大流量的下兜底容灾方案
原文地址: http://www.barretlee.com/blog/2015/09/16/backup-solution-at-big-traffic/
随着网络的普及,上网的成本和门槛越来越低,很多网站的流量也是蹭蹭蹭的往上涨,而页面上的数据来源也不确定,可能来自多个平台,也可能是有专门的人员在手动维护。由于数据来源众多,出错的概率也会增加,为了降低页面在大流量下的维护成本,本文做了一些阐述。
兜底容灾的必要性
一个日均承载几千万上亿流量的网页,会经常出现哪些问题呢?
- 某个接口挂了,前端拿不到数据或者拿到的数据不够,页面展示就会出问题,出现空白或者某个模块直接天窗。
- 用户因为网络问题或者安装了某些插件,导致页面广告、接口请求挂掉,从而页面出现问题
前者的概率不是很大,因为网页上的请求 QPS 都是预先评估过的,只要前端请求没有成倍激增,并且后端压力都在系统监控范围内,不会出太大的岔子。但是一旦出问题,页面上就有可能空白一大块,如果后端排查和处理问题不及时,很可能从小问题演变成故障。
第二个问题也是比较严峻的,据统计,不管网站做的多简洁,总是会有千分之一的用户因为网络或者浏览器插件问题导致页面访问失败或者部分接口请求失败,比如一个 pv 一亿的网站,按照千分之一计算,一个接口每天会有 10w 左右的 pv 请求失败,而请求接口一多,页面上整体的请求失败量就很高了,这个数据会达到几百万。
如何兜底,如何容灾
兜底容灾的方案有很多,目的就是让请求失败而页面展示依然正常。下面说一说常用的几个方案:
1. 再请求一次
照顾到用户体验,同时也考虑到一个请求的正常发送、接受时间,我们把超时时间设置为 5s,超过 5s 或者请求的结果状态为 failed ,则重新请求一次。所以我们可以重新封装下 Ajax 模块,如:
// 设置请求次数 var tryTimes = 2; Ajax({ url: url, timeout: 5000, dataType: "jsonp", // try tryTimes: tryTimes }); 这种处理方案对于提交订单、选中商品到购物车的页面比较合适,因为操作流是确定的,提交一次不成功,很自然的想到再提交一次,只是用户等待的不同阶段应该用不同的文案来提醒。而对于展示类的数据请求,不太适合多次失败尝试。所以首页未采用这种方案。
2. 缓存每一次请求到本地
现在的浏览器都支持本地储存(无论使用 userData 还是 localStorage),当每次请求到达用户浏览器的时候,把请求的数据缓存一份到本地储存,那么下次请求失败就可以使用上次的数据啦~
Ajax({ url: url, dataType: "jsonp", success: function(data){ // 缓存数据到本地 cache(DATAKEY, data); show(data); }, error: function(){ // 请求失败,获取本地缓存数据 var data = cache(DATAKEY); show(data); } }); 这种方式是比较常用的,每次请求成功都会缓存最新的数据。不过这里存在两个问题:
- 如果用户第一次访问就失败了呢?要知道新用户是比较多的。
- 缓存的数据是否具有时效性,如果过期了呢?比如是一个推荐接口,推荐的商品用户已经购买过了,但是访问的时候接口挂掉,依然现实用户购买过的商品,这个逻辑是不太能接受的。
当然,有总比没有好吧,就算是第一次访问,这个概率是相当低的,就算数据过期,但是依然是正确的链接,所以基本可以接受。
3. 备用接口(硬兜底)
会给自己的网页接口准备备用接口的网站,估计不会很多。我们可以做一个包装:
Ajax({ url: url, // 备份接口 backUrl: backUrl }); 一旦请求失败,进入备用数据接口请求备份数据。同样的,这里也存在一个问题:如果接口是个性化的,则每个用户访问这个接口拿到的数据都不一样,那么这个备份接口该如何推数据?如果备用接口的数据跟正常接口一样,那还不如直接去请求两次。
所以这里提到的备用接口,主要是数据的硬兜底,硬兜底的来源有两个:
- 运营维护一份数据,推送到 CDN,每一份数据都有一个固定的地址
- 后端向 CDN push 一份通用数据。我们知道个性化都是使用 cookie 去识别用户的,对于没有浏览器记录的新用户就没有 cookie,此时会推一份通用的数据,这个通用的数据也可以作为接口的备份源。
兜底容错实践
我们很容易得到如下的操作流程:

而这里存在的问题是:
- 获取缓存数据后,不好对数据格式进行判断,一般来说,只有有效的数据才能存到本地储存中,而判断是否有效往往存在误差
- 兜底数据没有及时更新
- 程序只会报警,但是不会自动修复
存在的隐患是:
- 前端每次改版,如更换接口、更换人员,兜底数据没有及时更新
- 如果兜底数据也存在错误,则页面一定出现空白天窗
所以对整个流程做了一些改进:
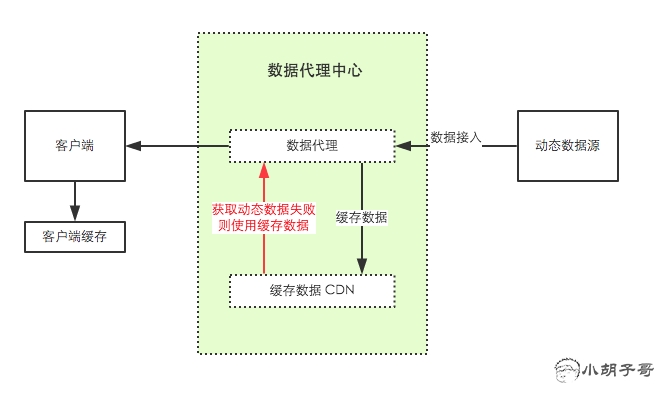
数据经过统一平台输出,在输出之前,我们将数据推一份到 CDN 作为备份,产生另一个接口,一旦原始接口请求失败,则直接请求备份的接口,这个在规则对应和即时更新上可以做到很赞!那么基本的流程就是这样:

不过为了确保无误,我的建议是,页面上每个接口必须对应一个运营手填的数据,这个作为最后的硬兜底,而这个硬兜底也会被缓存到本地,整个流程就形成一个闭环。那么,剩下的工作就只有监控和警报了。
下面是一串伪代码:
var url = interfaceURL; var backUrl = interfaceBackURL; var hardBackUrl = hardDataURL; var cacheTime = 10day; Ajax({ url: url, backurl: backUrl, success: function(){ // 缓存数据到本地 cache(DATAKEY, data, cacheTime); show(data); }, error: function(){ // 请求失败,获取本地缓存数据 var data = cache(DATAKEY); if(data) { Reporter.send(/*WARN*/); show(data); } else { Reporter.send(/*ERROR*/); _failed(); } } }); // 请求硬兜底 function _failed() { Ajax({ url: hadrBackUrl, success: function(data){ // 缓存数据到本地 cache(DATAKEY, data, cacheTime); show(data); }, error: function(){ Reporter.send(/*SUPER_ERROR*/); show(data); } }); } 注意到,我们在上面使用了缓存失效时间,考虑到数据的及时性,设置为 10 天。backUrl 是 url 的备份地址,hardBackUrl 是运营填写的备份数据,整个流程都在闭环之中,所以出问题的概率就大大降低了,即便是后端接口出错,我们也可以看着监控信息,放心的给后端开发GG打个电话,告知下等待修复,而不是急急忙忙,抓耳挠腮,担惊受怕天窗来了。
小结
本文提供的都是伪代码,而这些伪代码的实现并不复杂,也没必要写成组件,主要是提供思路,如何处理大流量高并发下的异步数据接口的兜底容灾。
如果你有更好的想法,可以提出来,一起交流下~
正文到此结束
热门推荐










相关文章






Loading...
![[HBLOG]公众号](https://www.liuhaihua.cn/img/qrcode_gzh.jpg)

