比索引键大小和表行大小的查询
select substr(t.TABNAME,1,12) as tabname , substr(i.INDNAME,1,20) as indnameA , AVGROWSIZE as RSIZE , AVGLEAFKEYSIZE as KSIZE , 100*(DECIMAL((FLOAT(AVGLEAFKEYSIZE)/FLOAT(AVGROWSIZE)),7,5)) as PCT_OF_ROWSIZE from syscat.indexes i, syscat.tables t where i.tabschema=t.tabschema and i.tabname=t.tabname and type='T' and AVGROWSIZE>0 and t.tabname='SRCHTERM' and t.tabschema='WSCOMUSR' order by PCT_OF_ROWSIZE desc with ur TABNAME INDNAME RSIZE KSIZE PCT_OF_ROWSIZE ------------ -------------------- ------ ----------- -------------------- SRCHTERM I0001400 57 46 80.70100 SRCHTERM SQL120212225636730 57 41 71.92900 SRCHTERM I0001402 57 8 14.03500 SRCHTERM I0001401 57 4 7.01700 4 record(s) selected.
在考虑比较索引行大小和表行大小时,该数据会派上用场。许多低基数索引也有非常小的索引键,所以将此数据与计算索引基数结合使用,就可以更容易地在现有数据库中将有问题的低基数索引过滤至可管理的数量。
数据和频繁出现值的不均匀分布
要想根据此数据来分析索引,那么了解在编写可能使用低基数索引的查询时应用程序会使用哪些值就很重要。编写返回值及其频率的查询非常容易,但该查询将会依赖于表结构。清单 11 显示了这样的一个示例:
清单 11. 在全部索引键中查看数据分布的示例
select storeent_id, count(*) as count from MBRATTRVAL group by storeent_id with ur STOREENT_ID COUNT ----------- ----------- 10152 552784 10851 4888360 10852 362532 11352 188 12002 4477 12551 338 - 22 7 record(s) selected.
在本例中,可能的值是偏态分布的;这意味着索引很可能提供不稳定的性能,而且在加速处理最频繁出现的值时,很可能会降低查询速度。如果分布统计信息已经收集完毕并供查询使用,那么它们将有助于减少查询中出现的值。
表中的数据不能很好地聚集在低基数索引上
在本文的示例中,如果表在索引上的聚集程度很好,那么低基数索引性能更可能优于表索引。这实际上可能会改变您选择集群索引的战略,如果有一个被频繁使用性能关键查询进行查询的低基数列,那么就值得将其转变为集群索引,或者是用该索引识别表。还有适用于集群索引和集群重组的其他一些考虑因素,但这些都不在本文的讨论范围之内。
如果已经收集了详细统计信息,那么 SYSCAT.INDEXES 中的 CLUSTERFACTOR 列就会保存该信息。如果没有详细的统计信息,那么 CLUSTERRATIO 列就会保存该信息。
清单 12 显示了在特定表中查找该信息的查询:
清单 12. 查找集群信息的查询
select substr(INDNAME,1,18) as indname, decimal((100*CLUSTERFACTOR),5,2) as CLUSTERFACTOR from SYSCAT.INDEXES where tabname='ORDERS' and tabschema='WSCOMUSR' with ur INDNAME CLUSTERFACTOR ------------------ ------------- SQL120212212527630 80.75 I0000176 77.00 I173124 90.74 I0000652 88.68 I0000653 100.00 I0000654 94.98 I0000892 100.00 I0000933 100.00 I0001267 100.00 9 record(s) selected.
