用插件来提升Elasticsearch过滤效率
Elasticsearch的查询方式
es是个基于lucence的全文搜索引擎,查询主要由两种组成:查询(query)和过滤(filter) 。
在查询方面,query和filter语句可以实现数据搜索功能,而query上独有的权重设计则让返回的数据在排列上更具灵活性,这是相对与sql语句的order来说的。Filter主要应用于对query返回的数据记录进行两次查询,由于它不考虑基于权重的打分,所以速度较快。
query查询会根据查询条件匹配符合条件的记录,并且根据记录中字段的权重(weight)计算分值(scroe), 分值越高就代表越匹配,在返回的结果集中就会排在更前面。
filter过滤同样会根据查询条件匹配符合条件的记录,但它不会去计算任何分值,也不会关心返回的排序问题,因此效率会高一点。而且在默认情况下,过滤不会保存缓存结果,如果常用,需要指定 "_cache" : true来打开缓存,这样下次相同条件下的查询可以加快速度。(注:实际使用时相同查询条件前提下,不指定也可以加快速度)
假设存在多个查询条件(比如:同时存在条件A和条件B) 的情况下,这时原则上使用查询和过滤是等价的,但在某些场合下使用过滤可以优化查询。如果匹配条件A的结果集是一个很小的集合,这是在集合上做对条件B的过滤的话,性能肯定优于对整个数据集做同时匹配条件A和条件B的查询。原理图如下:
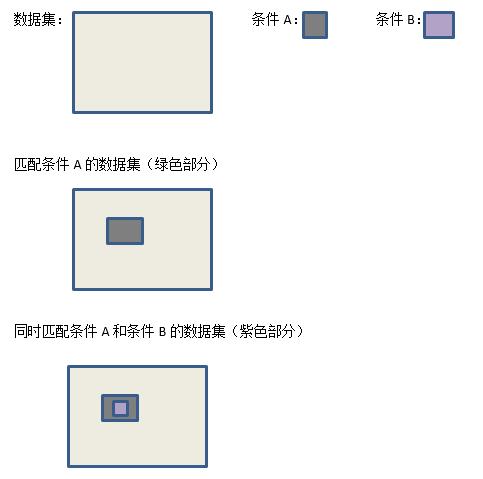
可以想象如果匹配条件A的数据集几乎等同于原数据集的场合下,那么先查询条件A后过滤条件B的方式等同于对整个数据集做同时满足条件A和条件B的查询。
适用场景
两个表的关联查询在sql中一句话就可以实现,但在es中就比较麻烦了。
虽然es官方文档支持两个表的关联查询(parent-child关系),但必须在插入数据时实现两个表在key上的关联,实现非常麻烦,而且不是很灵活。使用自定义filter的话,可以通过对某表查询返回的数据上(query语句实现)进行第二次过滤,达到对多表关联查询的目的。我的这种方法是解决多表关联查询的方案之一。
两种查询方式的DSL语句
1. 首先在es中建立索引和文档,然后加入测试数据。
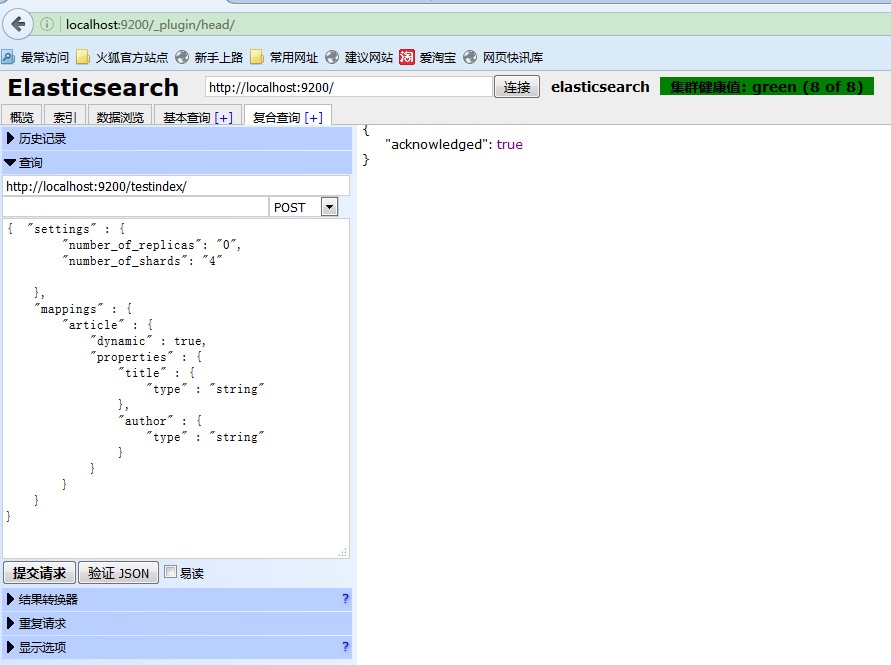
在es的head插件中输入建立索引和文档的语句:
http://localhost:9200/testindex { "settings" : { "number_of_replicas": "0", "number_of_shards": "4" }, "mappings" : { "article" : { "dynamic" : true, "properties" : { "title" : { "type" : "string" }, "author" : { "type" : "string" } } } } } 建立索引名为testindex的索引.
