理解 Python 并发编程一篇就够了(线程篇)
 前言
前言
编程的乐趣之一是想办法让程序执行的越来越快,代码越写越优雅。在刚开始学习并发编程时,相信你它会有一些困惑,本来这是一篇解释多个并发开发的问题并帮助你快速了解并发编程的不同场景和应该使用的解决方案的文章,但是受微信文章长度限制和笔者对阅读体验的担心,把它分成一系列文章。今天是第一篇 - 线程篇。
GIL
Python(特指CPython)的多线程的代码并不能利用多核的优势,而是通过著名的全局解释锁(GIL)来进行处理的。如果是一个计算型的任务,GIL就会让多线程变慢。我们举个计算斐波那契数列的例子:
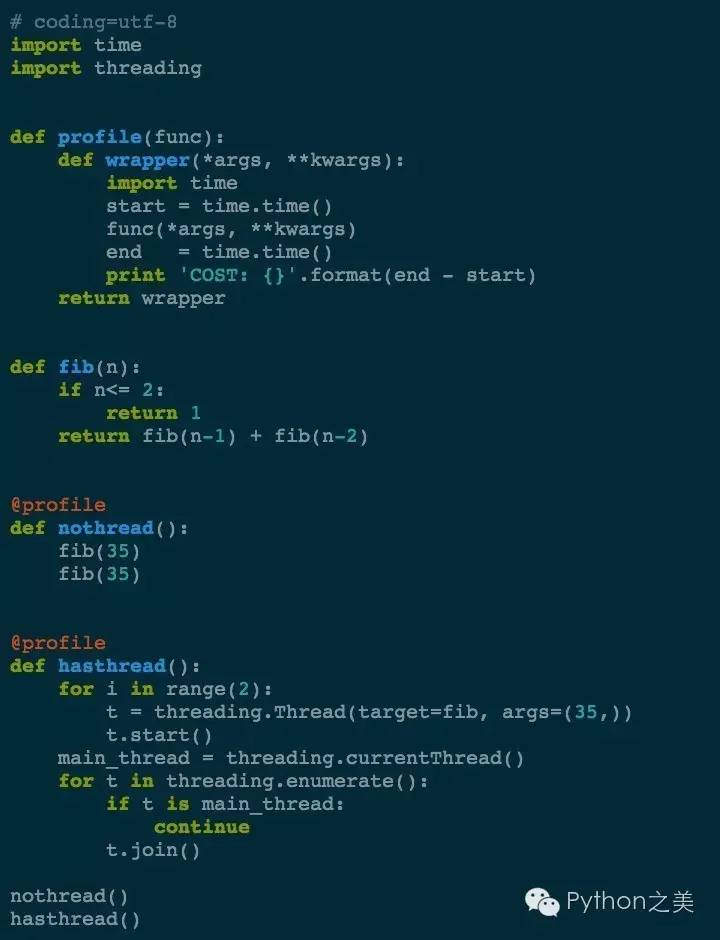 运行的结果你猜猜会怎么样:
运行的结果你猜猜会怎么样:

这种情况还不如不用多线程!
