Spam Or Ham读书笔记
《Machine Learning Projects for .NET Developers》 书中的第二章,用了朴素贝叶斯的方法来识别短信是垃圾信息还是正常信息。
章节从零开始讲,所以在最开始考虑如何入手这个问题。分析了测试数据,发现垃圾短信有一些在正常短信中不太会用到的单词,用了 FREE (全大写)做测试。最后发现结果感人,有85%的正确率。将此作为beseline,接下来用更科学的方式,再怎么差也不能比baseline差。
通过决策树,分析通过垃圾短信中有FREE的概率能不能反推得到短信中有FREE这个词,这条短信是垃圾短信的概率是多少。开始引入(朴素)贝叶斯定理。
公式比较简单易懂:
P(A|B) = P(B|A) x P(A) / P(B) 又只用FREE一个单词似乎不科学,那可以使用多个单词,多个单词出现的概率独立。那就可以使用公式
P(A and B) = P(A) x P(B) (A B相互独立 也就是交集是空)
let laplace count total = float (count+1) / float (total+1) 也就是对分子分母各加1,这个函数本身不会改变原先结果的大小关系,所以使用也没什么问题。
直接使用公式计算不是很方便所以要对公式进行化简。具体化简的过程可以参考书本,我这里只给出最后的结果:  制定的工作流:
制定的工作流: 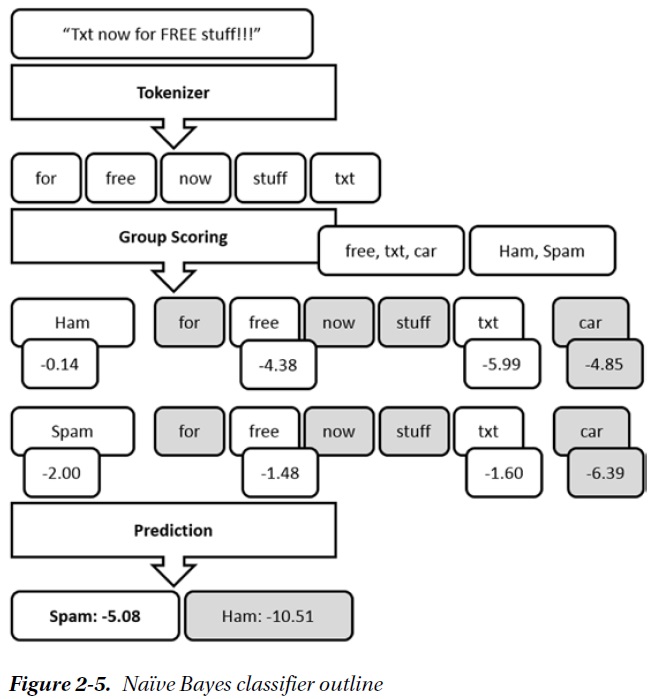
上面free、txt是通过实现分类器,给定一些用来做分类的token(这里就是free和txt),统计训练集得到每个token的 Laplace(SMS contains token|spam) 和 Laplace(SMS contains token|ham)
然后对实际数据进行上面score函数的运算就可以了
第一个实现,分词器用了最简单的取每个单词并且小写化,用了一个单词txt做分类用的token(也就是流程图里只有txt),得到的结果是86%(小数点后面我不记得了...86.5%好像...)
可以发现实现比baseline好了一点,但还是不够。接下去考虑优化。
使用测试数据里所有的token作为分类用token,结果效果更差了,所以token的选择要更有针对性。
把分词器变为取每个单词,不区分大小写,考虑到垃圾短信常常使用全大写的单词,效果所有提升。
在第一个优化中,想到free主要出现在垃圾短信中,所以可以考虑取垃圾短信和正常短信的出现次数top N的token,得到的结果达到90%。
分析top N的token,发现会有一大堆you、the、in之类的词,考虑用停用词。最后简化将垃圾短信和正常短信的top N的结果取交集得到都出现的词,然后取并集,再去除之间的交集。代码如下:
let topHam = ham |> top (hamCount / 10) casedTokenizer let topSpam = spam |> top (spamCount / 10) casedTokenizer let topTokens = Set.union topHam topSpam let commonTokens = Set.intersect topHam topSpam let specificTokens = Set.difference topTokens commonTokens 结果就更好了。
接下去的优化分析了出现最少的topN token,分析到垃圾信息中会有大量的电话号码,而正常短信中更多的是一些数字。针对电话号码做单独的处理,修改分词器,让分词器再检查到电话号码时变为一个统一的token __PHONE__ ,取这个名字是不想让普通的token和他冲突。得到了更好的结果。
后来的优化涉及到考虑短信的长度,因为短信的长度是一个连续的值,所以对其用区间的方式变为几个分离的值。接着套用贝叶斯的方法。 P(长度的分类/Spam) -> P(Spam/长度的分类) ,加入到上面的公式当中。效果我忘了,因为看书的时候这部分好像被我跳过自己没敲代码。
最后是关于错误率带来的影响的问题,是识别垃圾更重要还是识别正确信息更重要。后来得到正确短信的识别率更重要。于是可以将正确短信的topN token的N变大一些(除以的百分比变小),垃圾的N小一些。
最后是总结。
正文到此结束
热门推荐









相关文章

近期评论
-
谢谢
-
https://www.newcmy.com/register?aff=HBVX建议您试试草莓云机场,可以流畅观看youtube和tiktok,上reddit/x也没有问题,还有各种ai优化节点。
-
-
-
想购买您这个站,我的联系方式QQ741756694微信同步 能卖联系
-
-
-
-
-
https://www.liuhaihua.cn/archives/40657.html 这篇博客中的图片打不开了
Loading...
![[HBLOG]公众号](https://www.liuhaihua.cn/img/qrcode_gzh.jpg)