文档名为article. 包含两个字段:title,author,类型都是string
如图所示:
(点击放大图像)
2. 添加数据入文档。
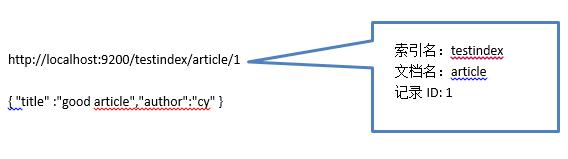
如图所示:
(点击放大图像)
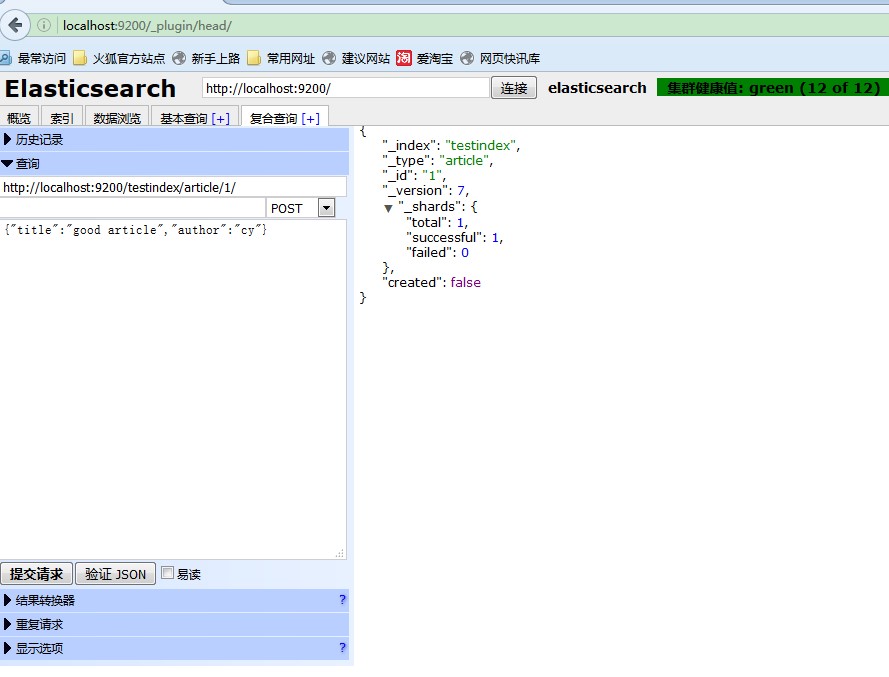
以此类推,再加入若干条数据,结果如下:
索引:testindex 文档:article 字段:id title author 1 good article cy 2 good article2 cy2 3 good article3 cy3 4 bad article pt
最后如下图所示。
(点击放大图像)
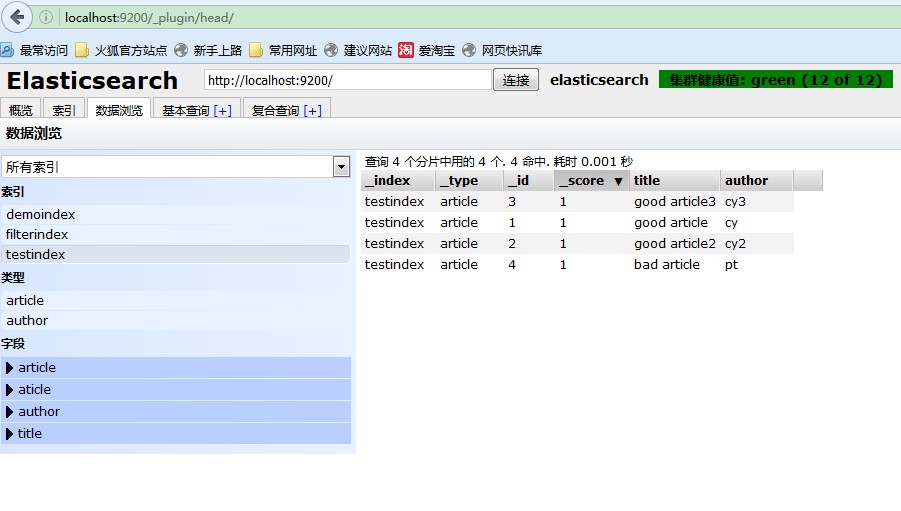
2. 同时满足条件A和条件B的查询DSL
http://localhost:9200/testindex/_search/ { "query": { "bool": { "must": [ { "term": { "title": "good" }}, { "term": { "author": "cy" }} ] } } } Es中使用分词进行查询匹配,作者在建立文档的字段时没有特别指定使用哪种分词,默认是单词完全匹配,结果如下所示:
显示id=1的那条记录完全匹配
(点击放大图像)
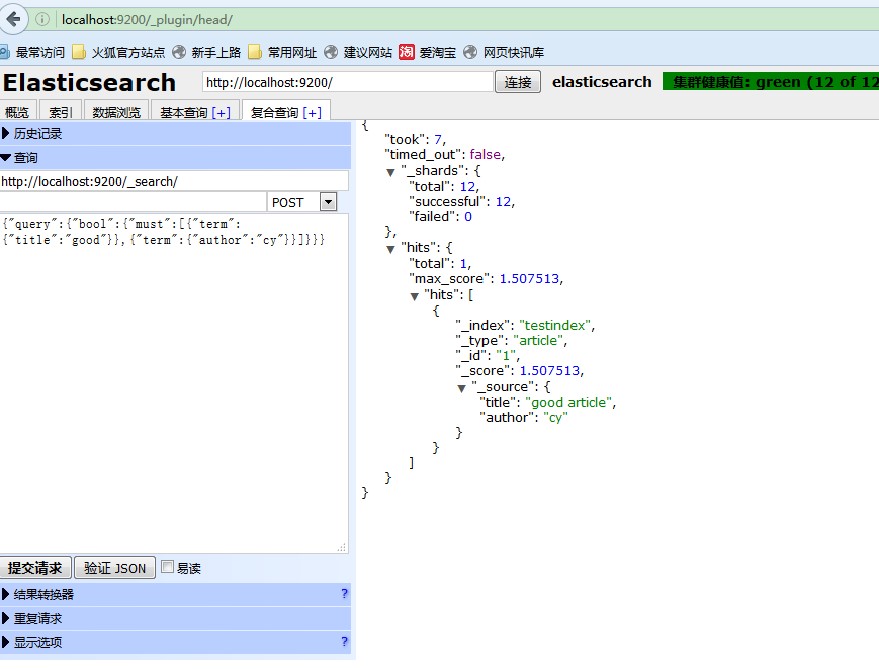
3. 先查询条件A后过滤条件B的DSL
http://localhost:9200/_search/ { "query": { "bool": { "must": [ { "term": { "title": "good" }} ], "filter": [ { "term": { "author": "cy" }} ] } } } 结果如下所示:
同样显示id=1的那条记录完全匹配
(点击放大图像)

使用定制过滤(filter)
如果需要使用复杂的查询(无需考虑权重),或者需要查询外接数据源(如需查询sql server),可以通过使用定制的过滤(filter)实现。
语句如下:
http://localhost:9200/testindex/_search { "query": { "bool": { "must": [ { "term": { "title": "good" }} ], "filter": [ {"demofilter":{"author":"cy"}} ] } } } 注:前两个语句没有在url中指定index名,由于使用的是默用的查询和过滤,执行速度依然快过在url中指定index名(testindex)的定制过滤(demofilter)查询DSL
结果如图所示:
(点击放大图像)
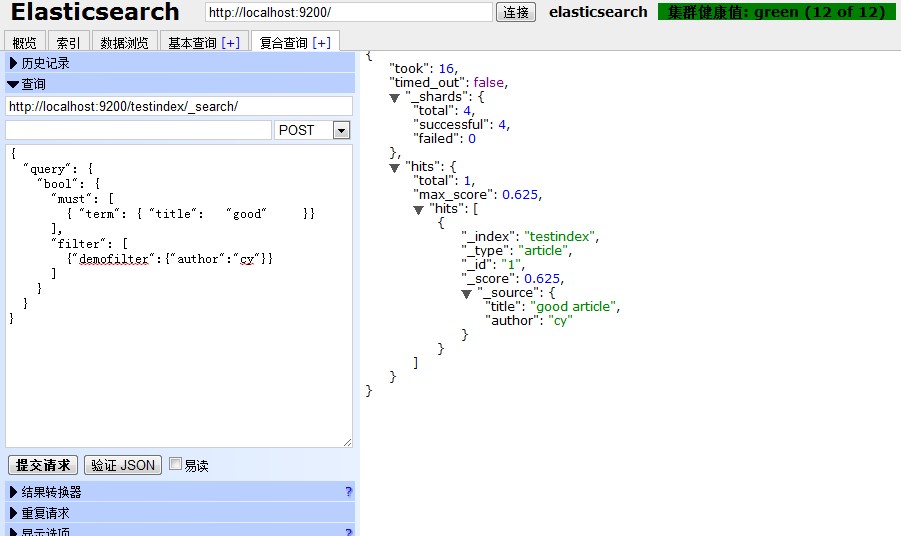
三个语句在效果上是完全等价的,在执行速度上如下所示
A:同时满足条件A和条件B的查询DSL,花费7毫秒
B:先查询条件A后过滤条件B的DSL,花费3毫秒
C: 使用定制过滤的DSL,花费16毫秒
结论:使用定制过滤最花费时间,但同时也更灵活,适应更复杂的场景。
A,B,C的查询结果是一样的,但是得分(score)不一样。其中A查询中的两个
字段都会被es计算权重(默认为1),因此得分(1.507513)相对比B和C都高,如果调整字段的权重,那最后相应的得分也会改变。在B,C中过滤的字段是不被计算
权重的,得分相对较低(都是0.625).