GIL是必须的,这是Python设计的问题:Python解释器是非线程安全的。这意味着当从线程内尝试安全的访问Python对象的时候将有一个全局的强制锁。 在任何时候,仅仅一个单一的线程能够获取Python对象或者C API。每100个字节的Python指令解释器将重新获取锁,这(潜在的)阻塞了I/O操作。因为锁,CPU密集型的代码使用线程库时,不会获得性能的提高。
那是不是由于GIL的存在,多线程库就是个「鸡肋」呢?当然不是。事实上我们平时会接触非常多的和网络通信或者数据输入/输出相关的程序,比如网络爬虫、文本处理等等。这时候由于网络情况和I/O的性能的限制,Python解释器会等待读写数据的函数调用返回,这个时候就可以利用多线程库提高并发效率了。
同步机制
Python线程包含多种同步机制:
1. Semaphore(信号量)
在多线程编程中,为了防止不同的线程同时对一个公用的资源(比如全部变量)进行修改,需要进行同时访问的数量(通常是1)的限制。信号量同步基于内部计数器,每调用一次acquire(),计数器减1;每调用一次release(),计数器加1.当计数器为0时,acquire()调用被阻塞。
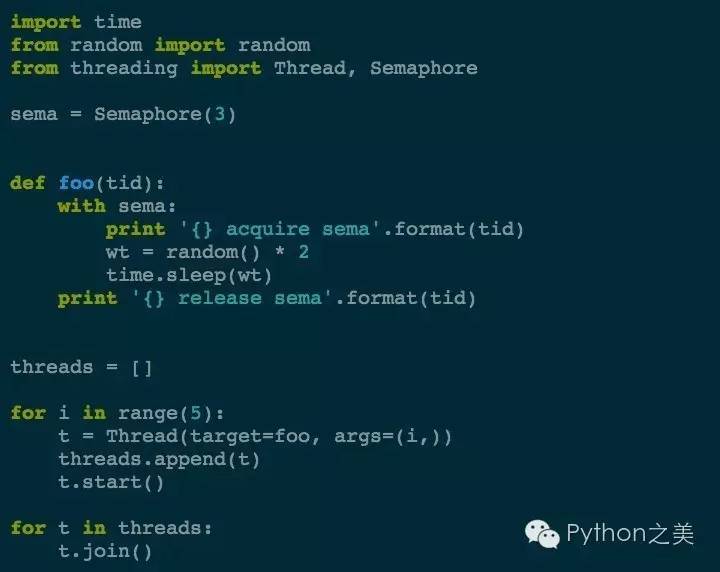 这个例子中,我们限制了同时能访问资源的数量为3。看一下执行的效果:
这个例子中,我们限制了同时能访问资源的数量为3。看一下执行的效果:

2. Lock(锁)
Lock也可以叫做互斥锁,其实相当于信号量为1。我们先看一个不加锁的例子:
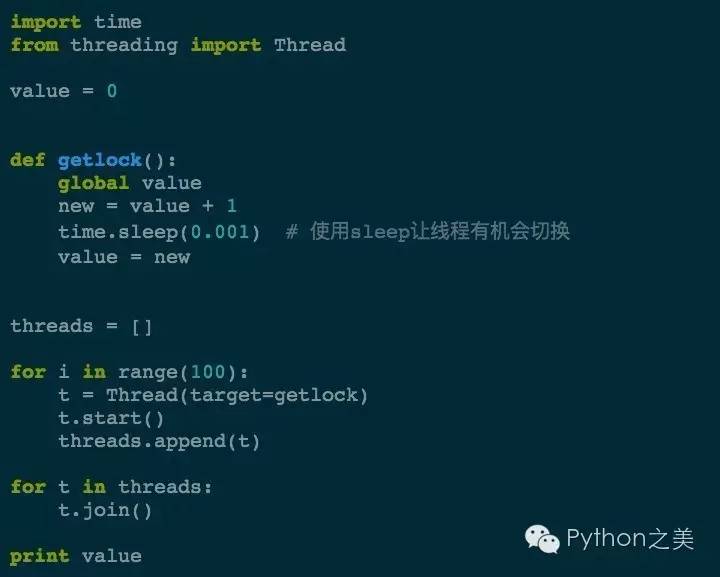 执行一下:
执行一下:
❯ python nolock.py 16
大写的黑人问号。不加锁的情况下,结果会远远的小于100!那我们加上互斥锁再看看:
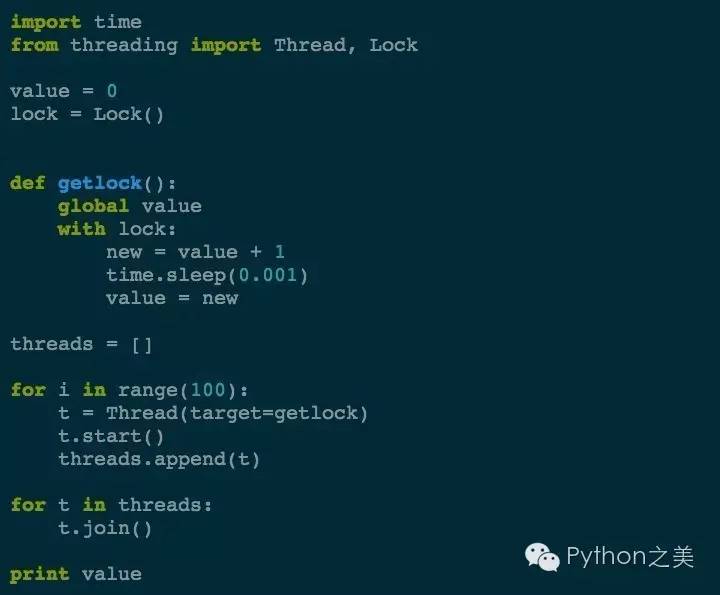 我们对value的自增加了锁,就可以保证了结果了:
我们对value的自增加了锁,就可以保证了结果了:
❯ python lock.py 100
3. RLock(可重入锁)
acquire() 能够不被阻塞的被同一个线程调用多次。但是要注意的是release()需要调用与acquire()相同的次数才能释放锁。
4. Condition(条件)
一个线程等待特定条件,而另一个线程发出特定条件满足的信号。最好说明的例子就是「生产者/消费者」模型:
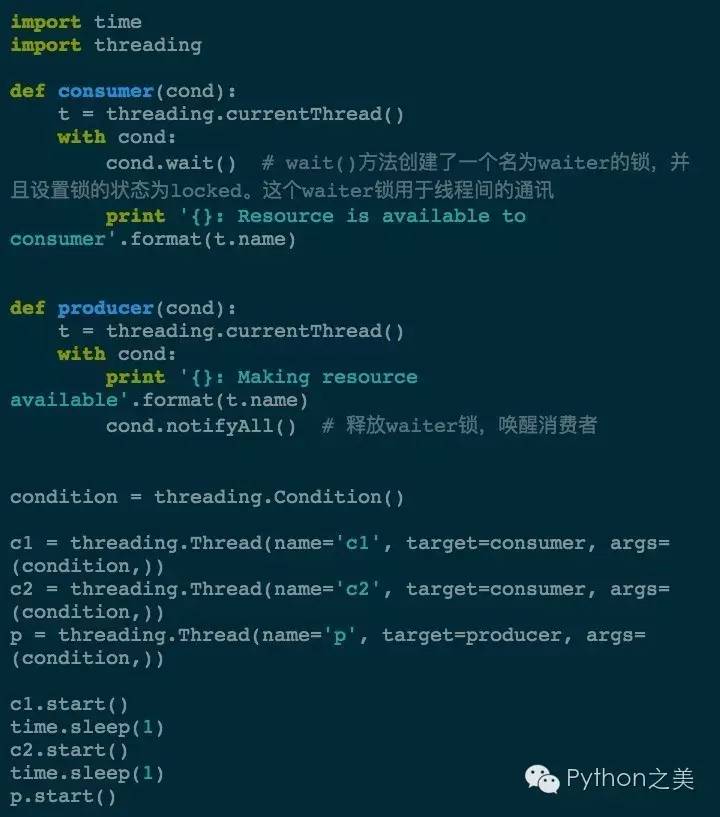 执行一下:
执行一下:
❯ python condition.py p: Making resource available c2: Resource is available to consumer c1: Resource is available to consumer
可以看到生产者发送通知之后,消费者都收到了。
5. Event
一个线程发送/传递事件,另外的线程等待事件的触发。我们同样的用「生产者/消费者」模型的例子:
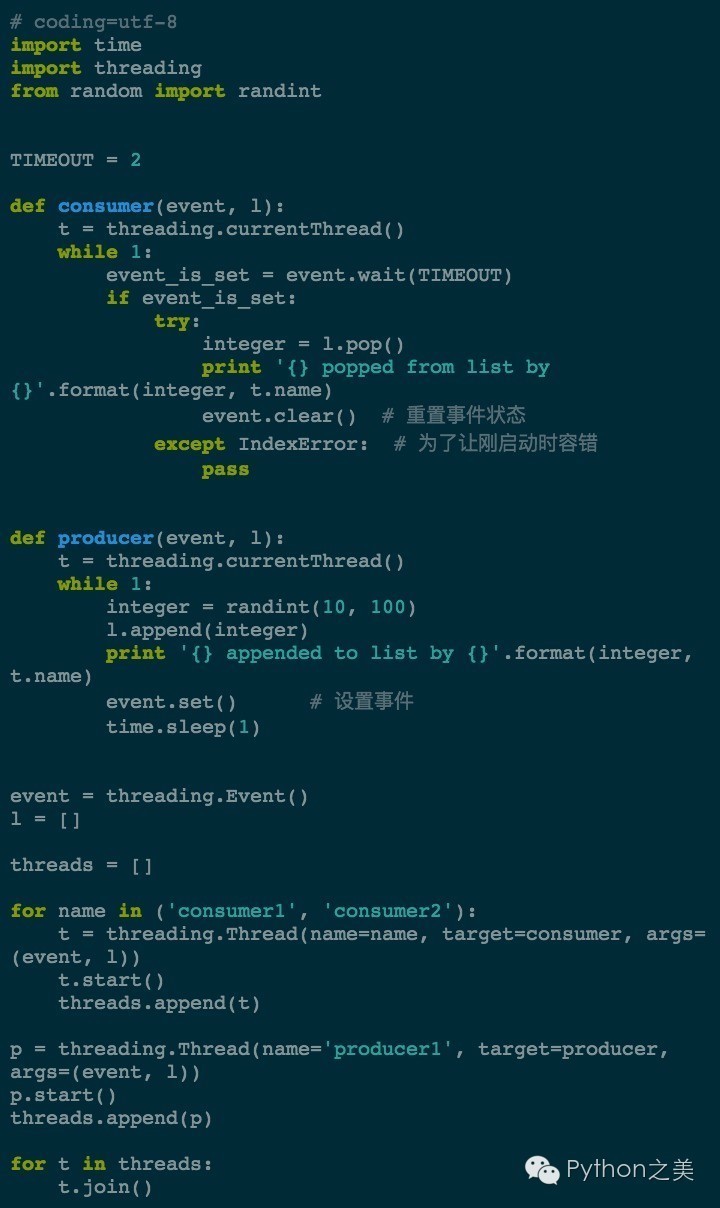 执行的效果是这样的:
执行的效果是这样的:

可以看到事件被2个消费者比较平均的接收并处理了。如果使用了wait方法,线程就会等待我们设置事件,这也有助于保证任务的完成。
6. Queue
队列在并发开发中最常用的。我们借助「生产者/消费者」模式来理解:生产者把生产的「消息」放入队列,消费者从这个队列中对去对应的消息执行。
大家主要关心如下4个方法就好了:
-
put: 向队列中添加一个消息。
-
get: 从队列中删除并返回一个消息。
-
task_done: 当某一项任务完成时调用。
-
join: 阻塞直到所有的项目都被处理完。
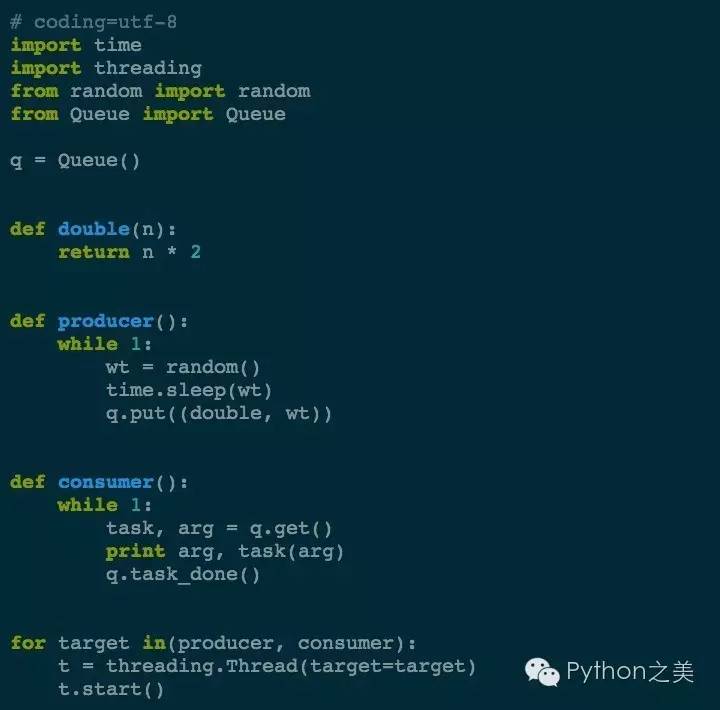 这就是最简化的队列架构。
这就是最简化的队列架构。