数字越接近 100,表在该索引上的聚集程度就越好。
具有极低基数的索引
与表的基数相比,索引的基数越低,索引发挥其作用的可能性就越小。由于此处的其他所有因素,没有哪个神奇的数字可以定义基数极低的索引。我将仔细观察 FULLKEYCARD 低于表基数的 5% 的所有索引。要对表上的索引执行这一计算,请使用清单 13 中所示的查询:
清单 13. 检查与表 CARD 相关的索引 FULLKEYCARD 的查询
select substr(INDNAME,1,18) as indname, CARD, FULLKEYCARD, decimal((100*(float(FULLKEYCARD)/float(CARD))),5,2) as card_pct from SYSCAT.INDEXES i, SYSCAT.TABLES t where t.tabname=i.tabname and t.tabschema=i.tabschema and t.tabname='ORDERS' and t.tabschema='WSCOMUSR' with ur INDNAME CARD FULLKEYCARD CARD_PCT ------------------ -------------------- -------------------- -------- SQL120212212527630 929728 929728 100.00 I0000176 929728 904244 97.25 I173124 929728 150612 16.19 I0000652 929728 160047 17.21 I0000653 929728 1 0.00 I0000654 929728 2 0.00 I0000892 929728 1 0.00 I0000933 929728 1 0.00 I0001267 929728 1 0.00 9 record(s) selected.
分布统计信息尚未收集,或者参数标记不允许 DB2 使用分布统计信息
DB2 优化程序不负责执行此操作,也无法确保不选择需要更多数据页的访问计划?哦,是的,它经常这么做。但是优化程序只是与数据和可用的统计信息一样。优化程序也会出现错误。
要想找到真正适合数据的访问计划,请收集所有索引上的分布统计信息和详细统计信息。此外,如果使用参数标记(显示在 ? 之类的数据包缓存中的查询中),则会禁止 DB2 正确使用分布统计信息。DBA 可以控制收集哪一类的统计信息,但有可能无法控制参数标记的使用。让开发人员和供应商选择使用参数标记是有很多优势的。
真正的问题会在 DB2 需要假定分布是标准分布时出现,随后提取的结果也会有偏差,可以造成分类溢出或其他方面的影响,这些影响会不时地严重影响到某些查询示例的性能。
添加列来扩大索引基数
虽然最好的索引通常是经过深思熟虑后采用的复合索引,但有时候人们也会在低基数索引中随意添加一些列,目的是为了让索引的基数效果变得更好。这样可以帮助解决插入、更新和删除的问题,但会花费更多的时间来进行选择。如果列是作为索引中的引导列进行添加的,那么索引无法提供查询,也无法指定添加的列。索引占据了相当大的空间,因而需要 DB2 读取更多的页面。
查询也需要通过添加一个列来支持仅限索引的访问,或者帮助满足查询的其他条件,这样做非常有效,而且可能是一个不错的选择。
回页首
结束语
低基数索引主要通过两种方法对性能产生不利影响。首先,如果 DB2 优化程序未在适当的情况下选择使用低基数索引,则会造成性能不稳定。如果未使用分布统计信息或者统计信息不可用,那么很有可能会出现这种情况。其次,低基数索引会对其他索引执行的插入、更新和删除操作造成同样的性能影响。如果优化程序未使用低基数索引,那么它很有可能会浪费用于维护的磁盘空间和系统资源。当非惟一索引的插入、更新和删除行为是类型 1 索引行为的改进时,它仍然会以积极的方式对极少使用的索引的插入、更新和删除操作的性能带来负面影响。
本文中的方法有助于识别存在严重潜在问题的索引,删除这些索引,或者避免在一开始就添加这些索引。如果低基数索引确实会出现在数据库中,那么它对确保收集和使用分布统计信息,为 DB2 优化程序提供最有效地使用这些索引所需的信息也至关重要。
正文到此结束
热门推荐










相关文章

近期评论
-
你这基本没有更新呀,最近文章显示还是2019年的文章。不符合要求哈
-
关键词:慕云博客 链接:https://www.lilun.me 描述:分享原创文字的个人博客
-
-
-
可以提供一下源码吗
-
不是商业站,鸡娃学习笔记
-
-
-
-
听他们说很厉害的样子
Loading...
![[HBLOG]公众号](http://www.liuhaihua.cn/img/qrcode_gzh.jpg)