定制过滤(filter)的程序实现
在编写es插件时,参考了ik分词插件,这里表示感谢。
代码已放入guthub, url: https://github.com/chensed/my-first-github
注:es版本变化较大,es1.x版本的插件和2.x的插件实现还是有较大差别。
es(2.11版本) 的过滤插件主要继承了3个类。
Plugin类:所有插件的入口,当 es在插件描述文件(plugin-descriptor.properties)中扫描到XXXcustomizedplugin(继承自Plugin类),es会装载这个类,用户可以在过载函数中登记定制的parser。代码如下:
public void onModule(IndicesModule module) { module.registerQueryParser(FilterDemoParser.class); } QueryParser类:过滤分析类,用户可以继承此类实现以下两个主要功能。
1. 标识过滤的关键词
public static final String NAME = "demofilter"; @Override public String[] names() { return new String[]{ NAME }; } 2. 分析并得到参数,启动过滤类
Filter@Override public Filter parse(QueryParseContext parseContext) throws IOException, QueryParsingException { XContentParser.Token token; String name=null; String value=null; HashMap mp=new HashMap<String,String>(10); while ((token = parseContext.parser().nextToken()) != XContentParser.Token.END_OBJECT) { if (token==XContentParser.Token.FIELD_NAME) continue; name=parseContext.parser().currentName(); value=parseContext.parser().text(); mp.put(name, value); //将参数保存到hashmap,本例name=author ,key=cy } return new DemoFilter(mp); } Filter类:过滤类,用户继承此类,实现的主要功能就是从reader接口中得到数据,然后在数据记录上设置比特位过滤数据:”1”代表需要这条记录,“0“代表不需要这条记录。
代码如下所示:
@Override public DocIdSet getDocIdSet(LeafReaderContext context, Bits acceptDocs) throws IOException { long startTime = System.currentTimeMillis(); int max = context.reader().maxDoc(); //得到记录条数 OpenBitSet bits = new OpenBitSet(max); //根据记录条数初始化bit集合 DocsEnum termDocs =null; String name=null,val=null; if (paramMap.size()==1){ //从参数map中得到参数,从reader接口中得到数据进行过滤 Iterator iter = paramMap.entrySet().iterator(); if (iter.hasNext()) { Map.Entry entry = (Map.Entry) iter.next(); name = (String)entry.getKey(); val = (String)entry.getValue(); } termDocs =context.reader().termDocsEnum(new Term(name,val)); } if(termDocs == null){ return null; //不符合过滤条件的返回空,相当于比特位为0 } while(termDocs.nextDoc() != DocsEnum.NO_MORE_DOCS){ bits.set(termDocs.docID()); //得到符合过滤条件的docid(记录key), 在设置相应比特位为1 } return bits; //返回bit集合 } 作者介绍
陈渊 ,上海酷宝信息技术有限公司担任搜索引擎工程师, 关注搜索引擎,大数据挖掘。
感谢杜小芳对本文的审校。
给InfoQ中文站投稿或者参与内容翻译工作,请邮件至editors@cn.infoq.com。也欢迎大家通过新浪微博(@InfoQ,@丁晓昀),微信(微信号: InfoQChina )关注我们。
正文到此结束
热门推荐










相关文章





Loading...
![[HBLOG]公众号](https://www.liuhaihua.cn/img/qrcode_gzh.jpg)