Queue模块还自带了PriorityQueue(带有优先级)和LifoQueue(先进先出)2种特殊队列。我们这里展示下线程安全的优先级队列的用法,
PriorityQueue要求我们put的数据的格式是
(priority_number, data)
,我们看看下面的例子:
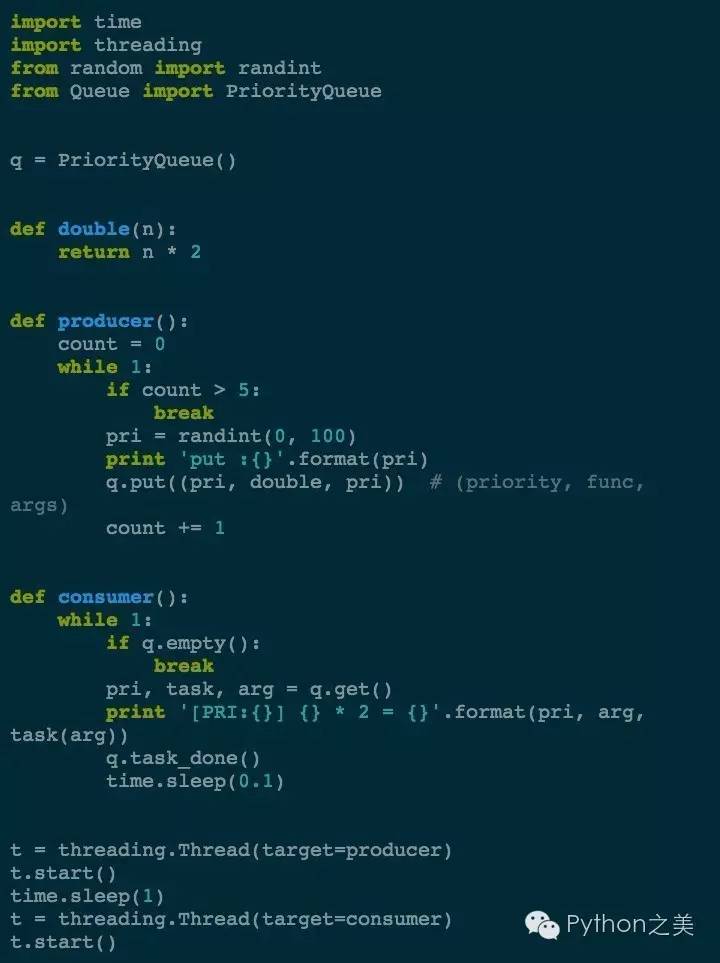 其中消费者是故意让它执行的比生产者慢很多,为了节省篇幅,只随机产生5次随机结果。我们看下执行的效果:
其中消费者是故意让它执行的比生产者慢很多,为了节省篇幅,只随机产生5次随机结果。我们看下执行的效果:
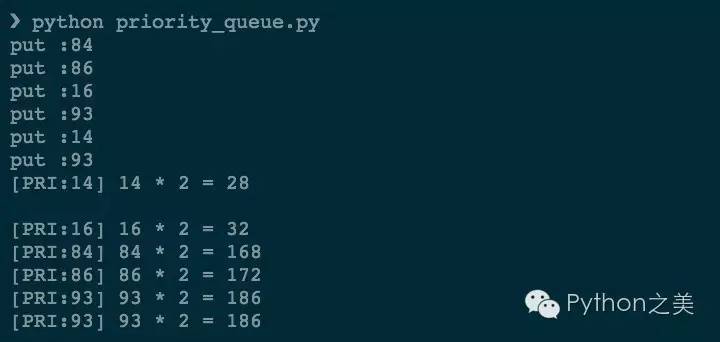
可以看到put时的数字是随机的,但是get的时候先从优先级更高(数字小表示优先级高)开始获取的。
线程池
面向对象开发中,大家知道创建和销毁对象是很费时间的,因为创建一个对象要获取内存资源或者其它更多资源。无节制的创建和销毁线程是一种极大的浪费。那我们可不可以把执行完任务的线程不销毁而重复利用呢?仿佛就是把这些线程放进一个池子,一方面我们可以控制同时工作的线程数量,一方面也避免了创建和销毁产生的开销。
线程池在标准库中其实是有体现的,只是在官方文章中基本没有被提及:
 当然我们也可以自己实现一个:
当然我们也可以自己实现一个:
 执行一下:
执行一下:
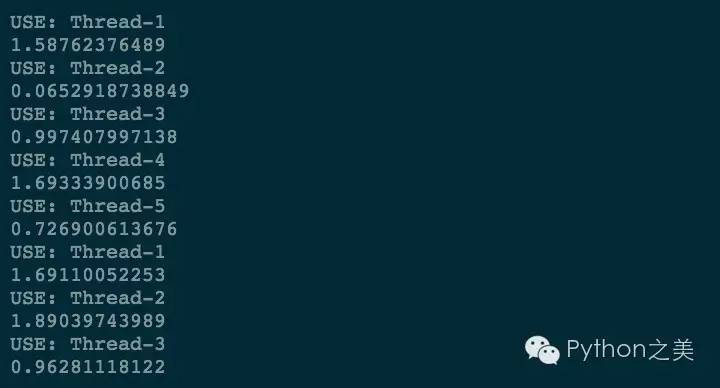 线程池会保证同时提供5个线程工作,而我们有8个待完成的任务,可以看到线程按顺序被循环利用了。
线程池会保证同时提供5个线程工作,而我们有8个待完成的任务,可以看到线程按顺序被循环利用了。
PS:本文全部代码可以在 微信公众号文章代码库项目中找到。
项目地址: https://github.com/dongweiming/mp/tree/master/2016-12-01
也可以长按下面的二维码访问:


正文到此结束
热门推荐









相关文章

近期评论
-
谢谢
-
https://www.newcmy.com/register?aff=HBVX建议您试试草莓云机场,可以流畅观看youtube和tiktok,上reddit/x也没有问题,还有各种ai优化节点。
-
-
-
想购买您这个站,我的联系方式QQ741756694微信同步 能卖联系
-
-
-
-
-
https://www.liuhaihua.cn/archives/40657.html 这篇博客中的图片打不开了
Loading...
![[HBLOG]公众号](https://www.liuhaihua.cn/img/qrcode_gzh.jpg)

